


Music generation has evolved significantly, integrating vocal and instrumental tracks into cohesive compositions. Pioneering works like Jukebox demonstrated end-to-end generation of vocal music, matching input lyrics, artist styles, and genres. AI-driven applications now enable on-demand creation using natural language prompts, making music generation more accessible. The field encompasses symbolic domain and audio domain generation, each with distinct methodologies. Symbolic approaches, while beneficial for melody generation, lack phoneme-and note-aligned information crucial for vocal music and audio rendering.
Research has explored lead sheet tokens, inspired by jazz musicians to enhance interpretability in music generation. Task-specific studies have investigated steering music audio generation through musically interpretable conditions such as harmony, dynamics, and rhythm. These advancements have addressed both technical challenges and artistic needs, laying a robust foundation for frameworks like Seed-Music. The progression from separate track generation to integrated systems marks a significant shift in music creation and experience, paving the way for more sophisticated and user-friendly music generation tools.
Seed-Music emerges as a comprehensive framework for high-quality music generation, addressing both creative and technical challenges. It combines controlled generation and post-production editing, catering to diverse user needs. The framework acknowledges the complexities of music annotation, cultural influences on aesthetics, and the technical requirements for the simultaneous generation of multiple musical components. Emphasizing user-centric design, Seed-Music accommodates varying levels of expertise and specific needs. The modular structure, comprising representation learning, generation, and rendering modules, provides flexibility in handling different music generation and editing tasks, adapting to various user inputs and preferences.
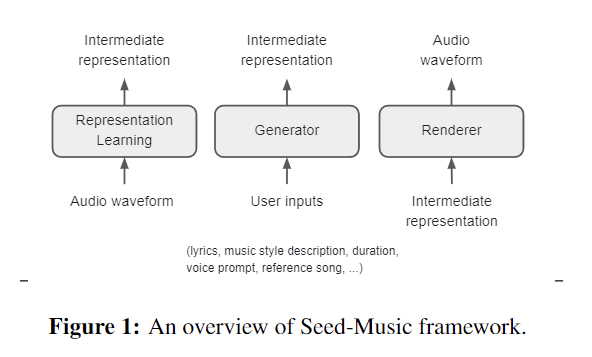
The Seed-Music methodology employs three core intermediate representations: audio tokens, symbolic representations, and vocoder latents. Audio tokens efficiently encode semantic and acoustic information but lack interpretability. Symbolic representations allow direct user modifications but depend heavily on the Renderer for acoustic nuances. Vocoder latents capture detailed information but may encode excessive acoustic detail. The framework incorporates reward models based on musical attributes and user feedback, enhancing output alignment with user preferences. This approach addresses the complexities of music signals and evaluation challenges.
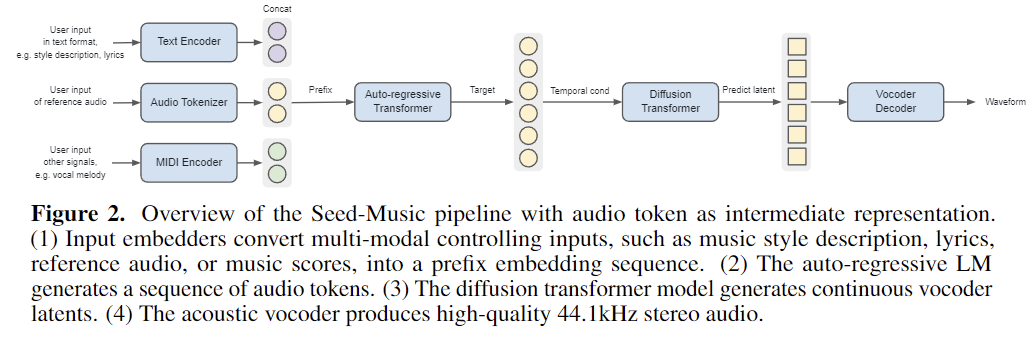
The system supports controlled music generation through multi-modal inputs, including style descriptions, audio references, musical scores, and voice prompts. It also features post production editing tools for modifying lyrics and vocal melodies directly in the generated audio. These components collectively create a versatile music generation system that provides high-quality output with fine-grained control. The methodology’s sophisticated approach caters to diverse user needs, from novices to professionals, by combining various representations, models, and interaction tools to facilitate dynamic and user-friendly music creation and editing.
Results from the Seed-Music framework demonstrate its effectiveness in generating high-quality music aligned with user specifications. The unified structure, comprising representation learning, generation, and rendering modules, facilitates controlled music generation and postproduction editing. While traditional performance metrics prove inadequate for assessing musicality, the system’s success is evident through subjective evaluations and demo audio examples. The framework’s ability to edit and manipulate recorded music while preserving semantics offers significant advantages for music industry professionals. Despite showing promise, further exploration into reinforcement learning methods is needed to enhance output alignment and musicality. Future developments, including stem-based generation and editing workflows, hold potential for advancing creative processes in music production.
In conclusion, Seed-Music emerges as a comprehensive framework for music generation, utilizing three intermediate representations to support diverse workflows. The system generates high-quality vocal music from various inputs, including language descriptions, audio references, and music scores. By lowering barriers to artistic creation, it empowers both novices and professionals, integrating text-to-music pipelines with zero-shot singing voice conversion. The framework envisions new artistic mediums responsive to multiple conditioning signals. Lead sheet tokens aim to become a standard for music language models, facilitating professional integration. Future developments in stem-based generation and editing workflows hold promise for enhancing music production processes, potentially revolutionizing creative practices in the music industry.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

The post Seed-Music: A Comprehensive AI Framework for Enhanced Music Generation and Editing with Controlled Artistic Expression and Multi-Modal Inputs appeared first on MarkTechPost.
