


Large Language Models (LLMs) have made remarkable strides in multimodal capabilities, with closed-source models like GPT-4, Claude, and Gemini leading the field. However, the challenge lies in democratizing AI by making these powerful models accessible to a broader audience. The current limitation is the substantial computational resources required to run state-of-the-art models effectively. This creates a significant barrier for developers and researchers with limited access to high-end hardware. Also, The need for efficient models that can operate on smaller compute footprints has become increasingly apparent, as it would enable wider adoption and application of AI technologies across various domains and devices.
Multimodal Large Language Models (MM-LLMs) have rapidly evolved since the introduction of Flamingo, which marked a significant milestone in the field. LLaVa emerged as a prominent open-source framework, innovating by using text-only GPT models to expand multimodal datasets. Its architecture, featuring a pre-trained image encoder connected to a pre-trained LLM via an MLP, inspired numerous variants and applications across different domains. Small MM-LLMs like TinyLLaVa and LLaVa-Gemma were developed using this framework, addressing the need for more efficient models.
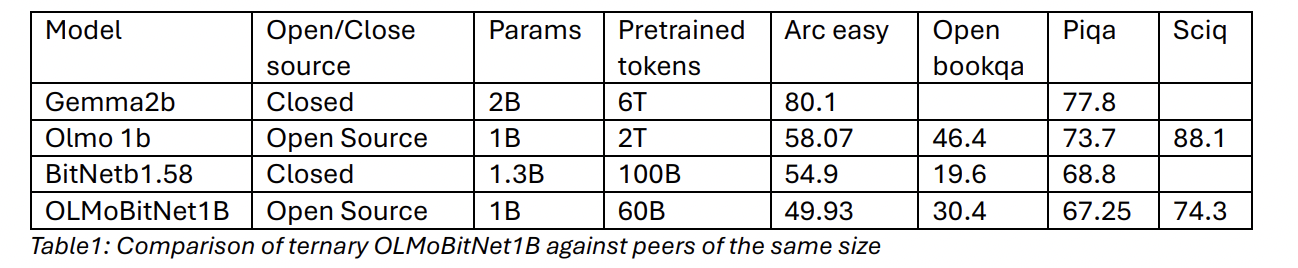
Concurrently, research into model compression led to major leaps like BitNetb1.58, which introduced ternary weight quantization. This method, involving pre-training with low-precision weights, demonstrated significant latency improvements with minimal accuracy loss. NousResearch’s OLMoBitNet1B further validated this approach by open-sourcing a ternary version of OLMo, although it remains undertrained compared to its peers. These advancements in both multimodal capabilities and model compression set the stage for further innovations in efficient, high-performance AI models.
Building upon NousResearch’s pioneering work, Intel researchers have developed the first Ternary Multimodal Large Language Model (TM-LLM) capable of processing both image and text inputs to generate coherent textual responses. This unique approach extends the capabilities of ternary models beyond text-only applications, opening new avenues for efficient multimodal AI. The team has open-sourced the model, including weights and training scripts, to facilitate further research and development in ternary models. By addressing the challenges associated with ternary quantization in multimodal contexts and highlighting potential opportunities, this work aims to pave the way for the mainstream adoption of highly efficient, compact AI models that can handle complex multimodal tasks with minimal computational resources.
The proposed model LLaVaOLMoBitNet1B integrates three key components: an ACLIP ViT-L/14 vision encoder, an MLP connector, and a ternary LLM. The vision encoder processes input images by dividing them into 14×14 non-overlapping patches, passing them through 24 transformer layers with a hidden dimension of 1024. This results in an output of (N, 1024) for each image, where N is the number of patches. The MLP connector then re-projects these image features to match the LLM’s embedding space, using two linear layers with a GELU activation, outputting a tensor of shape (N, 2048).
The core LLM is the ternary OLMoBitNet1B, featuring 16 transformer decoder layers with BitLinear158 layers replacing standard linear layers. This 1.1 billion parameter model was trained on 60B tokens of the Dolma dataset. The input text is tokenized and embedded, then concatenated with the image-projected tensor, creating an (m+n, 2048) tensor for LLM processing. The model generates responses autoregressively based on this combined input context.
