
来源:雪球App,作者: 闷得而蜜,(https://xueqiu.com/5672579962/304802687)
中秋假期,AI最热两话题:1、OpenAI o1发布及Altman现身解读;2、Ayar Labs 的CEO Wade彻底否定铜缆互联技术。
这两个问题,其实属于同一个问题,2由1而产生、成立。
Neural Network到GPT的范式改变
大家都知道2023年初,OpenAI GPT4发布后,AI迅速从神经网络架构,迁移到Transformer算法框架,创造了“蛮力出奇迹”的Scaling-Law法则。Transformer范式对算力最大的变化,是从二维平面(scale-out)扩展到三维立体(scale-out + scale-up)。
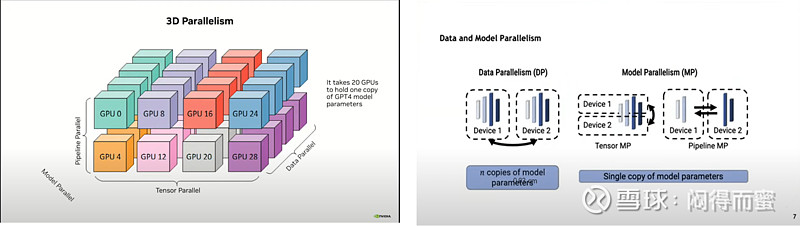
英伟达迎来巨大的历史机遇,市值从几千亿美金上涨到三万亿美金。A股也发扬无中生有的独步天下的本领,很多个股鸡犬升天,迅速攀升5~10倍,不过到现在,绝大部分都从哪里来回哪里去了。只剩下沪电股份、中际旭创、新易盛等货真价实的少数还保持坚挺。
这一轮范式的改变,来得突然,AI算力基建并没有做好充足的准备,仓促应战,整个架构只是在做一些简单的放大。具体来说,英伟达的A100、H100、B100这三个系列的GPU,大体上,都还是在延长线上惯性膨胀。产业链下游也围绕PCB、光模块、铜缆、液冷散热,等传统几大件在耕耘,缺少新意。
但是,这种做法造成的问题也越来越突出:剪刀差持续扩大。
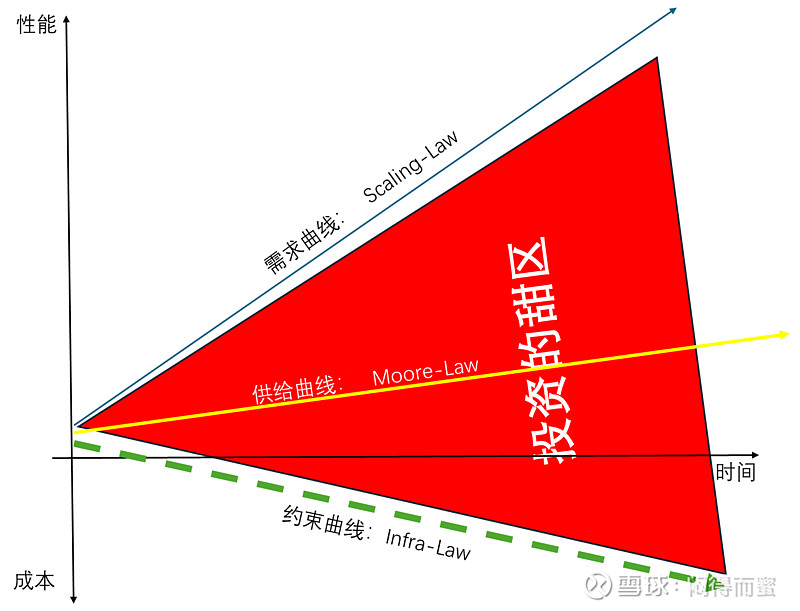
用更直白的话来表达:需求以x10的速度在蹦跑,而供应只能以x2的速度追赶,同时,基建反而以一倍的速度在拖拽,并且AI还没有实现商业变现,导致AI算力投资的负担越来越沉重。对AI算力架构进行大幅度变革的呼声越来越高。
OpenAI o1开辟的新范式
网上有很多解读o1新模型的文章,太专业,能看懂的人不多。看完后很难跟自己应该如何投资联系起来,更有甚者,误导方向。大家都听说过,scaling-law有三个核心要素:数据量、参数量、算力,并且,这三个要素要同步增长,才能获得更大的收益。
