


Large language models (LLMs) have seen remarkable success in natural language processing (NLP). Large-scale deep learning models, especially transformer-based architectures, have grown exponentially in size and complexity, reaching billions to trillions of parameters. However, they pose major challenges in computational resources and memory usage. Even advanced GPUs struggle to handle models with trillions of parameters, limiting accessibility for many researchers because training and managing such large-scale models need significant adjustments and high-end computing resources. So, developing frameworks, libraries, and techniques to overcome these challenges has become essential.
Recent studies have reviewed language models, optimization techniques, and acceleration methods for large-scale deep-learning models and LLMs. The studies highlighted model comparisons, optimization challenges, pre-training, adaptation tuning, utilization, and capacity evaluation. Many methods have been developed to achieve comparable accuracy with reduced training costs like optimized algorithms, distributed architectures, and hardware acceleration. These reviews provide valuable insights for researchers seeking optimal language models and guide future developments toward more sustainable and efficient LLMs. Moreover, other methods have been explored for utilizing pre-trained language models in NLP tasks, contributing to the ongoing advancements in the field.
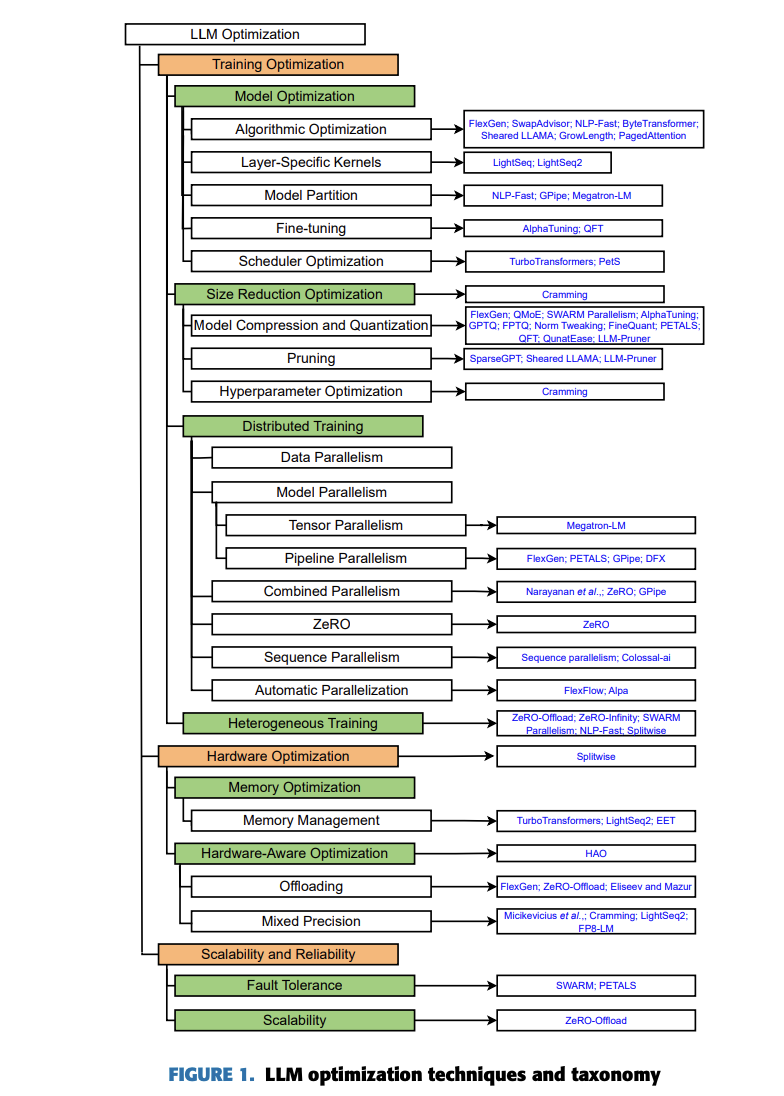
Researchers from Obuda University, Budapest, Hungary; J. Selye University, Komarno, Slovakia; and the Institute for Computer Science and Control (SZTAKI), Hungarian Research Network (HUN-REN), Budapest, Hungary have presented a systematic literature review (SLR) that analyzes 65 publications from 2017 to December 2023. The SLR focuses on optimizing and accelerating LLMs without sacrificing accuracy. This paper follows the PRISMA approach to provide an overview of language modeling development and explores commonly used frameworks and libraries. It introduces a taxonomy for improving LLMs based on three classes: training, inference, and system serving. Researchers investigated recent optimization and acceleration strategies, including training optimization, hardware optimization, and scalability. They also introduced two case studies to demonstrate practical approaches to address LLM resource limitations while maintaining performance.
The SLR utilizes a comprehensive search strategy using various digital libraries, databases, and AI-powered tools. The search, conducted until May 25th, 2024, focused on studies related to language modeling, particularly LLM optimization and acceleration. Moreover, ResearchRabbit and Rayyan AI tools facilitated data collection and study selection. The selection process contains strict inclusion criteria, focusing on large-scale language modeling techniques, including transformer-based models. A two-stage screening process, (a) initial screening based on eligibility and (b) inclusion criteria, was implemented. The Rayyan platform’s “compute rating” function assisted in the final selection, with authors double-checking excluded studies to ensure accuracy.