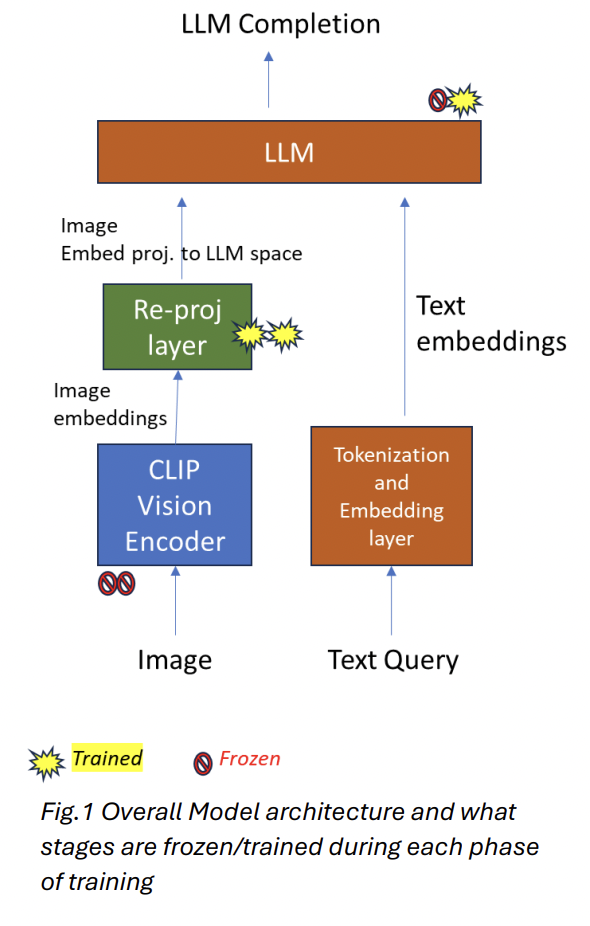
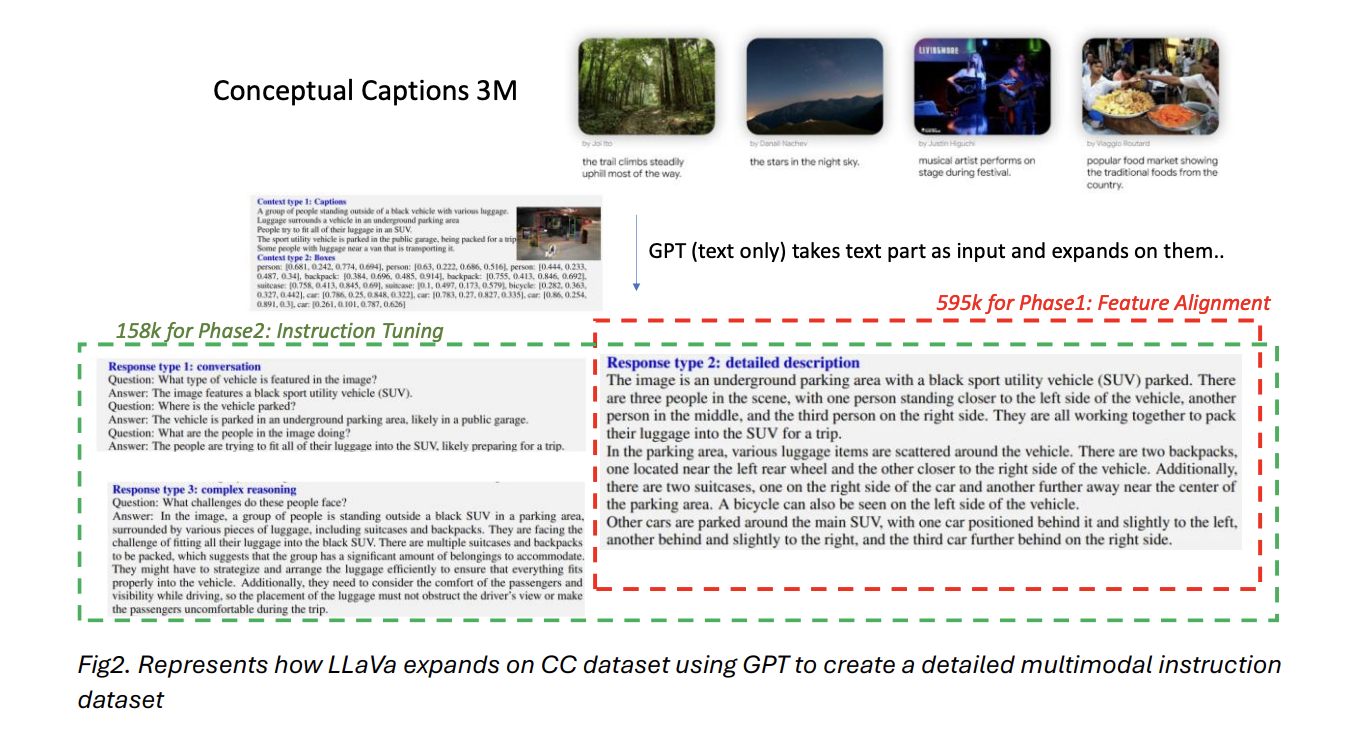
The training approach for LLaVaOLMoBitNet1B follows a two-phase process similar to LLaVa1.5. The first phase, pre-training for feature alignment, utilizes a filtered subset of 595K Conceptual Captions. Only the projection layer weights are updated during this single-epoch training on an A100 cluster. The batch size is set to 32 per device, with gradients accumulated every 4 steps. A learning rate of 1e-3 is used with cosine decay and a 0.03 warmup ratio.
The second phase, end-to-end instruction fine-tuning, employs the LLaVa-Instruct-150K dataset for one epoch. Both the projection layer and LLM weights are updated during this phase. The batch size is reduced to 8, with gradient accumulation every 2 steps, and the learning rate is lowered to 2e-5. Adam optimizer is used with momentum parameters of 0.9 and 0.98. DeepSpeed library facilitates multi-GPU training throughout both phases.
LLaVaOLMoBitNet1B demonstrates promising results in image and text inference tasks. Qualitative evaluations reveal the model’s ability to generate coherent and mostly accurate responses to image-based questions. However, some inaccuracies are observed, such as misidentifying object counts or relative positions. For instance, the model correctly identifies stools and their color in one image but miscounts them. In another case, it provides an accurate description but errs in positioning details.
