


Speech processing focuses on developing systems to analyze, interpret, and generate human speech. These technologies encompass a range of applications, such as automatic speech recognition (ASR), speaker verification, speech-to-text translation, and speaker diarization. With the growing reliance on virtual assistants, transcription services, and multilingual communication tools, efficient and accurate speech processing has become essential. Researchers have increasingly turned to machine learning and self-supervised learning techniques to tackle the complexities of human speech, aiming to improve system performance across different languages and environments.
One of the primary challenges in this field is the computational inefficiency of existing self-supervised models. Many of these models, though effective, are resource-intensive due to their reliance on techniques like clustering-based speech quantization and limited sub-sampling. This often leads to faster processing speeds and higher computational costs. Moreover, these models frequently struggle to distinguish between speakers in multi-speaker environments or separate the main speaker from background noise, both common in real-world applications. Addressing these issues is crucial for building faster and more scalable systems that can be deployed in various practical scenarios.
Several models currently dominate the landscape of self-supervised speech learning. Wav2vec-2.0, for instance, utilizes contrastive learning, while HuBERT relies on a predictive approach that uses k-means clustering to generate target tokens. Despite their success, these models present significant limitations, including high computational demands and slower inference times due to their architecture. Their performance on speaker-specific tasks, such as speaker diarization, is hindered by their limited ability to explicitly separate one speaker from another, particularly in noisy environments or when multiple speakers are present.
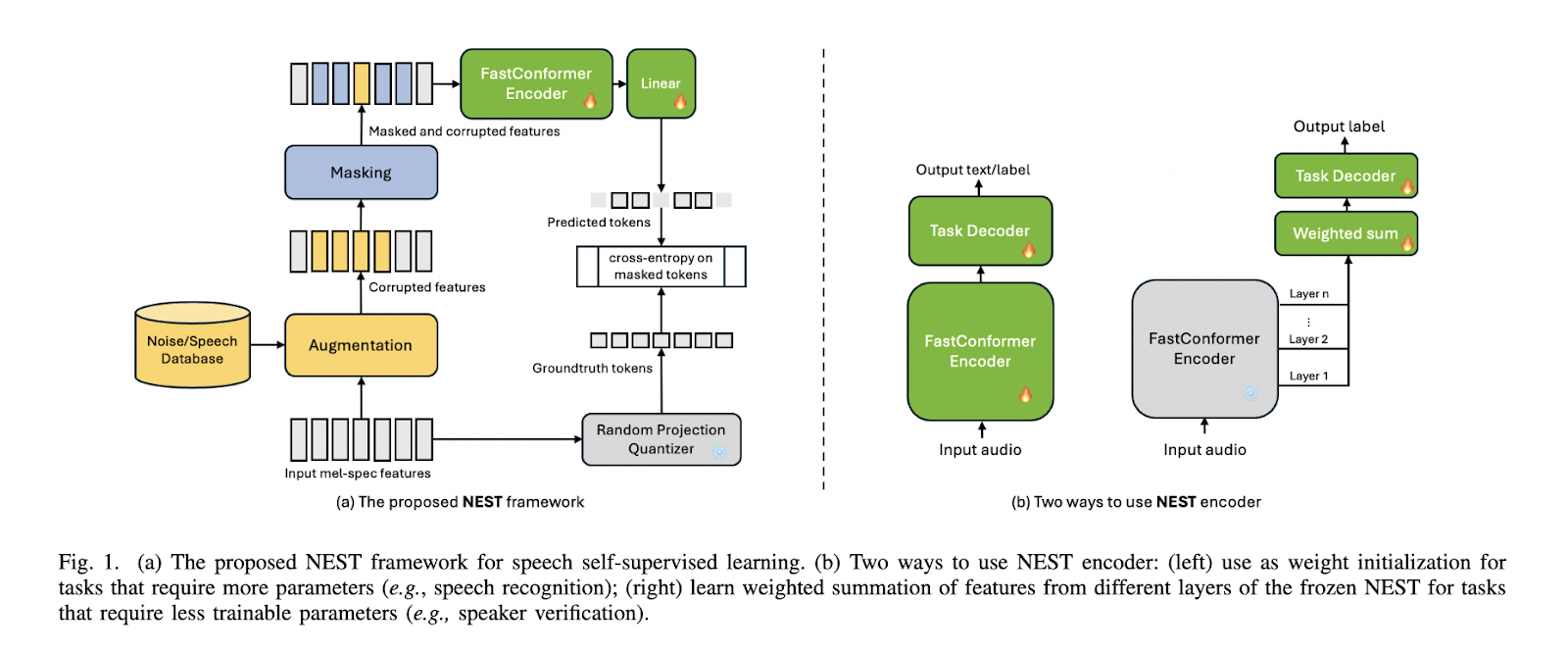
Researchers from NVIDIA have introduced a new solution, the NeMo Encoder for Speech Tasks (NEST), which addresses these challenges. NEST is built on the FastConformer architecture, offering an efficient and simplified framework for self-supervised learning in speech processing. Unlike previous models, NEST features an 8x sub-sampling rate, making it faster than architectures like Transformer and Conformer, which typically use 20ms or 40ms frame lengths. This reduction in sequence length significantly decreases the computational complexity of the model, improving its ability to handle large speech datasets while maintaining high accuracy.
