


Language models (LMs) have gained significant attention in recent years due to their remarkable capabilities. While training these models, neural sequence models are first pre-trained on a large, minimally curated web text, and then fine-tuned using specific examples and human feedback. However, these models often possess undesirable skills or knowledge creators wish to remove before deployment. The challenge lies in effectively “unlearning” or forgetting specific potential without losing the model’s overall performance. While recent research has focused on developing techniques to remove targeted skills and knowledge from LMs, there has been limited evaluation of how this forgetting generalizes to other inputs.
Existing attempts to address the challenge of machine “unlearning” have evolved from previous methods focused on removing undesirable data from training sets to more advanced techniques. These include optimization-based techniques, model editing using parameter importance estimation, and gradient ascent on undesirable responses. Some methods include frameworks for comparing unlearned networks to fully retrained ones, while some methods are specific to large language models (LLMs) like misinformation prompts or manipulating model representations. However, most of these approaches have limitations in feasibility, generalization, or applicability to complex models like LLMs.
Researchers from MIT have proposed a novel approach to study the generalization behavior in forgetting skills within LMs. This method involves fine-tuning models on randomly labeled data for target tasks, a simple yet effective technique for inducing forgetting. The experiments are conducted to characterize forgetting generalization and uncover several key findings. The approach highlights the nature of forgetting in LMs and the complexities of effectively removing undesired potential from these systems. This research shows complex patterns of cross-task variability in forgetting and the need for further study on how the training data used for forgetting affects the model’s predictions in other areas.
A comprehensive evaluation framework is used, which utilizes 21 multiple-choice tasks across various domains such as commonsense reasoning, reading comprehension, math, toxicity, and language understanding. These tasks are selected to cover a broad area of capabilities while maintaining a consistent multiple-choice format. The evaluation process follows the Language Model Evaluation Harness (LMEH) standards for zero-shot evaluation, using default prompts and evaluating probabilities of choices. The tasks are binarized, and steps are taken to clean the datasets by removing overlaps between training and testing data and limiting sample sizes to maintain consistency. The experiments primarily use the Llama2 7-B parameter base model, providing a robust foundation for analyzing forgetting behavior.
The results demonstrate diverse forgetting behaviors across different tasks. After fine-tuning, test accuracy increases, although it could decrease slightly as the validation set is not identical to the test set. The forgetting phase produces three distinct categories of behavior:
- Forget accuracy is very similar to the fine-tuned accuracy.Forget accuracy decreases but is still above the pre-trained accuracy.Forget accuracy decreases to below the pre-trained accuracy and possibly back to 50%.
These results highlight the complex nature of forgetting in LMs and the task-dependent nature of forgetting generalization.
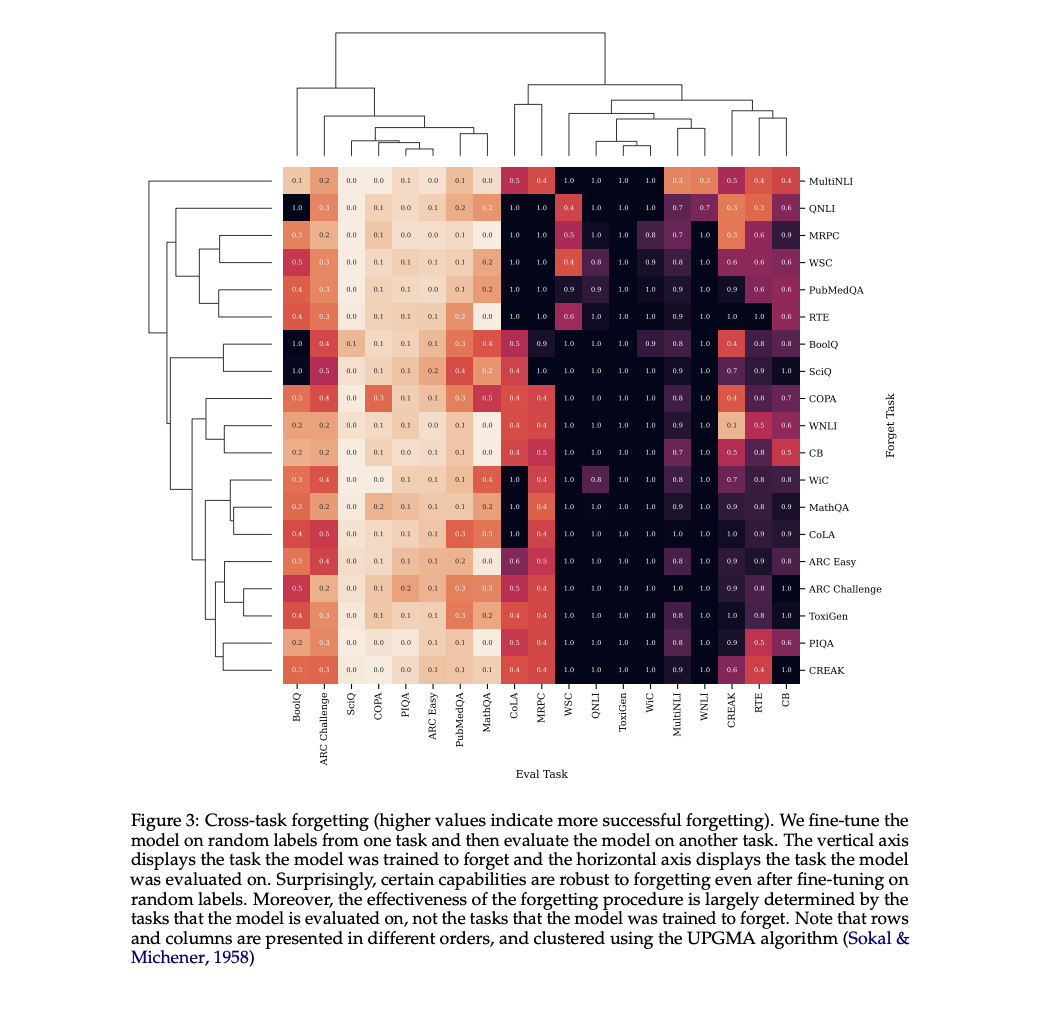
In conclusion, researchers from MIT have introduced an approach for studying the generalization behavior in forgetting skills within LMs. This paper highlights the effectiveness of fine-tuning LMs on randomized responses to induce forgetting of specific capabilities. The evaluation tasks determine the degree of forgetting, and factors like dataset difficulty and model confidence don’t predict how well forgetting occurs. However, the total variance in the model’s hidden states does correlate with the success of forgetting. Future research should aim to understand why certain examples are forgotten within tasks and explore the mechanisms behind the forgetting process.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post This AI Paper from MIT Explores the Complexities of Teaching Language Models to Forget: Insights from Randomized Fine-Tuning appeared first on MarkTechPost.