但是,可获得的数据越来越少,参数量持续军备竞赛也难以为继,怎么办? o1给大家打开了一扇窗户:通过增加算力,可以弥补数据量和参数量的不足。具体的做法,就是显著增加推理的算力开销,由推理来产生更多的中间数据,回馈到大模型,不停地refine模型效果。这种做法跟人的成长类似:学习->受到激励(表扬或者惩罚)->进步或者淘汰,就是达尔文的自然选择。
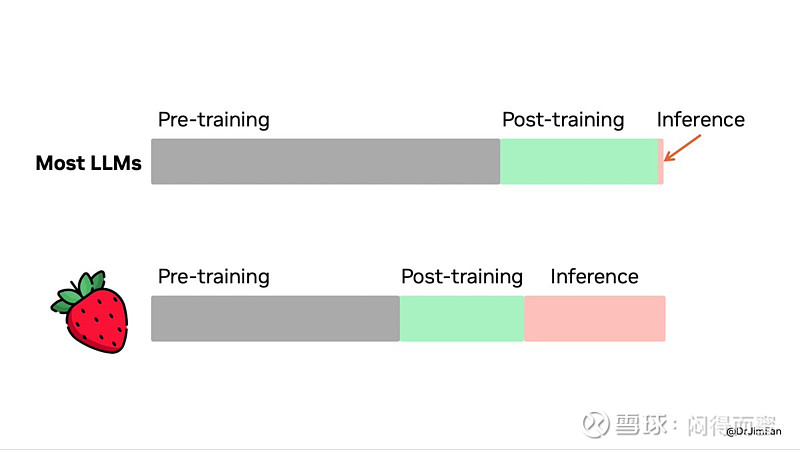
这种算法,会产生海量的machine<->machine交换的需求。

又一个巨大的新AI算力范式诞生了。在这个新范式里,算力特征:
1、吞吐量、交互效率(scale-up),10倍级别提升;
2、成本,要10倍级别的下降;
GPT4,包括4o,算力开销都处于Batch、Human Machine这两个层面,所以H100、B200、GB200 NVL72这些AI集群系统,运行良好。而到了o1这类算法框架,Machine to Machine的交互会异常频繁(靠大量推理结果的相互竞争,来优胜劣汰),算力需求就进化到了第三个层次。内存语义的集群规模会扩大至少10倍以上,互联技术就会发生天翻地覆的变化。刚好在o1发布之时,Ayar Labs就前瞻性地给出了一个概括图表:
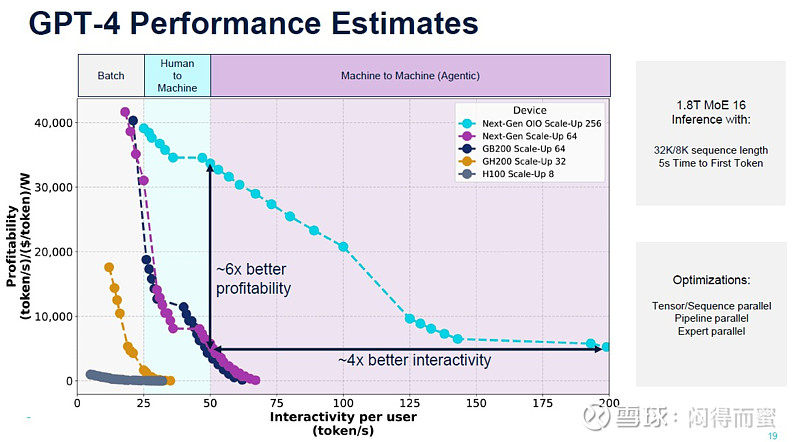
能够同时满足此需求的互联技术,只有光进铜退(CPO 、OIO)。原预计铜缆(沃尔核材、神宇股份)可能还有2~3年生命周期,o1发布后,铜缆能够维持一年生命周期就很了不起。
新范式下,Optical I/O是纯一个增量市场,爆发速度最大(至少40倍于光模块),但不会去抢占光模块(中际旭创、新易盛)的传统空间。光模块大体上会回退到2022年的状态,主要面向Cloud DC的传统领地。而AI Cluster内部,则被CPO(Scale-out)和OIO(Scale-up)主宰。
至于PCB(沪电股份)、液冷(英维克)、整机代工(工业富联)这类行业β型的产品,情况有些微妙,可能需要等到英伟达的Rubin发布后才知道。一种可能性是,随着Optical I/O互联技术的导入,GPU、HBM往解构、分散的方向发展,算力密度降低,对3D封装、高密PCB、液冷等方面的需求反而减弱。

另外一种可能性是,AI的算力需求实在太迫切了,即便引入Optical I/O,系统还会维持原来的地算力密度,这种情况下,这些β型产品会获得一定的边际增速。
