


Researchers have focused on developing and building models to process and compare human language in natural language processing efficiently. One key area of exploration involves sentence embeddings, which transform sentences into mathematical vectors to compare their semantic meanings. This technology is crucial for semantic search, clustering, and natural language inference tasks. Models handling such tasks can significantly improve question-answer systems, conversational agents, and text classification. However, despite advances in this field, scalability remains a major challenge, particularly when working with large datasets or real-time applications.
A notable issue in text processing arises from the computational cost of comparing sentences. Traditional models, such as BERT and RoBERTa, have set new standards for sentence-pair comparison, yet they are inherently slow for tasks that require processing large datasets. For instance, finding the most similar sentence pair in a collection of 10,000 sentences using BERT requires about 50 million inference computations, which can take up to 65 hours on modern GPUs. The inefficiency of these models creates significant barriers to scaling up text analysis. It hinders their application in real-time systems, making them impractical for many large-scale applications like web searches or customer support automation.
Previous attempts to address these challenges have leveraged different strategies, but most compromise on performance to gain efficiency. For example, some methods involve mapping sentences to a vector space, where semantically similar sentences are placed closer together. While this helps reduce computational overhead, the quality of the resulting sentence embeddings often suffers. The widely used approach of averaging BERT outputs or using the [CLS] token does not perform well for these tasks, yielding results that are sometimes worse than older, simpler models like GloVe embeddings. As such, the search for a solution that balances computational efficiency with high performance has continued.
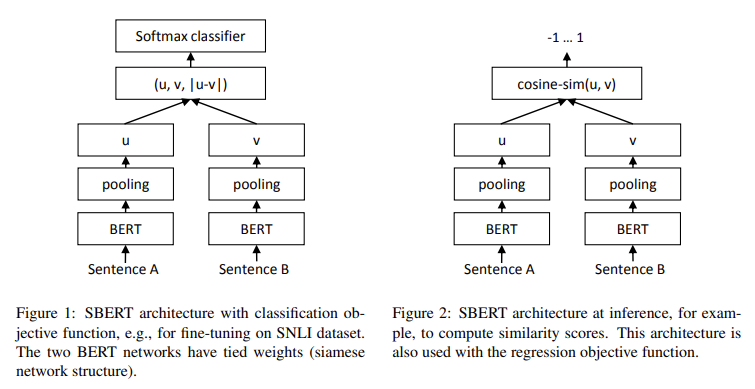
Researchers from the Ubiquitous Knowledge Processing Lab (UKP-TUDA) at the Department of Computer Science, Technische Universitat Darmstadt, introduced Sentence-BERT (SBERT), a modification of the BERT model designed to handle sentence embeddings in a more computationally feasible way. The SBERT model utilizes a Siamese network architecture, which enables the comparison of sentence embeddings using efficient similarity measures like cosine similarity. The research team optimized SBERT to reduce the computational time for large-scale sentence comparisons, cutting the processing time from 65 hours to just five seconds for a set of 10,000 sentences. SBERT achieves this remarkable efficiency while maintaining the accuracy levels of BERT, proving that both speed and precision can be balanced in sentence-pair comparison tasks.
The technology behind SBERT involves using different pooling strategies to generate fixed-size vectors from sentences. The default strategy averages the output vectors (the MEAN strategy), while other options include max-over-time pooling and using the CLS-token. SBERT was fine-tuned using a large dataset from natural language inference tasks, such as the SNLI and MultiNLI corpora. This fine-tuning allowed SBERT to outperform previous sentence embedding methods like InferSent and Universal Sentence Encoder across multiple benchmarks. On seven common Semantic Textual Similarity (STS) tasks, SBERT improved by 11.7 points compared to InferSent and 5.5 points over the Universal Sentence Encoder.
SBERT’s performance is not just limited to its speed. The model demonstrated superior accuracy across several datasets. In particular, on the STS benchmark, SBERT achieved a Spearman rank correlation of 79.23 for its base version and 85.64 for the large version. In comparison, InferSent scored 68.03, and the Universal Sentence Encoder scored 74.92. SBERT also performed well in transfer learning tasks using the SentEval toolkit, where it achieved higher scores in sentiment prediction tasks such as movie review sentiment classification (84.88% accuracy) and product review sentiment classification (90.07% accuracy). The ability of SBERT to fine-tune its performance across a range of tasks makes it highly versatile for real-world applications.

The key advantage of SBERT is its ability to scale sentence comparison tasks while preserving high accuracy. For instance, it can reduce the time needed to find the most similar question in a large dataset like Quora from over 50 hours with BERT to a few milliseconds with SBERT. This efficiency is achieved through optimized network structures and efficient similarity measures. SBERT outperforms other models in clustering tasks, making it ideal for large-scale text analysis projects. In computational benchmarks, SBERT processed up to 2,042 sentences per second on GPUs, a 9% increase over InferSent and 55% faster than the Universal Sentence Encoder.

In conclusion, SBERT significantly improves traditional sentence embedding methods by offering a computationally efficient and highly accurate solution. By reducing the time needed for sentence comparison tasks from hours to seconds, SBERT addresses the critical challenge of scalability in natural language processing. Its superior performance across multiple benchmarks, including STS and transfer learning tasks, makes it a valuable tool for researchers and practitioners. With its speed and accuracy, SBERT is set to become an essential model for large-scale text analysis, enabling faster and more reliable semantic search, clustering, and other natural language processing tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

The post Optimizing Large-Scale Sentence Comparisons: How Sentence-BERT (SBERT) Reduces Computational Time While Maintaining High Accuracy in Semantic Textual Similarity Tasks appeared first on MarkTechPost.