The methodology behind NEST involves several innovative approaches to streamline and enhance speech processing. One key feature is its random projection-based quantization technique, which replaces the computationally expensive clustering methods used by models like HuBERT. This simpler method significantly reduces the time and resources required for training while still achieving state-of-the-art performance. NEST incorporates a generalized noisy speech augmentation technique. This augmentation enhances the model’s ability to disentangle the main speaker from background noise or other speakers by randomly inserting speech segments from multiple speakers into the input data. This approach provides the model with robust training in diverse, real-world audio environments, improving performance on tasks involving speaker identification and separation.
The NEST model’s architecture is designed to maximize efficiency and scalability. It applies convolutional sub-sampling to the input Mel-spectrogram features before they are processed by the FastConformer layers. This step reduces the input sequence length, resulting in faster training times without sacrificing accuracy. Moreover, the random projection quantization method uses a fixed codebook with 8192 vocabulary and 16-dimensional features, further simplifying the learning process while ensuring that the model captures the essential characteristics of the speech input. The researchers have also implemented a block-wise masking mechanism, randomly selecting input segments to be masked during training, encouraging the model to learn robust representations of speech features.
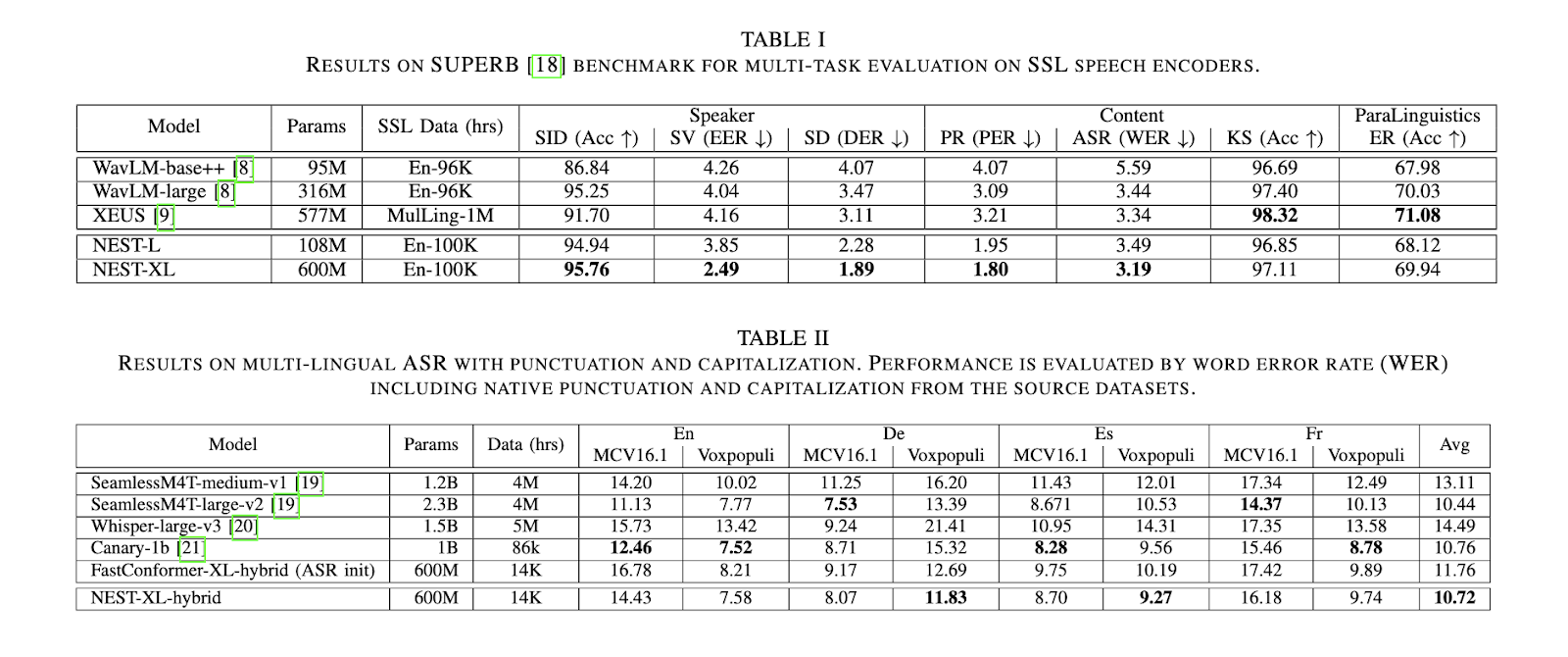
Performance results from experiments conducted by the NVIDIA research team are remarkable. In a variety of speech processing tasks, NEST consistently outperforms existing models, such as WavLM and XEUS. For example, in tasks like speaker diarization and automatic speech recognition, NEST achieved state-of-the-art results, surpassing WavLM-large, which has three times the parameters of NEST. In speaker diarization, NEST achieved a diarization error rate (DER) of 2.28% compared to WavLM’s 3.47%, marking a significant improvement in accuracy. Further, in phoneme recognition tasks, NEST reported a phoneme error rate (PER) of 1.89%, further demonstrating its ability to handle a variety of speech processing challenges.
