


AI has seen significant progress in coding, mathematics, and reasoning tasks. These advancements are driven largely by the increased use of large language models (LLMs), essential for automating complex problem-solving tasks. These models are increasingly used to handle highly specialized and structured problems in competitive programming, mathematical proofs, and real-world coding issues. This rapid evolution is transforming how AI is applied across industries, showcasing the potential to address difficult computational tasks requiring deep learning models to understand and accurately solve these challenges.
One of the key challenges that AI models face is optimizing their performance during inference, which is the stage where models generate solutions based on given inputs. In most scenarios, LLMs are only given one opportunity to solve a problem, resulting in missed opportunities to arrive at correct solutions. This limitation remains despite significant investments in training models on large datasets and improving their ability to handle reasoning and problem-solving. The core issue is the restricted compute resources allocated during inference. Researchers have long realized that training larger models has led to improvements, but inference, the process where models apply what they’ve learned, still lags behind optimization and efficiency. Consequently, this bottleneck limits the full potential of AI in high-stakes, real-world tasks like coding competitions and formal verification problems.
Various computational methods have been used to address this gap and improve inference. One popular approach is to scale up model size or to use techniques such as chain-of-thought prompting, where models generate step-by-step reasoning before delivering their final answers. While these methods do improve accuracy, they come at a significant cost. Larger models and advanced inference techniques require more computational resources and longer processing times, which are only sometimes practical. Because models are often constrained to making just one attempt at solving a problem, they need to be allowed to explore different solution paths fully. For example, state-of-the-art models like GPT-4o and Claude 3.5 Sonnet may produce a high-quality solution on the first try, but the high costs associated with their use limit their scalability.
Researchers from Stanford University, University of Oxford, and Google DeepMind introduced a novel solution to these limitations called “repeated sampling.” This approach involves generating multiple solutions for a problem and using domain-specific tools, such as unit tests or proof verifiers, to select the best answer. In the repeated sampling approach, the AI generates numerous outputs. Instead of relying on just one, researchers review a batch of generated solutions and then apply a verifier to pick the correct one. This method shifts the focus from requiring the most powerful model for a single attempt to maximizing the probability of success through multiple tries. Interestingly, the process shows that weaker models can be amplified through repeated sampling, often exceeding the performance of stronger models on a single-attempt basis. The researchers apply this method to tasks ranging from competitive coding to formal mathematics, proving the cost-effectiveness and efficiency of the approach.
One of the key technical aspects of this repeated sampling method is the ability to scale the number of generated solutions and systematically narrow down the best ones. The technique works especially well in domains where verification is straightforward, such as coding, where unit tests can quickly identify whether a solution is correct. For example, in coding competitions, researchers used repeated sampling on the CodeContests dataset, which consists of coding problems that require models to output correct Python3 programs. Here, the researchers generated as many as 10,000 attempts per problem, leading to significant performance gains. In particular, the coverage, or the fraction of the issues solved by any sample, increased substantially as the number of samples grew. For instance, with the Gemma-2B model, the success rate increased from 0.02% on the first attempt to 7.1% when samples reached 10,000. Similar patterns were observed with Llama-3 models, where the coverage rose exponentially as the number of attempts scaled up, showing that even weaker models could outperform stronger ones when given sufficient opportunities.
