
Published on September 20, 2024 1:13 PM GMT
Introduction
I've spent the last few days going through every glitch token listed in the third SolidGoldMagikarp glitch token post, and was able to find the cause/source of almost every single one. This is the first in a series of posts in which I will explain the behaviors of these glitch tokens, the context in which they appear in the training data, and what they reveal about the internal dynamics of LLMs. If you're unfamiliar with glitch tokens, I highly suggest you read the glitch token archaeology posts first.
My process involved searching through OpenWebText, a recreation of GPT2 training data, and prompting GPT2 to locate the context of the training data.
Previous Context
In their 2023 post, the authors made the following pronouncement in regard to the glitch token ' practition' (token_id: 17629). I took it as a personal challenge.

The first thing I found was that ' practitioner' (32110) and ' practitioners' (24068) were both already tokens in the GPT2 tokenizer. Furthermore, all three tokens also present in the GPT3.5/4 and GPT4o tokenizers, meaning they weren't an artifact of GPT2's training data!
There were only 13 examples of " practition" in OpenWebText.
['urlsf_subset00-928_data.xz', '\nThe WCC is also a prominent supporter and practitioning body for Peace journalism: journalism practice that'], ['urlsf_subset01-45_data.xz', ' what is now the Czech Republic, became a noted practitioneer of lagers, and geology again']['urlsf_subset06-66_data.xz', 'The site relaunched on Wordpress VIP, practitioned by ESPN and 10up, a company']['urlsf_subset07-802_data.xz', ' one possible explanation for the positive association between BDSM practitioning and subjective well-being.”'], ['urlsf_subset09-305_data.xz' , ' that vital personal touch that feudalism asked of its practitioning monarchs. He made wild leaps of']['urlsf_subset11-474_data.xz', ' of the Senators asked “…if a health practitionerr is advising a patient to go on a']['urlsf_subset11-809_data.xz', ' the full range of Buddhist traditions and the diversity of practition-ers today. As Buddhism in the West']['urlsf_subset12-398_data.xz', ' one possible explanation for the positive association between BDSM practitioning and subjective well‐being. Several limitations']['urlsf_subset13-921_data.xz', ' availa ble.\n\nSecondly , LCA practitione rs need to comply with the ISO\n']['urlsf_subset15-258_data.xz', 'en K, et al. Investigation of mindfulness meditation practitiones with voxel-based morphometry']['urlsf_subset15-797_data.xz', ' size effects in statistical pattern recognition: Recommendations for practitioneers. - IEEE Transactions on Pattern Analysis and'['urlsf_subset19-877_data.xz', '\n\nStarting at level 6 , as a mask practitionner , you dive deeper into your ways and']['urlsf_subset20-165_data.xz', ' It’s tought in university, probably practitioned in most of the development shops out there']They were mostly misspellings, as an element of " practitioning", or line breaks artifacts[1].
Experimentation
I examined some other low-frequency tokens in GPT2 and found a few which were substrings of a higher-frequency counterpart. 'ortunately' (4690) also behaved like a glitch token, while higher-frequency subtokens like ' volunte' (7105) didn't.
tokenId | tokenString | tokenFrequency17629 ' practition' 1332110 ' practitioner' 994224068 ' practitioners' 146464690 'ortunately' 146668 'fortunately' 432939955 ' fortunately' 1076831276 'Fortunately' 15667 7105 ' volunte' 3441434 ' volunteering' 1059832730 ' volunteered' 1417613904 ' volunteer' 2003711661 ' volunteers' 202846598 ' behavi' 6546571 'behavior' 729541672 ' behavioural' 772438975 ' behaviours' 941637722 ' behaving' 1264517211 ' behavioral' 1653314301 ' behaviors' 187099172 ' behaviour' 204974069 ' behavior' 20609Helpful Contributions
Others pointed out that this was a result of Byte-Pair Encoding, which builds tokens out of shorter, previously encounter, tokens.