Quantitative comparisons show that the base LLM, OLMoBitNet1B, underperforms compared to peers due to its limited pre-training on only 60B tokens. This trend extends to LLaVaOLMoBitNet1B when compared to full-precision multimodal models. As the first ternary multimodal LLM, it remains one of the smallest models with the least pre-training exposure. While not currently the strongest performer, LLaVaOLMoBitNet1B establishes a valuable baseline for future development of more capable ternary multimodal models, balancing efficiency with performance.

Ternary models present unique challenges and opportunities in the AI landscape. While leading models are often closed-source or open-weight, the current ternarization approach requires training from scratch, limiting its accessibility to organizations with substantial compute resources. A critical research direction is developing effective post-training quantization methods for open-weight pre-trained models to ternary precision. Also, ternary models face similar challenges as regular LLMs, including response biases, uncertainty, and hallucinations. On the hardware front, there’s a need to optimize ternary operations for maximum performance gains. Future research will focus on addressing these challenges and advancing ternary model capabilities, aiming to democratize efficient, high-performance AI technologies.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Here is a highly recommended webinar from our sponsor: ‘Building Performant AI Applications with NVIDIA NIMs and Haystack’
The post LLaVaOLMoBitnet1B: The First Ternary Multimodal LLM Capable of Accepting Image(s) and Text Inputs to Produce Coherent Textual Response appeared first on MarkTechPost.
