


In deep learning, neural network optimization has long been a crucial area of focus. Training large models like transformers and convolutional networks requires significant computational resources and time. Researchers have been exploring advanced optimization techniques to make this process more efficient. Traditionally, adaptive optimizers such as Adam have been used to speed training by adjusting network parameters through gradient descent. However, these methods still require many iterations, and while they are highly effective in fine-tuning parameters, the overall process remains time-consuming for large-scale models. Optimizing the training process is critical for deploying AI applications more quickly and efficiently.
One of the central challenges in this field is the extended time needed to train complex neural networks. Although optimizers like Adam perform parameter updates iteratively to minimize errors gradually, the sheer size of models, especially in tasks like natural language processing (NLP) and computer vision, leads to long training cycles. This delay slows down the development and deployment of AI technologies in real-world settings where rapid turnaround is essential. The computational demands increase significantly as models grow, necessitating solutions that optimize performance and reduce training time without sacrificing accuracy or stability.
The current methods to address these challenges include the widely used Adam Optimizer and Learning to Optimize (L2O). Adam, an adaptive method, adjusts parameters based on their past gradients, reducing oscillations and improving convergence. L2O, on the other hand, trains a neural network to optimize other networks, which speeds up training. While both techniques have been revolutionary, they come with their limitations. While effective, Adam’s step-by-step nature still leaves room for improvement in speed. L2O, despite offering faster optimization cycles, can be computationally expensive and unstable, requiring frequent updates and careful tuning to avoid destabilizing the training process.
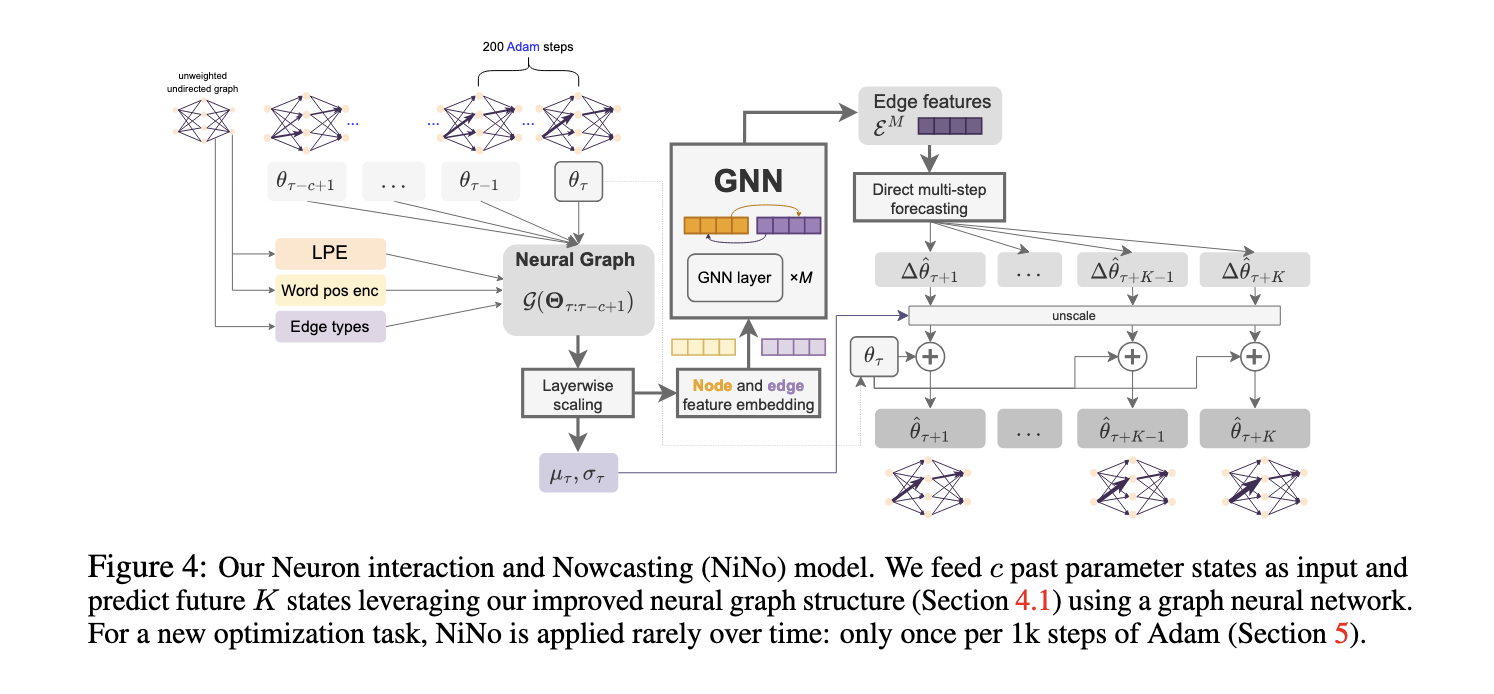
Researchers from Samsung’s SAIT AI Lab, Concordia University, Université de Montréal, and Mila have introduced a novel approach known as Neuron Interaction and Nowcasting (NINO) networks. This method aims to significantly reduce training time by predicting the future state of network parameters. Rather than applying an optimization step at every iteration, as with traditional methods, NINO employs a learnable function to predict future parameter updates periodically. By integrating neural graphs—which capture the relationships and interactions between neurons within layers—NINO can make rare yet highly accurate predictions. This periodic approach reduces the computational load while maintaining accuracy, particularly in complex architectures like transformers.