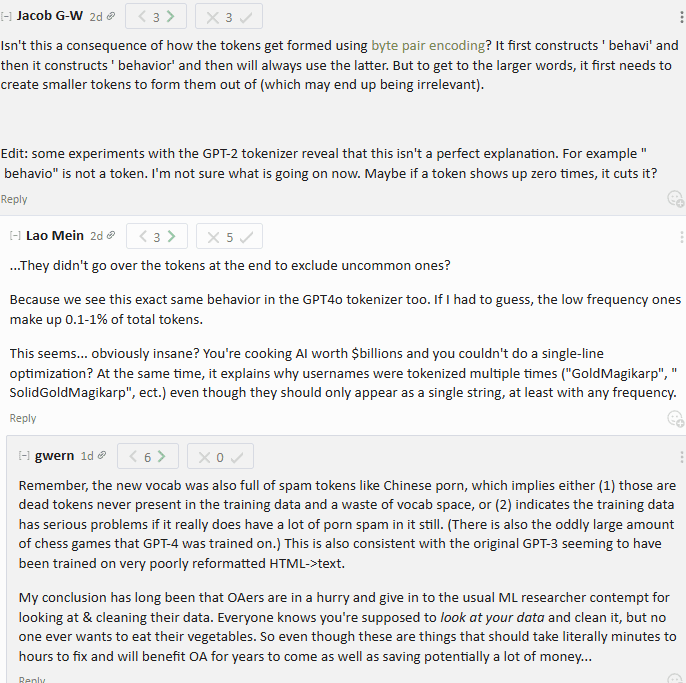
I was very surprised by this, since glitch behavior implies a low frequency in the training data, and identifying and removing them from the tokenizer takes little effort. Gwern thinks the researchers are just that lazy. My overall impression is that glitch tokens are a useful tool to help prevent catastrophic forgetting, but that's for a future post. Even then, I'm doubtful that incorporating low-frequency BSA tokens can improve performance. Maybe they contribute to the spelling miracle in some poorly understood way?
Applications
I'm not sure if this approach is useful for finding glitch tokens in other GPT models. Due to things like misspellings, line breaks and uncommon variants, even tokens rare enough to trigger glitch behavior in GPT2 are likely pushed over the glitchiness threshold in GPT4 and GPT4o.
However, the differences in token ids of substrings can be used to help identify the potential glitchiness of a token with no other knowledge of the model or training data[2]. We know from the mechanisms of BPE encoding that smaller subtokens created before they are merged into larger tokens. However, if a subtoken is never/rarely encountered outside its parent token, we would expect it to have an index close to the parent token, and that's exactly what we observe for many glitch tokens!
For example:
42066 Nitrome 842089 TheNitrome 042090 TheNitromeFan 0Note how close the index of " TheNitrome" (42089) is to " TheNitromeFan"[3] (42090). This indicates 2 things:
- The distribution of these tokens are highly uneven, a tell for glitch tokens[4].The subtokens were relatively rarely seen independently - they're infrequent outside the larger tokens[5], meaning that they will rarely be encountered in the training data due to the greedy tokenizer[6].
Many of the most well-know glitch tokens exhibit this pattern:
42202 GoldMagikarp 043453 SolidGoldMagikarp 036481 ertodd 12537444 petertodd 2940219 oreAnd 340240 oreAndOnline 040241 InstoreAndOnline 040242 BuyableInstoreAndOnline 1The token ids suggest "oreAndOnline" and "InstoreAndOnline " virtually never appears apart from "BuyableInstoreAndOnline". However, the small gap between "oreAnd" and the other tokens implies that "oreAnd" was occasionally present in the data as something else - and that's exactly what we observe! It appears as parts of various functions, generally in something like "IgnoreAnd..."[7].
