


Artificial intelligence (AI) has increasingly relied on vast and diverse datasets to train models. However, a major issue has arisen regarding these datasets’ transparency and legal compliance. Researchers and developers often use large-scale data without fully understanding its origins, proper attribution, or licensing terms. As AI continues to expand, these data transparency and licensing gaps pose significant ethical and legal risks, making it crucial to audit and trace the datasets used in model development.
The central problem is the frequent use of unlicensed or improperly documented data in AI model training. Many datasets, especially those used for fine-tuning AI models, come from sources that do not provide clear licensing information. This results in high rates of misattribution or non-compliance with data usage terms. The risks associated with such practices are severe, including exposure to legal action, as models trained on unlicensed data might violate copyright laws. Moreover, these issues raise ethical concerns regarding the use of data, particularly when it contains personal or sensitive information.
While some platforms attempt to organize and provide dataset licenses, many must do so accurately. Platforms like GitHub and Hugging Face, which host popular AI datasets, often contain incorrect or incomplete license information. Studies have shown that over 70% of licenses on these platforms are unspecified, and nearly 50% contain errors. This leaves developers needing clarification about their legal obligations when using such datasets, which is particularly concerning given the increasing scrutiny of data usage in AI. The widespread lack of transparency not only complicates the development of AI models but also risks producing models that are legally vulnerable.
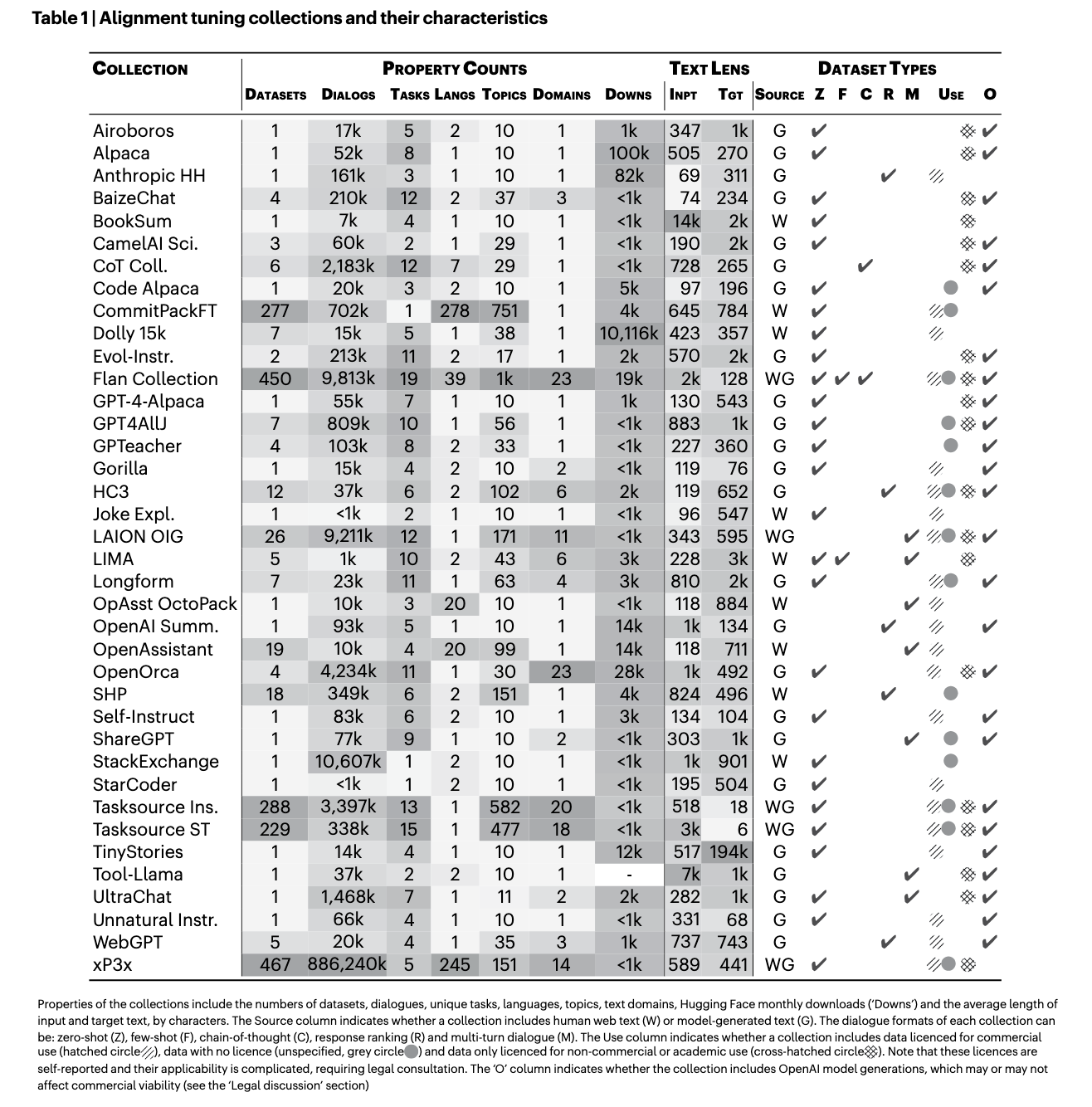
Researchers from institutions like MIT, Google and other leading institutions have introduced the Data Provenance Explorer (DPExplorer) to address these concerns. This innovative tool was designed to help AI practitioners audit and trace the provenance of datasets used for training. The DPExplorer allows users to view the origins, licenses, and usage conditions of over 1,800 popular text datasets. By offering a detailed view of each dataset’s source, creator, and license, the tool empowers developers to make informed decisions and avoid legal risks. This effort was a comprehensive collaborative initiative between legal experts and AI researchers, ensuring that the tool addresses technical and legal aspects of dataset use.