Furthermore, NEST’s performance in multilingual ASR tasks is impressive. The model was evaluated on datasets across four languages: English, German, French, and Spanish. Despite being primarily trained in English data, NEST achieved reduced word error rates (WER) in all four languages. For instance, in the German ASR test, NEST recorded a WER of 7.58%, outperforming several larger models like Whisper-large and SeamlessM4T. These results highlight the model’s ability to generalize across languages, making it a valuable tool for multilingual speech recognition tasks.
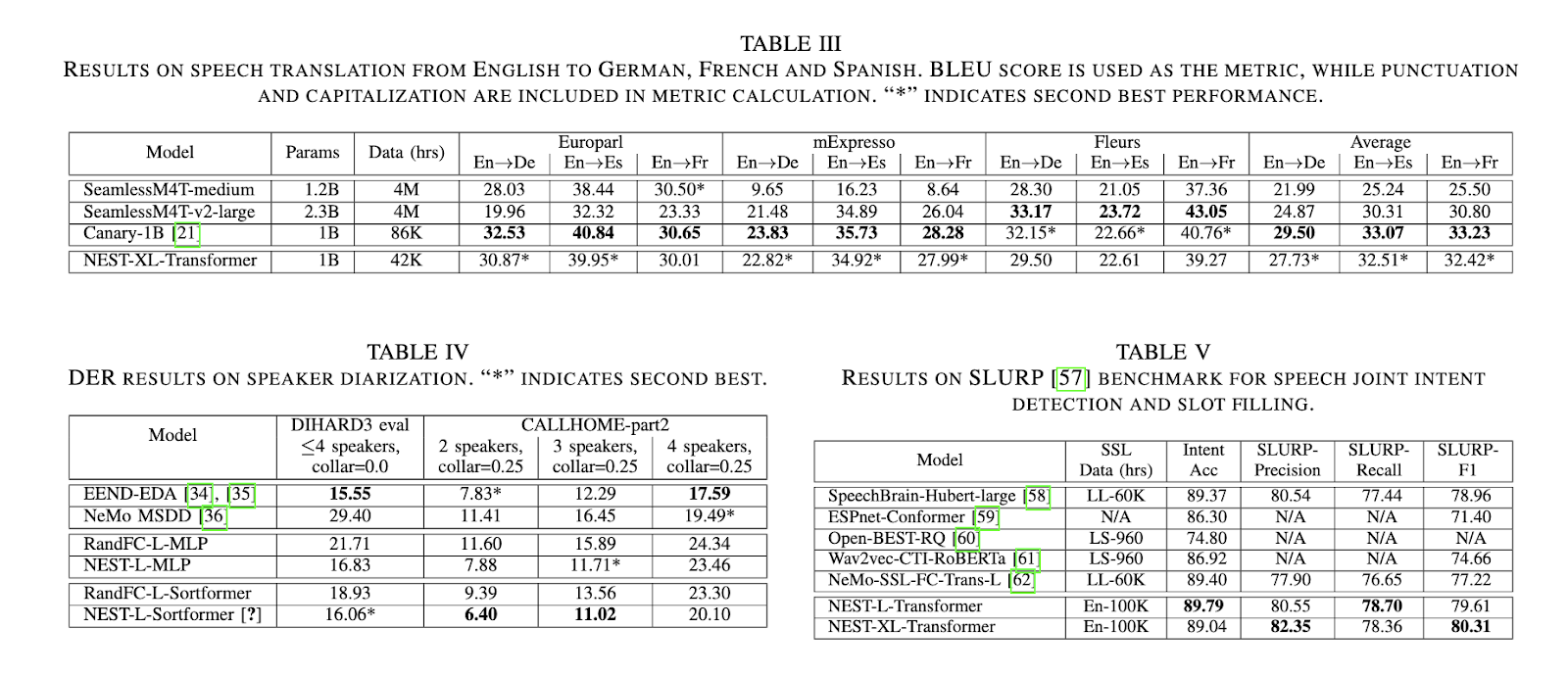
In conclusion, the NEST framework represents a significant leap forward in the field of speech processing. By simplifying the architecture and introducing innovative techniques like random projection-based quantization and generalized noisy speech augmentation, the researchers at NVIDIA have created a model that is not only faster and more efficient but also highly accurate across a variety of speech processing tasks. NEST’s performance on tasks like ASR, speaker diarization, and phoneme recognition underscores its potential as a scalable solution for real-world speech processing challenges.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

The post This AI Paper by NVIDIA Introduces NEST: A Fast and Efficient Self-Supervised Model for Speech Processing appeared first on MarkTechPost.