LLM training frameworks and libraries face major challenges due to the complexity and size of the models. Distributed training frameworks like Megatron-LM and CoLLiE tackle these issues by splitting models across multiple GPUs for parallel processing. Efficiency and speed enhancement are achieved through system-level optimizations in frameworks like LightSeq2 and ByteTransformer, which improve GPU utilization and reduce memory usage. Moreover, Memory management is an important factor that can be addressed with CoLLiE which uses 3D parallelism and distributes memory efficiently across training machines and GPUs.
These five key frameworks and libraries help overcome LLM training limitations:
- GPipe successfully trains large multilingual transformer models, outperforming individual smaller models. ByteTransformer demonstrates superior performance for BERT-like transformers across various benchmarks.Megatron-LM enables the training of billion-parameter LLMs, achieving state-of-the-art results on NLP tasks with high throughput. LightSeq2 significantly accelerates transformer model training, enhancing performance by up to 308%. CoLLiE introduces collaborative LLM training, improving efficiency and effectiveness for large models like LLaMA-65B, without compromising overall performance.
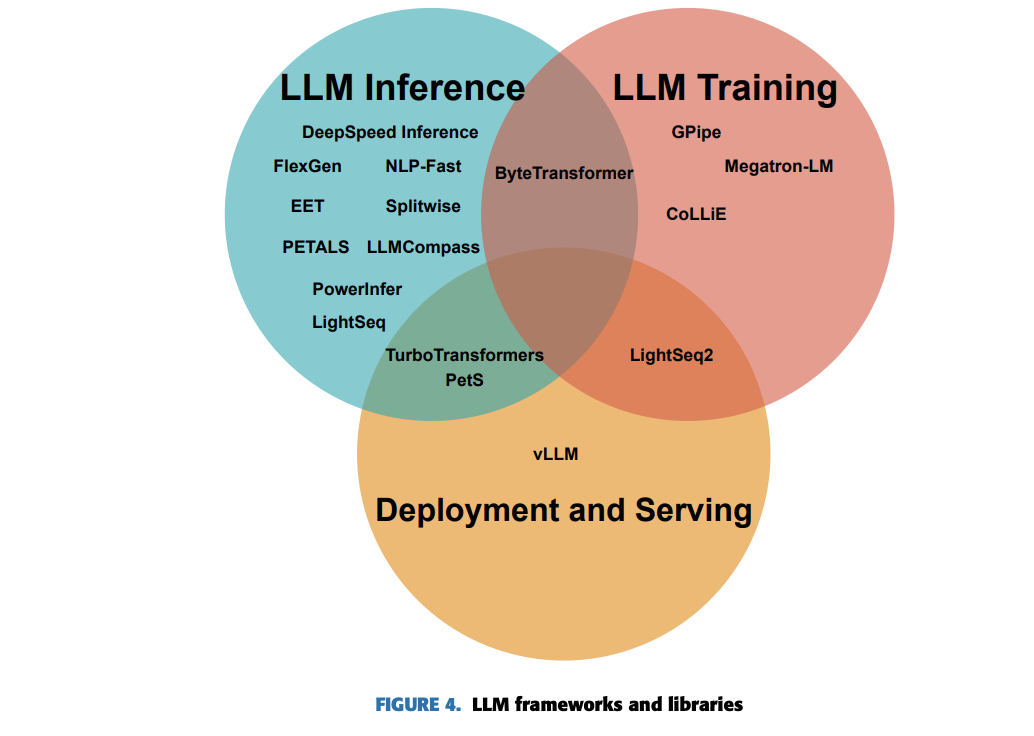
Now, talking about LLM Inference Frameworks and Libraries, the major challenges faced are computational expenses, resource constraints, the requirement of balance speed, accuracy, and resource utilization. Hardware specialization, resource optimization, algorithmic improvements, and distributed inference are the crucial findings to address these challenges. Frameworks like Splitwise separate compute-intensive and memory-intensive phases onto specialized hardware, and FlexGen optimizes resource usage across CPU, GPU, and disk. Moreover, libraries like EET and LightSeq help to accelerate GPU inference through custom algorithms and memory management. These advancements show significant performance, with frameworks like DeepSpeed Inference and FlexGen to gain throughput increases and latency reductions.