The DPExplorer employs an extensive pipeline to gather and verify metadata from widely used AI datasets. Researchers meticulously audit each dataset, recording details such as the licensing terms, dataset source, and modifications made by previous users. The tool expands on existing metadata repositories like Hugging Face by offering a richer taxonomy of dataset characteristics, including language composition, task type, and text length. Users can filter datasets by commercial or non-commercial licenses and review how datasets have been repackaged and reused in different contexts. The system also auto-generates data provenance cards, summarizing the metadata for easy reference and helping users identify datasets suited to their specific needs while staying within legal boundaries.
In terms of performance, the DPExplorer has already yielded significant results. The tool successfully reduced the number of unspecified licenses from 72% to 30%, marking a substantial improvement in dataset transparency. Out of the datasets audited, 66% of the permits on platforms like Hugging Face were misclassified, with many marked as more permissive than the original author’s license. Furthermore, over 1,800 text datasets were traced for licensing accuracy, which led to a clearer understanding of the legal conditions under which AI models can be developed. The findings reveal a critical divide between datasets licensed for commercial use and those restricted to non-commercial purposes, with the latter being more diverse and creative in content.
The researchers noted that datasets used for commercial purposes often need more diversity of tasks and topics seen in non-commercial datasets. For instance, non-commercial datasets feature more creative and open-ended tasks, such as creative writing and problem-solving. In contrast, commercial datasets often focus more on short text generation and classification tasks. Moreover, 45% of non-commercial datasets were synthetically generated using models like OpenAI’s GPT, while commercial datasets were primarily derived from human-generated content. This stark difference in dataset types and usage indicates the need for more careful licensing consideration when selecting training data for AI models.
In conclusion, the research highlights a significant gap in the licensing and attribution of AI datasets. The introduction of the DPExplorer addresses this challenge by providing developers with a robust tool for auditing and tracing dataset licenses. This ensures that AI models are trained on properly licensed data, reducing legal risks and promoting ethical practices in the field. As AI evolves, tools like the DPExplorer will ensure data is used responsibly and transparently.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post DPExplorer: A Tool for Auditing and Tracing the Provenance of AI Datasets appeared first on MarkTechPost.
