

Machine Intelligence Research
新加坡科技研究局和ETH Zurich的研究人员旨在解决视觉Transformer中与多头自注意力(MHSA)相关的高计算/空间复杂度问题。为此,文章提出了分层多头自注意力(H-MHSA),这是一种全新的分层式计算自注意力的方法。具体来说,研究人员首先把输入图像分成固定大小的像素块,其中每一个像素块被视为一个token。而后,本文所提出的H-MHSA从局部的像素块中学习token间的关系,为局部关系建模。接下来,小的像素块被合并成更大的像素块,H-MHSA再为合并而成的数量不多的token进行全局依赖性建模。最后,对局部的和全局的注意力特征进行汇总,以获得具有强大表征能力的特征。因为研究人员在每一步只计算有限数量token的注意力,所以计算量大大减少。因此,H-MHSA可以在不丢失细粒度信息的前提下,有效地对token之间的全局关系进行建模。在引入H-MHSA模块的前提下,研究人员搭建了一个基于分层注意力的Transformer网络,命名为HAT-Net。为了证明HAT-Net在场景理解方面的优越性,研究者们在各种基本视觉任务上做了大量的实验,包括图像分类、语义分割、物体检测和实物分割。因此,HAT-Net为视觉Transformer提供了一个新的视角。代码和预训练模型可在https://github.com/yun-liu/HAT-Net获得。
图片来自Springer
全文下载:
Vision Transformers with Hierarchical Attention
Yun Liu, Yu-Huan Wu, Guolei Sun, Le Zhang, Ajad Chhatkuli & Luc Van Gool
https://link.springer.com/article/10.1007/s11633-024-1393-8
https://www.mi-research.net/article/doi/10.1007/s11633-024-1393-8
在过去的十年里,卷积神经网络(CNNs)已经成为计算机视觉中的首选架构,这归功于其从图像/视频中学习表征的强大能力。同时,在自然语言处理(NLP)领域,Transformer架构已经成为了处理长距依赖关系的业界标准。Transformer高度依赖自注意力机制去对序列数据的全局关系进行建模。尽管全局建模对于视觉任务来说也是非常重要的,但是2D/3D的视觉数据结构使应用Transformer变得不那么简单。而这种困境近期已经被Dosovitskiy等人攻破,他们将一种纯Transformer模型应用于处理图像像素块的序列。
受此启发,大量关于视觉Transformer的研究相继涌现,以解决由计算机视觉和自然语言处理两大领域之间的差距所引起的问题。本文认为,视觉Transformer的一个主要问题是像素块的序列长度比NLP中的文本token更长,因此在计算MHSA时带来了更高的计算/空间复杂度。为了解决这个问题,人们做出了很多努力。
ToMe通过使用一种通用的、轻量化的匹配算法,系统地合并相似的token,以此提高现有视觉Transformer模型的吞吐量。金字塔视觉Transformer(PVT)和多尺度视觉Transformer(MViT)通过特征下采样的方式来减少注意力计算时的token的数量,但却丢失了细粒度的详细信息。SwinTransformer在小窗口中计算注意力以对局部关系进行建模,并通过移动窗口和堆叠更多网络层的方法来逐渐扩大感受野。从这点来看,SwinTransformer的表现可能依旧欠佳,因为它和CNNs的工作方式相似,需要堆叠很多网络层来对长距依赖关系进行建模。
在对基于下采样的Transformer和基于窗口的Transformer进行讨论后可发现,每一种方法都有其独特的优点,本文研究者旨在充分利用和整合这些优点。基于下采样的Transformer优于直接对全局依赖关系进行建模,只不过可能会丢失细粒度信息;相比之下,基于窗口的Transformer可以有效捕捉局部依赖关系,但也可能会在全局依赖建模中落于下风。大家广为接受的是,全局和局部的信息对于视觉场景理解都是必要的。受此观点启发,本研究试图集成这两种范式的优点,从而能直接对全局和局部依赖关系进行建模。
