


Data science is a rapidly evolving field that leverages large datasets to generate insights, identify trends, and support decision-making across various industries. It integrates machine learning, statistical methods, and data visualization techniques to tackle complex data-centric problems. As the volume of data grows, there is an increasing demand for sophisticated tools capable of handling large datasets and intricate and diverse types of information. Data science plays a crucial role in advancing fields such as healthcare, finance, and business analytics, making it essential to develop methods that can efficiently process and interpret data.
One of the fundamental challenges in data science is developing tools that can handle real-world problems involving extensive datasets and multifaceted data structures. Existing tools often need to be improved when dealing with practical scenarios that require analyzing complex relationships, multimodal data sources, and multi-step processes. These challenges manifest in many industries where data-driven decisions are pivotal. For instance, organizations need tools to process data efficiently and make accurate predictions or generate meaningful insights in the face of incomplete or ambiguous data. The limitations of current tools necessitate further development to keep pace with the growing demand for advanced data science solutions.
Traditional methods and tools for evaluating data science models have primarily relied on simplified benchmarks. While these benchmarks have successfully assessed the basic capabilities of data science agents, they need to capture the intricacies of real-world tasks. Many existing benchmarks focus on tasks such as code generation or solving mathematical problems. These tasks are typically single-modality or relatively simple compared to the complexity of real-world data science problems. Moreover, these tools are often constrained to specific programming environments, such as Python, limiting their utility in practical, tool-agnostic scenarios requiring flexibility.
Researchers from the University of Texas at Dallas, Tencent AI Lab, and the University of Southern California have introduced DSBench, a comprehensive benchmark designed to evaluate data science agents on tasks that closely mimic real-world conditions to address these shortcomings. DSBench consists of 466 data analysis tasks and 74 data modeling tasks derived from popular platforms like ModelOff and Kaggle, known for their challenging data science competitions. The tasks included in DSBench encompass a wide range of data science challenges, including tasks that require agents to process long contexts, deal with multimodal data sources, and perform complex, end-to-end data modeling. The benchmark evaluates the agents’ ability to generate code and their capability to reason through tasks, manipulate large datasets, and solve problems that mirror practical applications.
DSBench’s focus on realistic, end-to-end tasks sets it apart from previous benchmarks. The benchmark includes tasks that require agents to analyze data files, understand complex instructions, and perform predictive modeling using large datasets. For instance, DSBench tasks often involve multiple tables, large data files, and intricate structures that must be interpreted and processed. The Relative Performance Gap (RPG) metric assesses performance across different data modeling tasks, providing a standardized way to evaluate agents’ capabilities in solving various problems. DSBench includes tasks designed to measure agents’ effectiveness when working with multimodal data, such as text, tables, and images, frequently encountered in real-world data science projects.
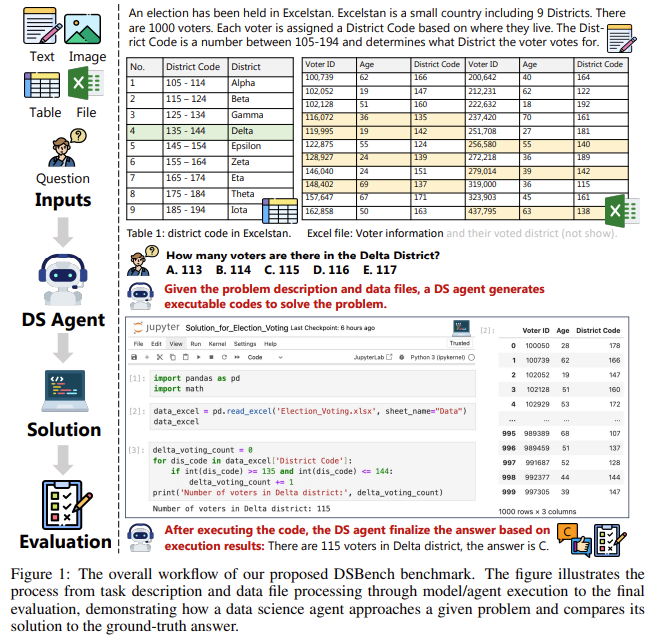
The initial evaluation of state-of-the-art models on DSBench has revealed significant gaps in current technologies. For example, the best-performing agent solved only 34.12% of the data analysis tasks and achieved an RPG score of 34.74% for data modeling tasks. These results indicate that even the most advanced models, such as GPT-4o and Claude, need help to handle the full complexity of the functions presented in DSBench. Other models, including LLaMA and AutoGen, faced difficulties performing well across the benchmark. The results highlight the considerable challenges in developing data science agents capable of functioning autonomously in complex, real-world scenarios. These findings suggest that while there has been progress in the field, significant work remains to be done in improving the efficiency and adaptability of these models.


In conclusion, DSBench represents a critical advancement in evaluating data science agents, providing a more comprehensive and realistic testing environment. The benchmark has demonstrated that existing tools fall short when faced with the complexities and challenges of real-world data science tasks, which often involve large datasets, multimodal inputs, and end-to-end processing requirements. Through tasks derived from competitions like ModelOff and Kaggle, DSBench reflects the actual challenges that data scientists encounter in their work. The introduction of the Relative Performance Gap metric further ensures that the evaluation of these agents is thorough and standardized. The performance of current models on DSBench underscores the need for more advanced, intelligent, and autonomous tools capable of addressing real-world data science problems. The gap between current technologies and the demands of practical applications remains significant, and future research must focus on developing more robust and flexible solutions to close this gap.
Check out the Paper and Code. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

The post DSBench: A Comprehensive Benchmark Highlighting the Limitations of Current Data Science Agents in Handling Complex, Real-world Data Analysis and Modeling Tasks appeared first on MarkTechPost.
