


Deep learning has made significant strides in artificial intelligence, particularly in natural language processing and computer vision. However, even the most advanced systems often fail in ways that humans would not, highlighting a critical gap between artificial and human intelligence. This discrepancy has reignited debates about whether neural networks possess the essential components of human cognition. The challenge lies in developing systems that exhibit more human-like behavior, particularly regarding robustness and generalization. Unlike humans, who can adapt to environmental changes and generalize across diverse visual settings, AI models often need help with shifted data distributions between training and test sets. This lack of robustness in visual representations poses significant challenges for downstream applications that require strong generalization capabilities.
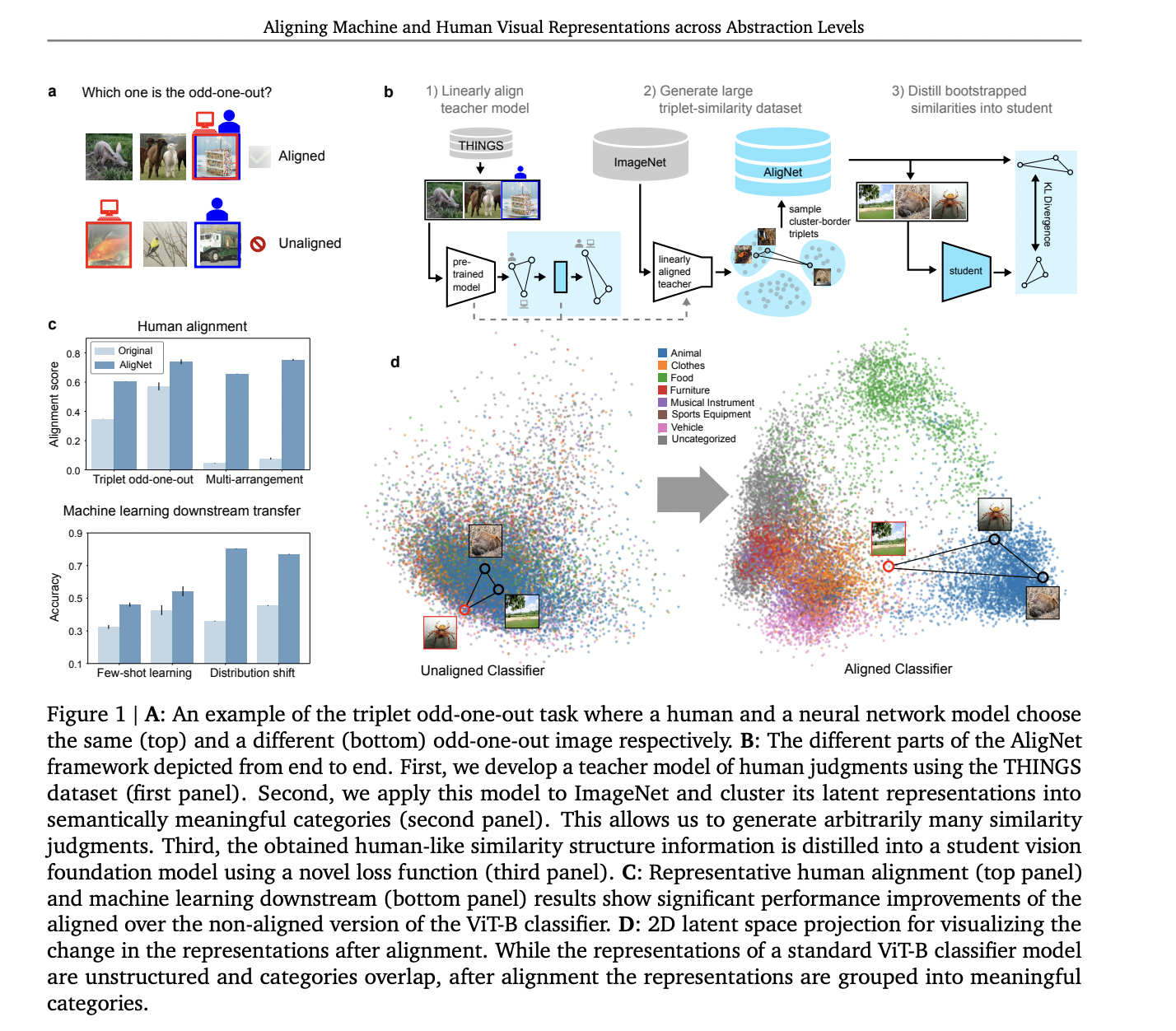
Researchers from Google DeepMind, Machine Learning Group, Technische Universität Berlin, BIFOLD, Berlin Institute for the Foundations of Learning and Data, Max Planck Institute for Human Development, Anthropic, Department of Artificial Intelligence, Korea University, Seoul, Max Planck Institute for Informatics propose a unique framework called AligNet to address the misalignment between human and machine visual representations. This approach aims to simulate large-scale human-like similarity judgment datasets for aligning neural network models with human perception. The methodology begins by using an affine transformation to align model representations with human semantic judgments in triplet odd-one-out tasks. This process incorporates uncertainty measures from human responses to improve model calibration. The aligned version of a state-of-the-art vision foundation model (VFM) then serves as a surrogate for generating human-like similarity judgments. By grouping representations into meaningful superordinate categories, the researchers sample semantically significant triplets and obtain odd-one-out responses from the surrogate model, resulting in a comprehensive dataset of human-like triplet judgments called AligNet.
The results demonstrate significant improvements in aligning machine representations with human judgments across multiple levels of abstraction. For global coarse-grained semantics, soft alignment substantially enhanced model performance, with accuracies increasing from 36.09-57.38% to 65.70-68.56%, surpassing the human-to-human reliability score of 61.92%. In local fine-grained semantics, alignment improved moderately, with accuracies rising from 46.04-57.72% to 58.93-62.92%. For class-boundary triplets, AligNet fine-tuning achieved remarkable alignment, with accuracies reaching 93.09-94.24%, exceeding the human noise ceiling of 89.21%. The effectiveness of alignment varied across abstraction levels, with different models showing strengths in different areas. Notably, AligNet fine-tuning generalized well to other human similarity judgment datasets, demonstrating substantial improvements in alignment across various object similarity tasks, including multi-arrangement and Likert-scale pairwise similarity ratings.


