


Large language models (LLMs) like GPT-4 have become a significant focus in artificial intelligence due to their ability to handle various tasks, from generating text to solving complex mathematical problems. These models have demonstrated capabilities far beyond their original design, mainly to predict the next word in a sequence. While their utility spans numerous industries, such as automating data analysis and performing creative tasks, a key challenge lies in reliably evaluating their true performance. Understanding how well LLMs handle deterministic tasks, such as counting and performing basic arithmetic, is particularly important because these tasks offer clear, measurable outcomes. The complexity arises when even these simple tasks reveal inconsistencies in LLM performance.
One of the main problems this research addresses is the difficulty in assessing the accuracy of LLMs like GPT-4. Deterministic tasks with an exact solution are an ideal testbed for evaluating these models. However, GPT-4’s performance can vary widely, not just because of the inherent difficulty of the task but due to minor variations in how questions are framed or the characteristics of the input data. These subtle factors can lead to results that challenge the ability to generalize the model’s capabilities. For instance, even tasks as basic as counting items in a list show considerable variability in the model’s responses, making it clear that simple benchmarks may not be enough to accurately judge LLMs’ true abilities.
Existing methods to assess LLM performance typically involve running deterministic tasks that allow for clear, unambiguous answers. In this study, researchers tested GPT-4’s ability to count elements in a list, perform long multiplication, and sort numbers. For instance, in a counting task where the model had to determine how many times the word “mango” appeared in a list, GPT-4’s performance was not consistent. In 500 trials of a list with a length of 20, GPT-4 got the correct answer 48.2% of the time, but slight changes in phrasing or object frequency led to significantly different results. This inconsistency suggests that LLMs might not be as capable as assumed when performing basic arithmetic or logic-based tasks.
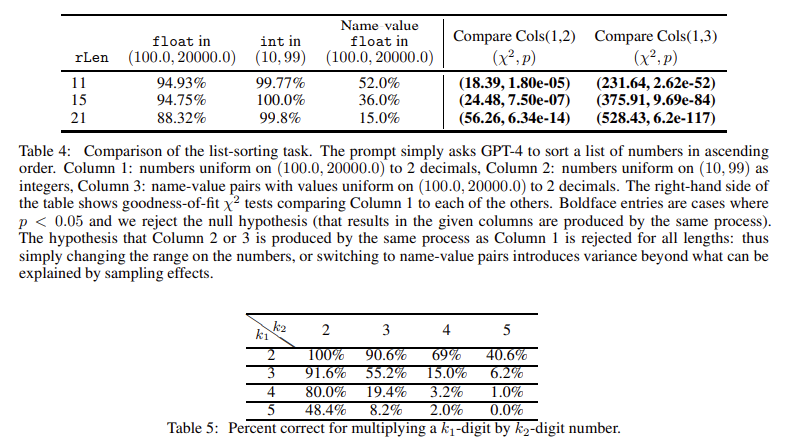
The research team from Microsoft Research introduced a new method to evaluate LLMs’ sensitivity to changes in task parameters. They focused on deterministic tasks, such as counting and long multiplication, under various conditions. For example, one set of trials asked GPT-4 to count occurrences of words in lists of different lengths, while another focused on multiplying two 4-digit numbers. Across all tasks, the researchers performed 500 trials for each condition, ensuring statistically significant results. Their findings showed that small modifications, such as rewording the prompt or altering list compositions, resulted in large performance variations. For instance, the success rate in the counting task dropped from 89.0% for ten items to just 12.6% for 40 items. Similarly, GPT-4’s accuracy in long multiplication tasks was 100% for multiplying two 2-digit numbers but fell to 1.0% for multiplying two 4-digit numbers.
The researchers also measured GPT-4’s performance across tasks, such as finding the maximum and median and sorting the order of numbers in a list. In the median-finding task, GPT-4 managed only a 68.4% success rate for lists containing floating-point numbers, and this rate decreased as the number of items in the list increased. Furthermore, when asked to sort a list of numbers with associated names, GPT-4’s accuracy dropped significantly, with a success rate below 55.0%. These experiments reveal how fragile the model’s performance is when tasked with operations requiring accurately handling structured data.
The research highlights a critical challenge in assessing the capabilities of large language models. While GPT-4 demonstrates a range of sophisticated behaviors, its ability to handle even basic tasks heavily depends on the specific phrasing of questions and the input data structure. These findings challenge the notion that LLMs can be trusted to perform tasks reliably across different contexts. For instance, GPT-4’s success rate for counting tasks varied by more than 70% depending on the length of the list and the frequency of the item being counted. This variability suggests that observed accuracy in specific tests might not generalize well to other similar but slightly modified tasks.

In conclusion, this research sheds light on the limitations of GPT-4 and other LLMs when performing deterministic tasks. While these models show promise, their performance is highly sensitive to minor changes in task conditions. The researchers demonstrated that GPT-4’s accuracy could drop from nearly perfect to almost random simply by altering the input data or rephrasing the question. For example, the model’s ability to multiply two 2-digit numbers was perfect, but its accuracy for 4-digit multiplications dropped to just 1.0%. The results suggest that caution is necessary when interpreting claims about the capabilities of LLMs. Although they can perform impressively in controlled scenarios, their performance might not generalize to slightly altered tasks. Developing more rigorous evaluation methods to assess their true capabilities is crucial.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

The post Microsoft Research Evaluates the Inconsistencies and Sensitivities of GPT-4 in Performing Deterministic Tasks: Analyzing the Impact of Minor Modifications on AI Performance appeared first on MarkTechPost.