为了实现这一点,本文构建了多层级多头自注意力框架(H-MHSA),这是一种可以在Transformer中提高自注意力计算灵活性与效率的新机制。本文的研究方法首先把图像划分成像素块,并把每个像素块作为一个token。与以往计算所有像素块的注意力不同的是,本文研究者进一步把这些像素块组成小的网格,在每个网格中进行注意力计算。这一步有助于捕获局部关系、并生成更有判别力的局部表征。
而后,研究人员把这些小的像素块合并成更大的像素块,再把合并后的像素块作为新的token,这样可以大大减少token的数量。这使得可以通过计算新token的自注意力来对全局依赖关系进行直接建模。最后,局部和全局的多层级的注意力特征被聚合到一起,产生具有丰富粒度的强大特征。值得注意的是,由于每一步注意力计算都限制在少量token当中,因此本文所提出的多层级策略降低了普通Transformer中的计算/空间复杂度。通过经验判断可以看到多层级自注意力机制的有效性,同时在实验中也验证了该机制的优良性能。
通过简单地应用H-MHSA,本文研究者们建立了一系列基于分层注意力的Transformer网络(HAT-Net)。为了评估HAT-Net在场景理解方面的性能,研究人员在多个基础视觉任务上对HAT-Net进行了实验,包括图像分类、语义分割、物体检测和实物分割。实验结果表明,相较于此前的主流网络,HAT-Net的表现更优。由于H-MHSA源于一个非常简单易懂的想法,因此H-MHSA有望为未来设计视觉Transformer提供一个新的角度。
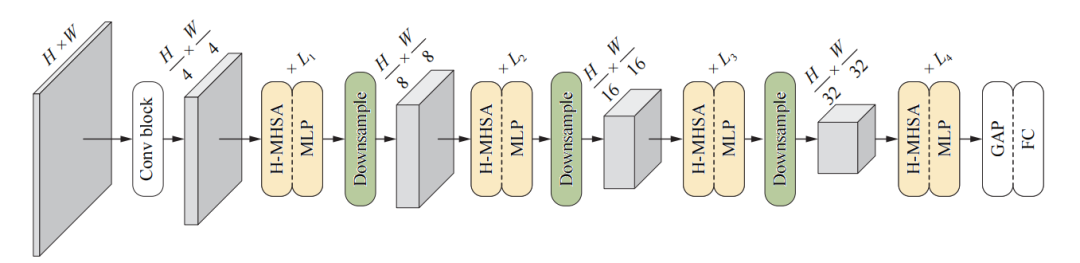
图1 本文所提出的HAT-Net的示意图

全文下载:
Vision Transformers with Hierarchical Attention
Yun Liu, Yu-Huan Wu, Guolei Sun, Le Zhang, Ajad Chhatkuli & Luc Van Gool
https://link.springer.com/article/10.1007/s11633-024-1393-8
https://www.mi-research.net/article/doi/10.1007/s11633-024-1393-8
BibTex:
@Article{MIR-2023-09-178,
author={Yun Liu, Yu-Huan Wu, Guolei Sun, Le Zhang, Ajad Chhatkuli, Luc Van Gool},
journal={Machine Intelligence Research},
title={Vision Transformers with Hierarchical Attention},
year={2024},
volume={21},
issue={4},
pages={670-683},
doi={10.1007/s11633-024-1393-8}}
MIR为所有读者提供免费寄送纸刊服务,如您对本篇文章感兴趣,请点击下方链接填写收件地址,编辑部将尽快为您免费寄送纸版全文!
说明:如遇特殊原因无法寄达的,将推迟邮寄时间,咨询电话010-82544737
收件信息登记:
https://www.wjx.cn/vm/eIyIAAI.aspx#
关于Machine Intelligence Research
Machine Intelligence Research(简称MIR,原刊名International Journal of Automation and Computing)由中国科学院自动化研究所主办,于2022年正式出版。MIR立足国内、面向全球,着眼于服务国家战略需求,刊发机器智能领域最新原创研究性论文、综述、评论等,全面报道国际机器智能领域的基础理论和前沿创新研究成果,促进国际学术交流与学科发展,服务国家人工智能科技进步。期刊入选"中国科技期刊卓越行动计划",已被ESCI、EI、Scopus、中国科技核心期刊、CSCD等20余家国际数据库收录,入选图像图形领域期刊分级目录-T2级知名期刊。2022年首个CiteScore分值在计算机科学、工程、数学三大领域的八个子方向排名均跻身Q1区,最佳排名挺进Top 4%,2023年CiteScore分值继续跻身Q1区。2024年获得首个影响因子(IF) 6.4,位列人工智能及自动化&控制系统两个领域JCR Q1区。

