


Large-scale language models have made significant progress in generative tasks involving multiple-speaker speech synthesis, music generation, and audio generation. The integration of speech modality into multimodal unified large models has also become popular, as seen in models like SpeechGPT and AnyGPT. These advancements are largely due to discrete acoustic codec representations used from neural codec models. However, it poses challenges in bridging the gap between continuous speech and token-based language models. While current acoustic codec models offer good reconstruction quality, there is room for improvement in areas like high bitrate compression and semantic depth.
Existing methods focus on three main areas to address challenges in acoustic codec models. The first method includes better reconstruction quality through techniques like AudioDec, which demonstrated the importance of discriminators, and DAC, which improved quality using techniques like quantizer dropout. The second method uses enhanced compression-led developments such as HiFi-Codec’s parallel GRVQ structure and Language-Codec’s MCRVQ mechanism, achieving good performance with fewer quantizers for both. The last method aims to deepen the understanding of codec space with TiCodec modeling time-independent and time-dependent information, while FACodec separates content, style, and acoustic details.
A team from Zhejiang University, Alibaba Group, and Meta’s Fundamental AI Research have proposed WavTokenizer, a novel acoustic codec model, that offers significant advantages over previous state-of-the-art models in the audio domain. WavTokenizer achieves extreme compression by reducing the layers of quantizers and the temporal dimension of the discrete codec, with only 40 or 75 tokens for one second of 24kHz audio. Moreover, its design contains a broader VQ space, extended contextual windows, improved attention networks, a powerful multi-scale discriminator, and an inverse Fourier transform structure. It demonstrates strong performance, in various domains like speech, audio, and music.
The architecture of WavTokenizer is designed for unified modeling across domains like multilingual speech, music, and audio. Its large version is trained on approximately 80,000 hours of data from various datasets, including LibriTTS, VCTK, CommonVoice, etc. Its medium version uses a 5,000-hour subset, while the small version is trained on 585 hours of LibriTTS data. The WavTokenizer’s performance is evaluated against state-of-the-art codec models using official weight files from various frameworks such as Encodec 2, HiFi-Codec 3, etc. It is trained on NVIDIA A800 80G GPUs, with input samples of 24 kHz. The optimization of the proposed model is done using the AdamW optimizer with specific learning rate and decay settings.
The results demonstrated the outstanding performance of WavTokenizer across various datasets and metrics. The WavTokenizer-small outperforms the state-of-the-art DAC model by 0.15 on the UTMOS metric and the LibriTTS test-clean subset, which closely aligns with human perception of audio quality. Moreover, this model outperforms DAC’s 100-token model across all metrics with only 40 and 75 tokens, proving its effectiveness in audio reconstruction with a single quantizer. The WavTokenizer performs comparably to Vocos with 4 quantizers and SpeechTokenizer with 8 quantizers on objective metrics like STOI, PESQ, and F1 score.
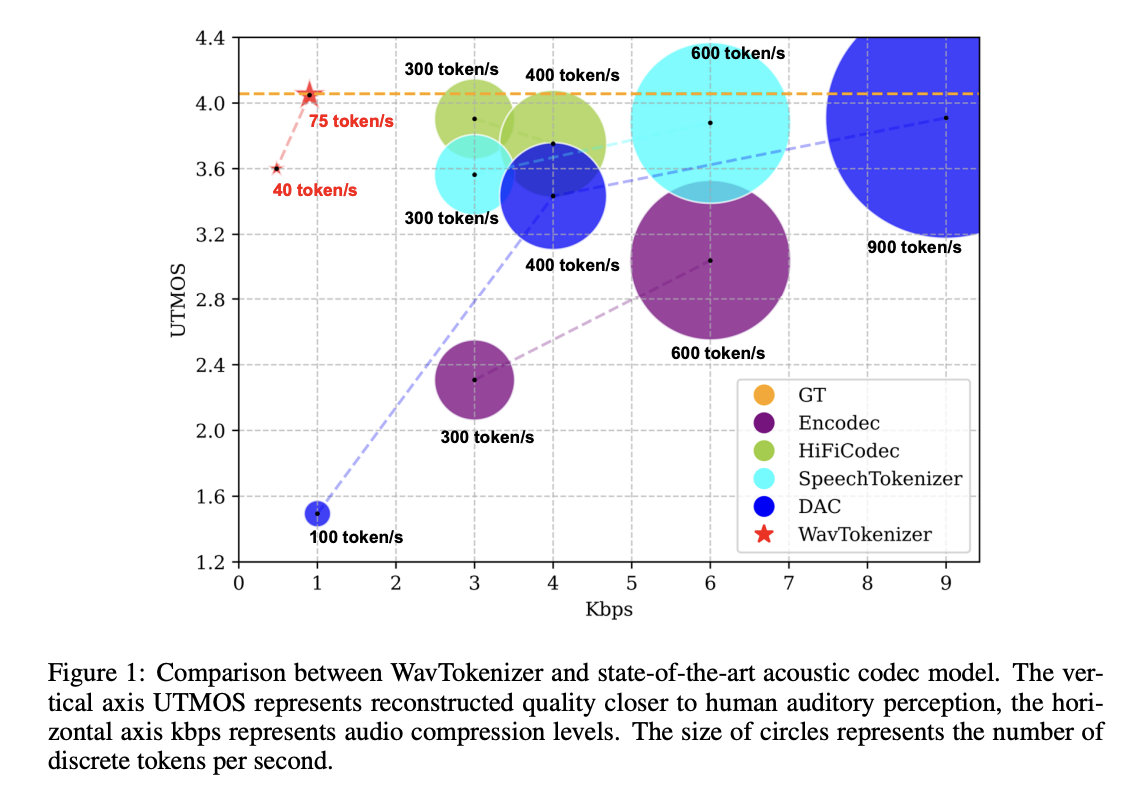
In conclusion, WavTokenizer shows a significant advancement in acoustic codec models, capable of quantizing one second of speech, music, or audio into just 75 or 40 high-quality tokens. This model achieves results comparable to existing models on the LibriTTS test-clean dataset while offering extreme compression. The team conducted a comprehensive analysis of the design motivations behind the VQ space and decoder and validated the importance of each new module through ablation studies. The findings show that the WavTokenizer has the potential to revolutionize audio compression and reconstruction across various domains. In the future, researchers plan to solidify WavTokenizer’s position as a cutting-edge solution in the field of acoustic codec models.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Here is a highly recommended webinar from our sponsor: ‘Building Performant AI Applications with NVIDIA NIMs and Haystack’
The post WavTokenizer: A Breakthrough Acoustic Codec Model Redefining Audio Compression appeared first on MarkTechPost.
