


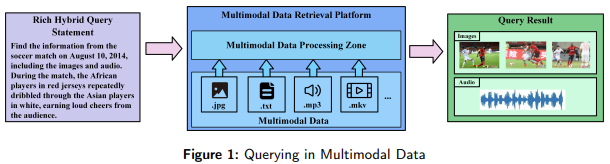
Multimodal data retrieval is a significant area of research that focuses on managing and retrieving data from multiple sources, such as text, audio, video, and images. As data grows in volume and complexity, especially in sectors like artificial intelligence and big data analytics, retrieving information from diverse formats becomes crucial. The challenges in multimodal data retrieval arise from the need to store and retrieve unstructured data types effectively. This is critical in healthcare, law enforcement, and recommendation systems, where handling large and complex datasets can directly influence decision-making processes.
One of the primary problems in multimodal data retrieval lies in the inability of existing systems to manage and query data across multiple formats efficiently. Traditional methods face limitations in handling unstructured data due to their rigid storage schemas, which make them ill-equipped to deal with diverse data formats. Current systems struggle to execute complex queries that involve a combination of different data types, such as numeric and vector data. With 80% of global data expected to be multimodal by 2025, it is increasingly important to develop a system capable of effectively handling diverse queries while optimizing data storage and retrieval performance.
Existing platforms that attempt to address these issues include schema-on-write systems, multi-model databases, vector databases, and data lakes. Each approach has limitations. For example, schema-on-write systems, such as relational databases, are inflexible due to their reliance on fixed schemas, which makes them unsuitable for handling unstructured multimodal data. Multi-model databases offer flexibility by supporting various data formats but are limited in query options, especially when dealing with hybrid queries involving multiple data types. Vector databases, designed specifically for high-dimensional vector data, cannot manage raw multimodal data and are inefficient when handling complex queries. Data lakes, although capable of storing large amounts of raw data in its original form, need robust query and indexing capabilities, leading to inefficient retrieval processes.
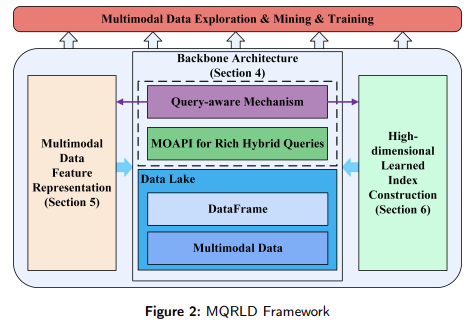
Researchers from Beijing Institute of Technology, Tsinghua University, Henan University, and the University of Chinese Academy of Sciences have developed a Multimodal Data Retrieval Platform with Query-aware Feature Representation and Learned Index based on Data Lake (MQRLD). The MQRLD system combines the advantages of a data lake’s transparent storage capabilities with a learned index and query-aware mechanism. This platform addresses the limitations of current retrieval systems by supporting flexible, transparent storage and introducing a multimodal data feature representation technique. The platform enables rich hybrid queries, optimizing the retrieval process across various data types while maintaining high performance in both accuracy and speed.
The MQRLD platform integrates a learned index mechanism, enhancing query performance by adapting to different data types and patterns. This index leverages the structure of the data to improve retrieval speed and accuracy. The system’s data lake foundation allows for transparent storage of multimodal data, such as images, text, and video, without predefined schemas. The data is stored in its original form, allowing users to run queries across multiple formats without restructuring it. The feature representation mechanism transforms raw multimodal data into an easily indexed and queried format. This is achieved by recognizing patterns within the data and using a learned indexing model to optimize the search process, significantly improving the accuracy and speed of retrieval tasks.
Performance tests conducted on the MQRLD platform showed its superiority over traditional methods. For instance, in tests involving high-dimensional data, the learned index significantly reduced query times, improving the overall efficiency of the platform. The MQRLD platform demonstrated a recall rate of 95% for complex multimodal queries, considerably outperforming existing vector and multi-model database systems, which achieved recall rates of only 80% and 85%, respectively. The platform’s ability to process rich hybrid queries involving numeric and vector data sets it apart from traditional methods that struggle with such tasks. This performance boost was further enhanced by the platform’s query-aware mechanism, which allowed for real-time optimization of the retrieval process based on query behavior.
The MQRLD platform also includes a multimodal open API (MOAPI), which enables users to perform hybrid queries across different data types. This API supports several query types, including numeric equal, range, and vector-based nearest neighbor searches. These query capabilities allow users to search through complex datasets, such as retrieving specific audio-visual clips based on numerical and descriptive criteria. Furthermore, the API is designed to support complex multimodal queries that combine numeric and vector-based searches, enhancing the system’s versatility in real-world applications.

In conclusion, the MQRLD platform significantly advances multimodal data retrieval. Integrating a learned index and a query-aware mechanism with a data lake infrastructure provides a robust solution to the growing challenges of multimodal data management. Its performance demonstrated through faster query times and higher accuracy rates, marks it as a leading tool in the field. The platform’s ability to handle complex multimodal data queries and adapt to different data patterns provides significant benefits for industries that rely on large-scale data retrieval, including healthcare, law enforcement, and artificial intelligence applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

The post MQRLD: A Groundbreaking Platform for Efficient Multimodal Data Retrieval, Offering Transparent Storage, Learned Indexing, and Superior Query Performance appeared first on MarkTechPost.