The AligNet methodology comprises several key steps to align machine representations with human visual perception. Initially, it uses the THINGS triplet odd-one-out dataset to learn an affine transformation into a global human object similarity space. This transformation is applied to a teacher model’s representations, creating a similarity matrix for object pairs. The process incorporates uncertainty measures about human responses using an approximate Bayesian inference method, replacing hard alignment with soft alignment.
The objective function of learning the uncertainty distillation transformation is to combine soft alignment with regularization to preserve local similarity structure. The transformed representations are then clustered into superordinate categories using k-means clustering. These clusters guide the generation of triplets from distinct ImageNet images, with odd-one-out choices determined by the surrogate teacher model.
Finally, a robust Kullback-Leibler divergence-based objective function facilitates the distillation of the teacher’s pairwise similarity structure into a student network. This AligNet objective is combined with regularization to preserve the pre-trained representation space, resulting in a fine-tuned student model that better aligns with human visual representations across multiple levels of abstraction.
This study addresses a critical deficiency in vision foundation models: their inability to adequately represent the multi-level conceptual structure of human semantic knowledge. By developing the AligNet framework, which aligns deep learning models with human similarity judgments, the research demonstrates significant improvements in model performance across various cognitive and machine learning tasks. The findings contribute to the ongoing debate about neural networks’ capacity to capture human-like intelligence, particularly in relational understanding and hierarchical knowledge organization. Ultimately, this work illustrates how representational alignment can enhance model generalization and robustness, bridging the gap between artificial and human visual perception.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

The post Google DeepMind Researchers Propose Human-Centric Alignment for Vision Models to Boost AI Generalization and Interpretation appeared first on MarkTechPost.
