


Prior research on Large Language Models (LLMs) demonstrated significant advancements in fluency and accuracy across various tasks, influencing sectors like healthcare and education. This progress sparked investigations into LLMs’ language understanding capabilities and associated risks. Hallucinations, defined as plausible but incorrect information generated by models, emerged as a central concern. Studies explored whether these errors could be eliminated or required management, recognizing them as an intrinsic challenge of LLMs.
Recent advancements in LLMs have revolutionized natural language processing, yet the persistent challenge of hallucinations necessitates a deeper examination of their fundamental nature and implications. Drawing from computational theory and Gödel’s First Incompleteness Theorem, it introduces the concept of “Structural Hallucinations.” This novel perspective posits that every stage of the LLM process has a non-zero probability of producing hallucinations, emphasizing the need for a new approach to managing these inherent errors in language models.
This study challenges the conventional view of hallucinations in LLMs, presenting them as inevitable features rather than occasional errors. It argues that these inaccuracies stem from the fundamental mathematical and logical underpinnings of LLMs. By demonstrating the non-zero probability of errors at every stage of the LLM process, the research calls for a paradigm shift in approaching language model limitations.

United We Care Researchers propose a comprehensive methodology to address hallucinations in LLMs. The approach begins with enhanced information retrieval techniques, such as Chain-of-Thought prompting and Retrieval-Augmented Generation, to extract relevant data from the model’s database. This process is followed by input augmentation, combining retrieved documents with the original query to provide grounded context. The methodology then employs Self-Consistency methods during output generation, allowing the model to produce and select the most appropriate response from multiple options.
Post-generation techniques form a crucial part of the strategy, including Uncertainty Quantification and Faithfulness Explanation Generation. These methods aid in evaluating the correctness of generated responses and identifying potential hallucinations. The use of Shapley values to measure the faithfulness of explanations enhances output transparency and trustworthiness. Despite these comprehensive measures, the researchers acknowledge that hallucinations remain an intrinsic aspect of LLMs, emphasizing the need for continued development in managing these inherent limitations.
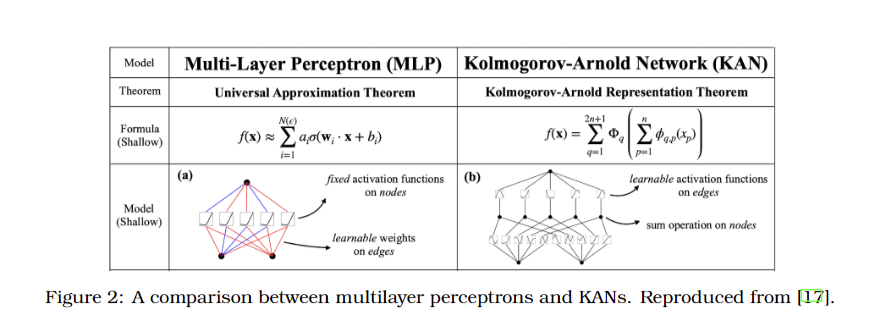
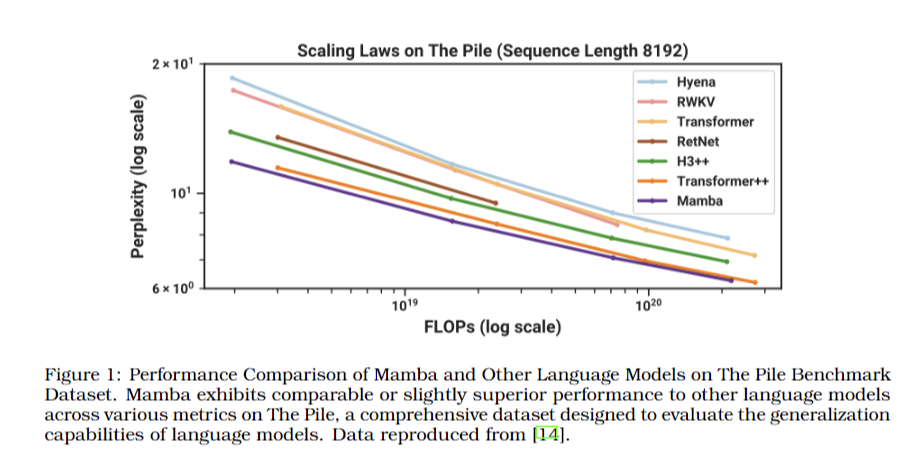
The study contends that hallucinations in LLMs are intrinsic and mathematically certain, not merely occasional errors. Every stage of the LLM process carries a non-zero probability of producing hallucinations, making their complete elimination impossible through architectural or dataset improvements. Architectural advancements, such as transformers and alternative models like KAN, Mamba, and Jamba, can improve training but do not address the fundamental problem of hallucinations. The paper argues that the performance of LLMs, including their ability to retrieve and generate information accurately, is inherently limited by their structural design. Although specific numerical results are not provided, the study emphasizes that improvements in architecture or training data cannot alter the probabilistic nature of hallucinations. This research underscores the need for a realistic understanding of LLM capabilities and limitations.
In conclusion, the study asserts that hallucinations in LLMs are intrinsic and ineliminable, persisting despite advancements in training, architecture, or fact-checking mechanisms. Every stage of LLM output generation is susceptible to hallucinations, highlighting the systemic nature of this issue. Drawing on computational theory concepts, the paper argues that certain LLM-related problems are undecidable, reinforcing the impossibility of complete accuracy. The authors challenge prevailing beliefs about mitigating hallucinations, calling for realistic expectations and a shift towards managing, rather than eliminating, these inherent limitations in LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

The post Understanding the Inevitable Nature of Hallucinations in Large Language Models: A Call for Realistic Expectations and Management Strategies appeared first on MarkTechPost.
