


Adapting 2D-based segmentation models to effectively process and segment 3D data presents a significant challenge in the field of computer vision. Traditional approaches often struggle to preserve the inherent spatial relationships in 3D data, leading to inaccuracies in segmentation. This challenge is critical for advancing applications like autonomous driving, robotics, and virtual reality, where a precise understanding of complex 3D environments is essential. Addressing this challenge requires a method that can accurately maintain the spatial integrity of 3D data while offering robust performance across diverse scenarios.
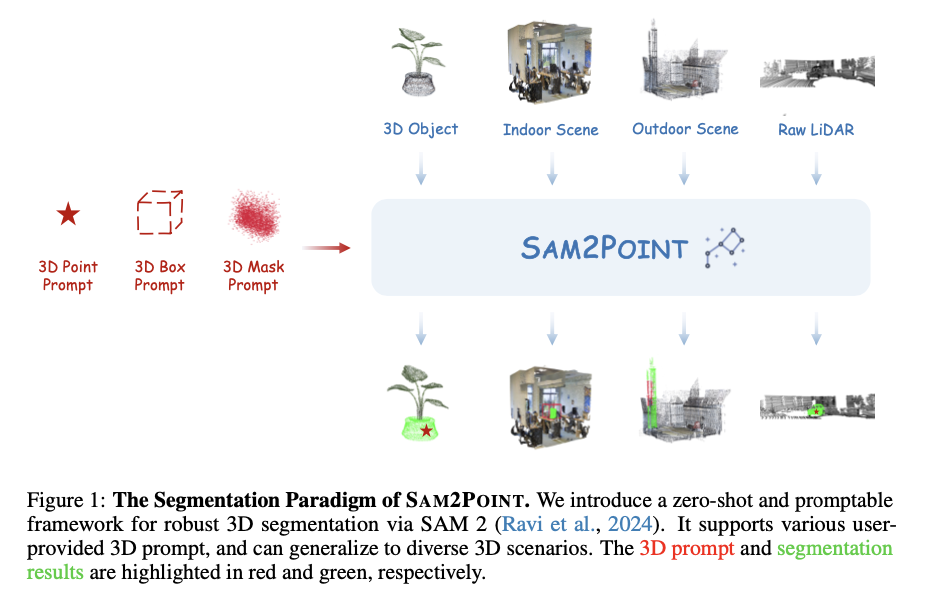
Current methods for 3D segmentation involve transitioning 3D data into 2D forms, such as multi-view renderings or Neural Radiance Fields (NeRF). While these approaches extend the capabilities of 2D models like the Segment Anything Model (SAM), they face several limitations. The 2D-3D projection process introduces significant computational complexity and processing delays. Moreover, these methods often result in the degradation of fine-grained 3D spatial details, leading to less accurate segmentation. Another critical drawback is the limited flexibility in prompting, as translating 2D prompts into precise 3D interactions remains a challenge. Additionally, these techniques struggle with domain transferability, making them less effective when applied across varied 3D environments, such as shifting from object-centric to scene-level segmentation.
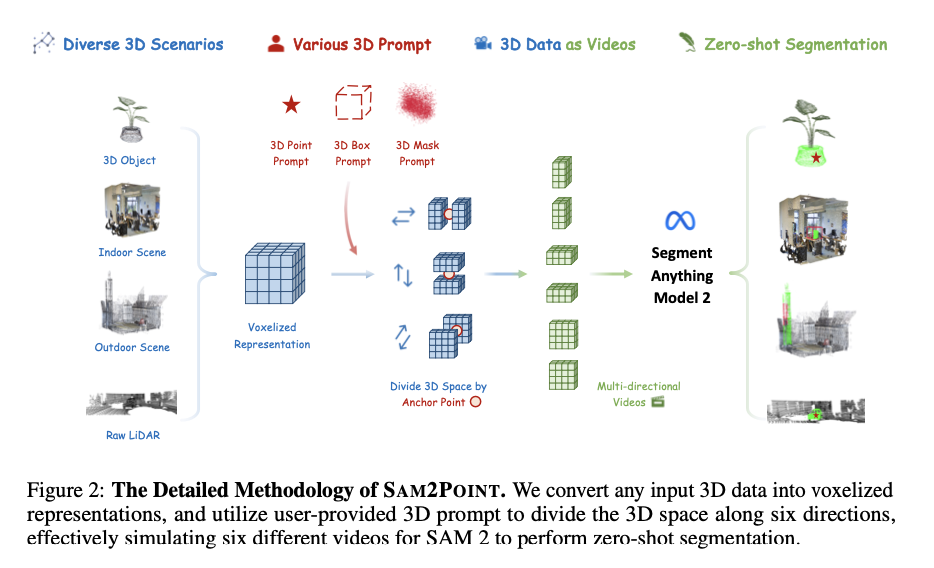
A team of researchers from CUHK MiuLar Lab, CUHK MMLab, ByteDance, and Shanghai AI Laboratory introduce SAM2POINT, a novel approach that adapts the Segment Anything Model 2 (SAM 2) for zero-shot and promptable 3D segmentation without requiring 2D-3D projection. SAM2POINT interprets 3D data as a series of multi-directional videos by using voxelization, which maintains the integrity of 3D geometries during segmentation. This method allows for efficient and accurate segmentation by processing 3D data in its native form, significantly reducing complexity and preserving essential spatial details. SAM2POINT supports various prompt types, including 3D points, bounding boxes, and masks, enabling interactive and flexible segmentation across different 3D scenarios. This innovative approach represents a major advancement by offering a more efficient, accurate, and generalizable solution compared to existing methods, demonstrating robust capabilities in handling diverse 3D data types, such as objects, indoor scenes, outdoor scenes, and raw LiDAR data.