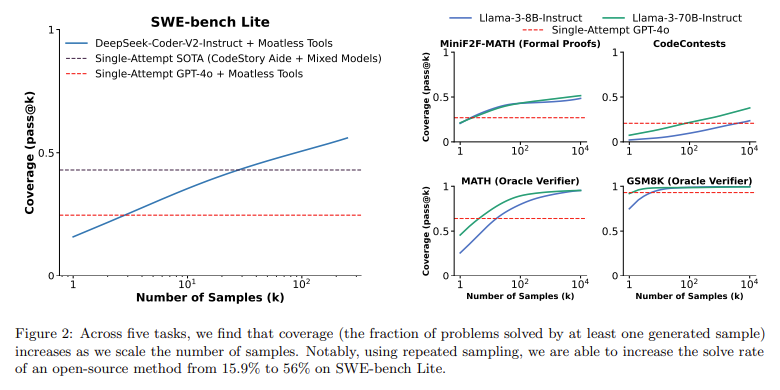
The performance benefits of repeated sampling were especially notable in the SWE-bench Lite dataset, which consists of real-world GitHub issues where models must modify codebases and verify their solutions with automated unit tests. By allowing a model like DeepSeek-V2-Coder-Instruct to make 250 attempts, researchers were able to solve 56% of the coding issues, surpassing the single-attempt state-of-the-art performance of 43% achieved by more powerful models such as GPT-4o and Claude 3.5 Sonnet. This improvement shows the advantages of applying multiple samples rather than relying on a single, expensive solution attempt. In practical terms, sampling five times from the cheaper DeepSeek model was more cost-effective than using a single sample from premium models like GPT-4o or Claude while also solving more problems.
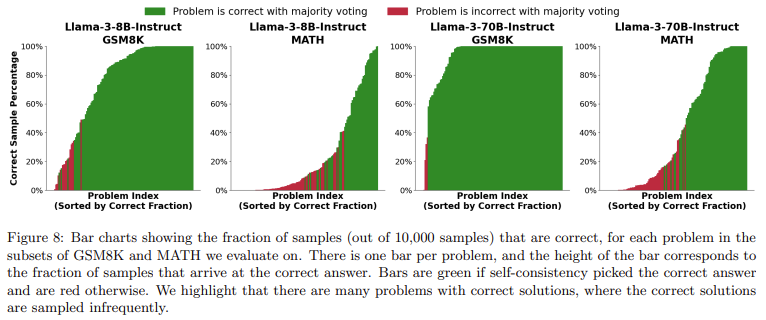
Beyond coding and formal proof problems, repeated sampling also demonstrated promise in solving mathematical word problems. In settings where automatic verifiers, such as proof checkers or unit tests, are unavailable, researchers noted a gap between coverage and the ability to pick the correct solution from a set of generated samples. In tasks like the MATH dataset, Llama-3 models achieved 95.3% coverage with 10,000 samples. However, common methods for selecting the correct solution, such as majority voting or reward models, plateaued beyond a few hundred samples and needed to scale with the sampling budget fully. These results indicate that while repeated sampling can generate many correct solutions, identifying the correct one remains challenging in domains where solutions cannot be verified automatically.
Researchers found that the relationship between coverage and the number of samples followed a log-linear trend in most cases. This behavior was modeled using an exponentiated power law, providing insights into how inference computes scales with the number of samples. In simpler terms, as models generate more attempts, the probability of solving the problem increases predictably. This pattern held across various models, including Llama-3, Gemma, and Pythia, which ranged from 70M to 70B parameters. Coverage grew consistently with the number of samples, even in smaller models like Pythia-160M, where coverage improved from 0.27% with one attempt to 57% with 10,000 samples. The repeated sampling method proved adaptable across various tasks and model sizes, reinforcing its versatility for improving AI performance.

In conclusion, the researchers culminated that repeated sampling enhances problem coverage and offers a cost-effective alternative to using more expensive, powerful models. Their experiments showed that amplifying a weaker model through repeated sampling could often yield better results than relying on a single attempt from a more capable model. For instance, using the DeepSeek model with multiple samples reduced the overall computation costs and improved performance metrics, solving more issues than models like GPT-4o. While repeated sampling is especially effective in tasks where verifiers can automatically identify correct solutions, it also highlights the need for better verification methods in domains without such tools.
Check out the Paper, Dataset, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post Stanford Researchers Explore Inference Compute Scaling in Language Models: Achieving Enhanced Performance and Cost Efficiency through Repeated Sampling appeared first on MarkTechPost.