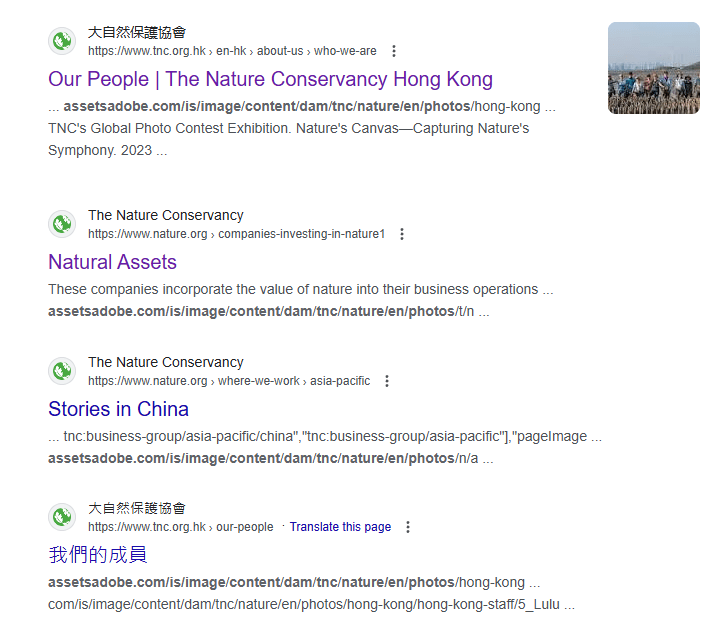
['urlsf_subset03-643_data.xz', "voltageget_by_counts_value() whatsoever. That's what …_IgnoreAndReturn() functions are for (generated by CMock): void test_voltage_get (" '56. adc_handlervoltageget_by_counts_value_IgnoreAndReturn ( 456 ) ; //-- actually call the function being tested, that should perform //' 'ADC_CH_CNT ; channel ++ ) { adc_handlerctor_IgnoreAndReturn ( ADC_HANDLER_RES__OK ) ; } //-- before each test']['urlsf_subset05-264_data.xz', ' guts and gloryI\'m tryin to hear B. I. G. And some cuts from NoreAnd you keep talkin over the beat like Clue ("Do you remember?").. Go find']['urlsf_subset11-699_data.xz', 'ax push eax call dword ptr[ebp + aShellExecuteA] // RestoreAndExit mov esp, [ebp + SaveESP] popfd popad jmp d']Nearby (by token_id) tokens can also be used to infer the context of hard-to-locate tokens. For example, "natureconservancy" (41380) and "assetsadobe" (41382) have close token_ids. "assetadobe" also continues as something like
"assetsadobe.com/is/image/content/dam/tnc/nature/en/photos""assetsadobe.com/is/image/content/dam/tnc/nature/en/photos/tnc_92425982.jpg?crop=0,0,5120,3740&wid=800&hei=600"'assetsadobe.com/is/image/content/dam/tnc/nature/en/photos/tnc_91708743_4000x2200.jpg?crop=900,0,2200,2200&wid=150&hei'~100% of the time. It looks both tokens were part of nature.org scrapes.
Similarly, "GoldMagikarp" (42202) and "TheNitromeFan" (42090) are around Reddit political discussion and numerical tokens like
['42224', '411'],['42215', ' 412'], ['42277', ' fundamentalist'], ['42318', ' Racial'], ['42315', 'Mario']This suggests it's part of a Reddit scrape. When prompted with counting subreddit names, the continuation will assume it's a Reddit response. Note the "\n\n" (628), often times referred to as "Reddit spacing" due to its frequency on that site.
TheNitromeFan\n\nI am not an expert on the history of this subreddit but I have read the TheNitromeFan\n\nI'm a huge fan of the "I don't care" meme. I SolidGoldMagikarp\n\nThe first time I heard of the concept of an "alt-right" was SolidGoldMagikarp\n\nI have a few friends who love to watch porn, and I have a fewInterestingly, " SolidGoldMagikarp" (43453) occurs quite a bit away from "GoldMagikarp" (42202). My theory for this is that Reddit posts are often in the following format:
u/redditusernameredditusername•2d ago<actual post>and "u/SolidGoldMagikarp" tokenizes as:
[[84, 14, 46933, 42202], ['u', '/', 'Solid', 'GoldMagikarp']]It's possible only enough of his post were included to get "GoldMagikarp" as a token for a while. This was corrected after more of his posts were read later, and the full " SolidGoldMagikarp" token was included in the final vocabulary[8].
My next post will be about why an earlier hypothesis that many glitch tokens were excluded from training data is unlikely to be true for most glitch tokens, and the role that glitch tokens play in improving LLM performance.
If you're curious about a particular glitch token, feel free to comment.
Addendum
There are two tokens I still don't have a source for. Unlike almost every other glitch token, they exhibit spontaneous glitch behavior, even when they are the only prompt.
25658 '?????-' 331666 '?????-?????-' 0Completions for "?????-":
?????-The first thing that struck me was how many people were there. It's a?????-;. (2)A person is guilty of a crime, punishable by imprisonment?????-;)<(;;<;;'<;;'<;;'<;;'<?????-;-;-;-;-;-;-;-;-?????-;)I'm not sure I'm going to be as successful with this as?????-"I don't know if I should be proud or sad.""?????-"What's wrong?" I asked him, as he was sitting on a bench?????-------?????-;. -. . - -. . -?????-------?????-;)I'm going to be very, very brief.I don?????--.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-?????-"You're not the one I was hoping to see!"