At the core of the NINO methodology lies its ability to leverage neuron connectivity through graph neural networks (GNNs). Traditional optimizers like Adam treat parameter updates independently without considering the interactions between neurons. NINO, however, uses neural graphs to model these interactions, making predictions about future network parameters in a way that reflects the network’s inherent structure. The researchers built on the Weight Nowcaster Networks (WNN) method but improved it by incorporating neuron interaction modeling. They conditioned NINO to predict parameter changes for the near and distant future. This adaptability allows NINO to be applied at different stages of training without requiring constant retraining, making it suitable for various neural architectures, including vision and language tasks. The model can efficiently learn how network parameters evolve by using supervised learning from training trajectories across multiple tasks, enabling faster convergence.
The NINO network significantly outperformed existing methods in various experiments, particularly in vision and language tasks. For instance, when tested on multiple datasets, including CIFAR-10, FashionMNIST, and language modeling tasks, NINO reduced the number of optimization steps by as much as 50%. In one experiment on a language task, the baseline Adam optimizer required 23,500 steps to reach the target perplexity, while NINO achieved the same performance in just 11,500 steps. Similarly, in a vision task with convolutional neural networks, NINO reduced the steps from 8,606 to 4,582, representing a 46.8% reduction in training time. This reduction translates into faster training and significant savings in computational resources. The researchers demonstrated that NINO performs well not only on in-distribution tasks, where the model has been trained but also on out-of-distribution tasks, where it generalizes better than existing methods like WNN and L2O.
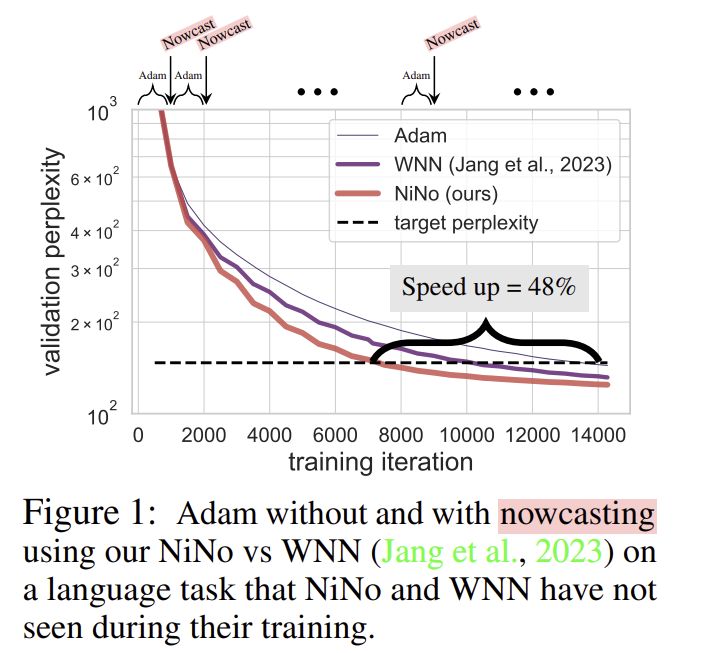
NINO’s performance improvements are particularly noteworthy in tasks involving large neural networks. The researchers tested the model on transformers with 6 layers and 384 hidden units, significantly larger than those seen during training. Despite these challenges, NINO achieved a 40% reduction in training time, demonstrating its scalability. The method’s ability to generalize across different architectures and datasets without retraining makes it an appealing solution for speeding up training in diverse AI applications.
In conclusion, the research team’s introduction of NINO represents a significant advancement in neural network optimization. By leveraging neural graphs and GNNs to model neuron interactions, NINO offers a robust and scalable solution that addresses the critical issue of long training times. The results highlight that this method can substantially reduce the number of optimization steps while maintaining or improving performance. This advancement speeds up the training process and opens the door for faster AI model deployment across various domains.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

The post NiNo: A Novel Machine Learning Approach to Accelerate Neural Network Training through Neuron Interaction and Nowcasting appeared first on MarkTechPost.