At the core of SAM2POINT’s innovation is its ability to format 3D data into voxelized representations resembling videos, allowing SAM 2 to perform zero-shot segmentation while preserving fine-grained spatial information. The voxelized 3D data is structured as w×h×l×3, where each voxel corresponds to a point in the 3D space. This structure mimics the format of video frames, enabling SAM 2 to segment 3D data similarly to how it processes 2D videos. SAM2POINT supports three types of prompts—3D point, 3D box, and 3D mask—which can be applied either separately or together to guide the segmentation process. For instance, the 3D point prompt divides the 3D space into six orthogonal directions, creating multiple video-like sections that SAM 2 segments individually before integrating the results into a final 3D mask. This method is particularly effective in handling various 3D scenarios, as it preserves the essential spatial relationships within the data.
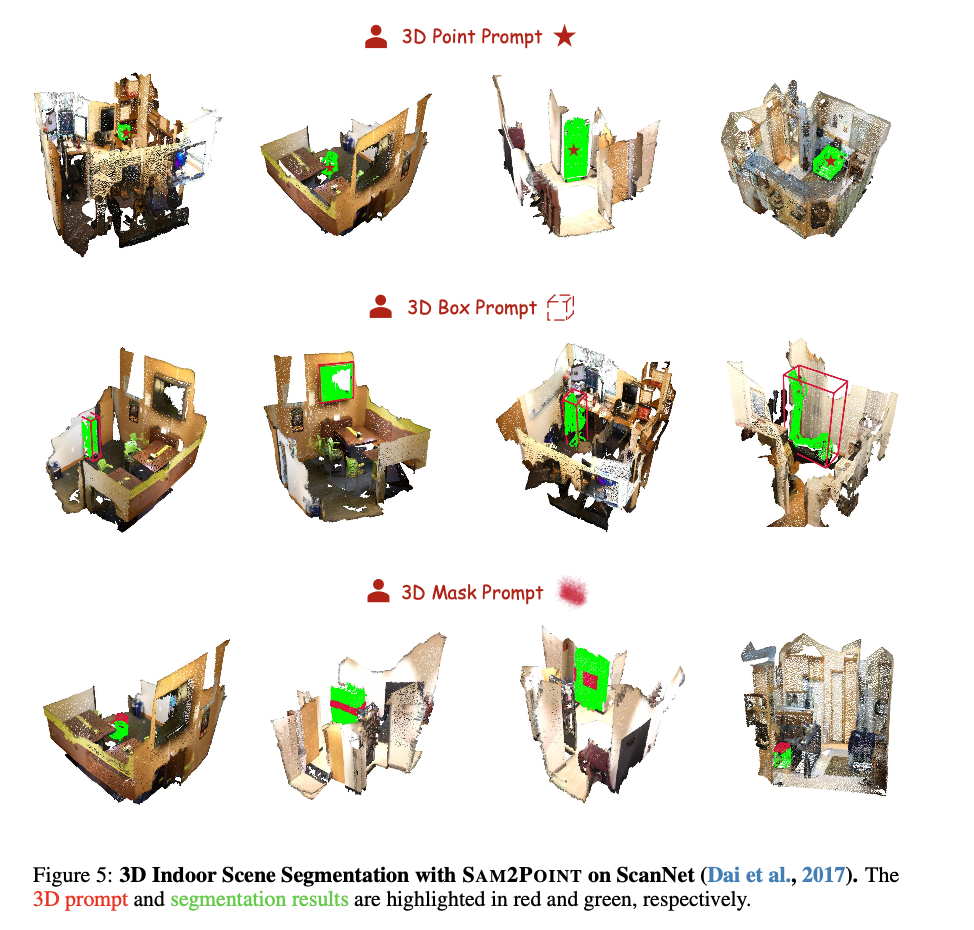
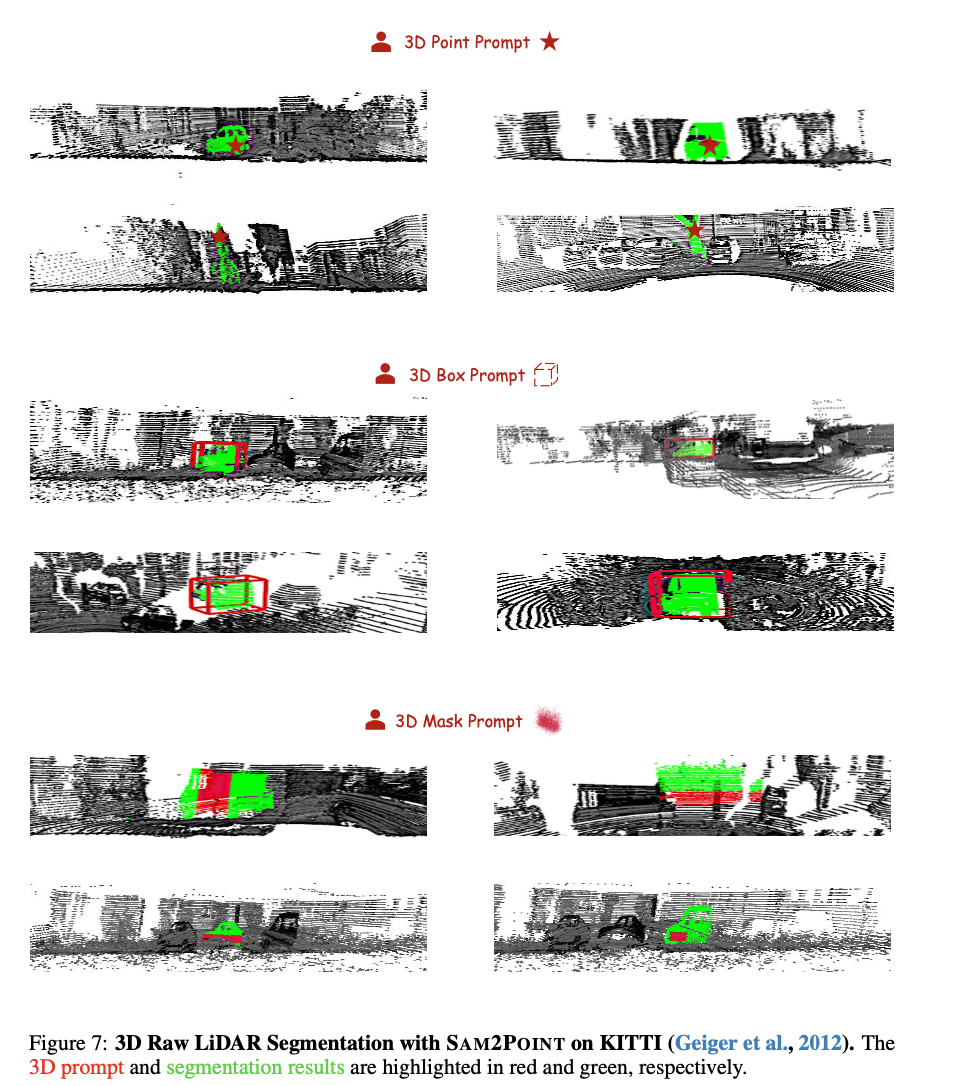
SAM2POINT demonstrates robust performance in zero-shot 3D segmentation across various datasets, including Objaverse, S3DIS, ScanNet, Semantic3D, and KITTI. The method effectively supports multiple prompt types such as 3D points, bounding boxes, and masks, showcasing its flexibility in different 3D scenarios like objects, indoor scenes, outdoor environments, and raw LiDAR data. SAM2POINT outperforms existing SAM-based approaches by preserving fine-grained spatial information without the need for 2D-3D projection, leading to more accurate and efficient segmentation. Its ability to generalize across different datasets without retraining highlights its versatility, providing significant improvements in segmentation accuracy and reducing computational complexity. This zero-shot capability and promptable interaction make SAM2POINT a powerful tool for 3D understanding and efficiently handling large-scale and diverse 3-D data.
In conclusion, SAM2POINT presents a groundbreaking approach to 3D segmentation by leveraging the capabilities of SAM 2 within a novel framework that interprets 3D data as multi-directional videos. This approach successfully addresses the limitations of existing methods, particularly in terms of computational efficiency, preservation of 3D spatial information, and flexibility in user interaction through various prompts. SAM2POINT’s robust performance across diverse 3D scenarios marks a significant contribution to the field, paving the way for more effective and scalable 3D segmentation solutions in AI research. This work not only enhances the understanding of 3D environments but also sets a new standard for future research in promptable 3D segmentation.
Check out the Paper, GitHub, and Demo. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post SAM2Point: A Preliminary Exploration Adapting Segment Anything Model 2 (SAM 2) for Zero-Shot and Promptable 3D Segmentation appeared first on MarkTechPost.