- ^
" practitionerr" is tokenized into:
[[17629, 8056], [' practition', 'err']]
instead of [[32110, 81], [' practitioner', 'r']].
There's something I don't understand here - I thought BPE tokenization was maximally greedy! Or does that only apply to tokenizer training, and something else happens when a tokenizer is ran on text?
- ^
I can probably find glitch tokens in something the size of GPT2 just with access to the tokenizer.
- ^
"Nitrome" is also the name of a video game developer, so it appeared in other places in the dataset, and thus was tokenized slightly sooner.
- ^
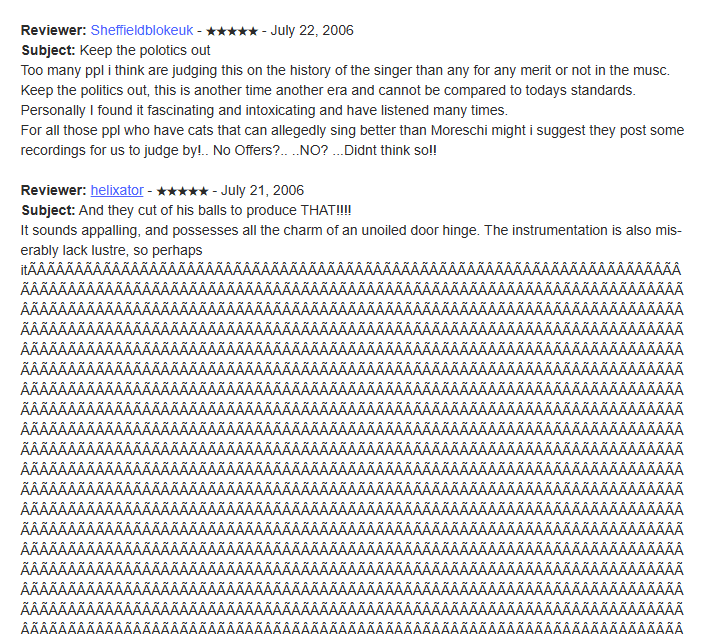
for example, literally all instances of "ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ" (token_id: 35496)(that's 64 characters) in OpenWebText are from archive.org. There are 9468 instances in total, not counting shorter variants with 1, 2, 4, 8, 16, and 32 characters. The following was the first example I found.
This goes on for 200,000 characters on this page alone.
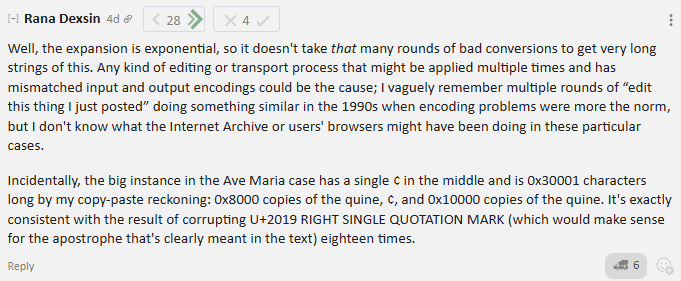
@Rana Dexsin wrote the single best answer I've ever seen on the internet.
Which links to this.
There were no hidden characters in these sequences.
- ^
The second one isn't always true; many glitch tokens exhibiting such patterns may be from alternate tokenizations. For example, "EStream" almost always continues as "EStreamControl...", distinct from "EStreamFrame". Both "EStreamFrame" and "EStream" are part of many functions in the enums submodule of the Python Stream library.
- ^
If "
oreAndOnline" is only present as part of "BuyableInstoreAndOnline", the model will never see the "oreAndOnline" token. - ^
For example, the CMock function "_IgnoreAndReturn()". CMock is used to measure the performance of C++ functions, and it makes sense that some CMock logs were included in the training data.
- ^
I do find it interesting that I haven't been able to induce counting behavior in GPT2. This may be related to so many multi-digit numbers having their own tokenizations - "411" (42224), "412"(42215), and so on, and that's just not a pattern GPT2 can figure out. It's possible that the r/Counting subreddit is a major contributor in why GPT2 is so bad at math!
I then looked around at GPT4 and GPT4o tokenizers. To my shock and horror, they still include multi-digit numbers as tokens. "693" (48779) being an example in GPT4o.
This is... what? Why? How can this possibly be a good idea in an LLM used for math and coding applications? It would certainly explain why GPT4/GPT4o is so bad at math.


Discuss