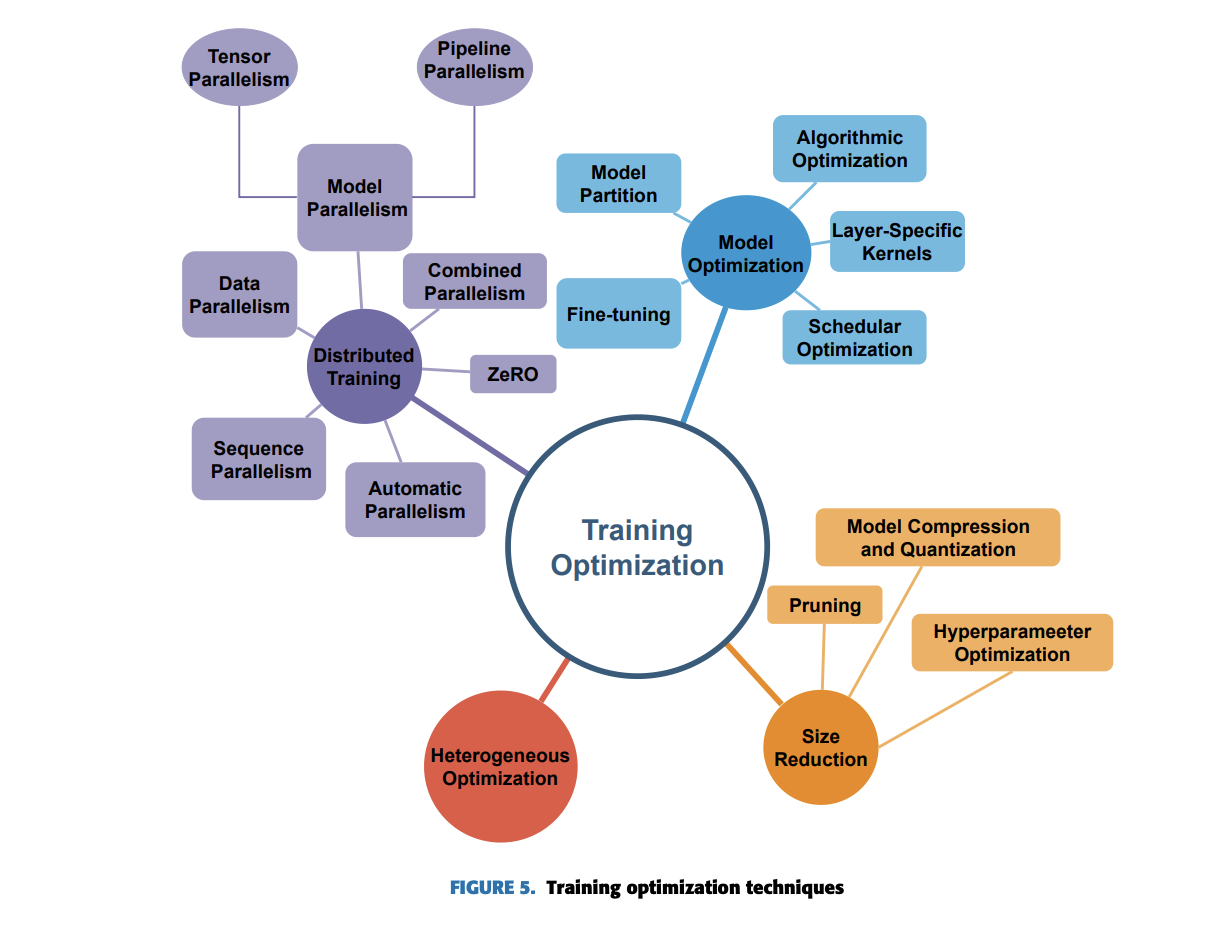
Large language models (LLMs) face significant challenges during training optimization. It includes (a) resource constraints that limit their training and deployment on single devices due to high memory and computational needs, (b) balancing efficiency and accuracy between efficient resource utilization and maintaining model performance, (c) memory bottlenecks when distributing LMs across devices, (d) communication overhead during data exchange that can slow training, (e) hardware heterogeneity that complicates efficient utilization of diverse devices, and (f) scalability limitation hindered by memory and communication constraints.
To overcome these challenges, diverse optimization techniques for LLMs have been developed:
- Algorithmic: Techniques like FlexGen enhance efficiency through optimized computations and specialized hardware kernels. Model partitioning: Techniques like GPipe allow processing across multiple devices, even with limited memory. Fine-tuning for efficiency: Techniques like AlphaTuning and LoRA enable fine-tuning large models on limited memory by reducing the number of adjustmentable parameters.Scheduler optimization: Techniques like TurboTransformers improve response throughput and task execution on GPUs.
Other optimizations include size reduction optimization, Parallelism strategies, Memory optimization, Heterogeneous optimization, and Automatic parallelism:
While the SLR on large language model optimization techniques is thorough, it has some limitations. The search strategy may have missed relevant studies that used different terminologies. Moreover, the limited database coverage has resulted in overlooking significant research. These factors might impact the review’s completeness, especially in the historical context and the latest advancements.
In this paper, researchers introduced a systematic literature review (SLR) that analyzes 65 publications from 2017 to December 2023, following the PRISMA approach, and examined optimization and acceleration techniques for LLMs. It identified challenges in training, inference, and system serving for billion or trillion parameter LLMs. The proposed taxonomy provides a clear guide for researchers to navigate various optimization strategies. The review of libraries and frameworks supports efficient LLM training and deployment, and two case studies demonstrate practical approaches to optimize model training and enhance inference efficiency. Although recent advancements are promising, the study emphasizes the need for future research to realize the potential of LLM optimization techniques fully.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

The post A Systematic Literature Review: Optimization and Acceleration Techniques for LLMs appeared first on MarkTechPost.
