


With the development of huge Large Language Models (LLMs), such as GPT-3 and GPT-4, Natural Language Processing (NLP) has developed incredibly in recent years. Based on their unusual reasoning capabilities, these models can understand and generate human-like text. Reasoning can be broadly differentiated into two kinds: one where specific conclusions are drawn from general principles, called deductive reasoning, and the other where broader generalizations are drawn upon particular examples, called inductive reasoning. Understanding how LLMs handle these two kinds of reasoning is crucial for evaluating their true potential in various applications.
One of the central challenges that NLP faces in this respect is identifying which type of reasoning- deductive or inductive- is more challenging for LLMs. While GPT-3 and GPT-4 perform great, for instance, there has been a raised eyebrow as to whether these models actually reason or simply imitate patterns learned from large data. This paper investigates this question by isolating and analyzing separately the concrete competencies of LLMs on both deductive and inductive reasoning tasks. The current work is going to establish whether LLMs can do basic reasoning or simply use memorized patterns to approximate the answers.
Previous studies used arithmetic, logic puzzles, and language comprehension tasks to investigate the LLM reasoning ability. These works are to be differentiated from deductive and inductive reasoning. Still, both studies from the literature lump them together, making it hard to draw on either individually. Traditional approaches, like using Input-Output (IO) prompting to probe the reasoning capabilities of LLMs, have almost always confounded deductive and inductive abilities within models. As such, it hasn’t been possible to establish whether LLMs are excellent in reasoning or whether they are essentially exploiting learned associations without really comprehending tasks.

A team of researchers at the University of California, Los Angeles, and Amazon responded with a new paradigm termed SolverLearner. This novel framework is based on the core premise of decoupling inductive reasoning from LLM deductive reasoning. SolverLearner has been designed to test the pure inductive reasoning capabilities of LLMs by learning functions mapping inputs to outputs using in-context examples alone. Because it tests only inductive reasoning, SolverLearner gives a better estimate of how well LLMs are able to generalize from particular examples, independent of any internally preprogrammed rules or patterns.
SolverLearner works in two separate phases: function proposal and function execution. In the function proposal, an LLM selects a function that could map input data points to their respective output values. This process can be paralleled with human inductive reasoning when learning new concepts from examples. The uniqueness of SolverLearner is that it separates the learning process of the LLM from influences via deductive reasoning, which is usually combined with traditional methods. Finally, the proposed function is executed during the execution stage using an external code interpreter like Python to assess its accuracy. A division of learning and execution into such stages provides the researchers with an opportunity to isolate and analyze the inductive reasoning capabilities of the LLM in their pure form, devoid of interferences due to its deductive reasoning competencies.
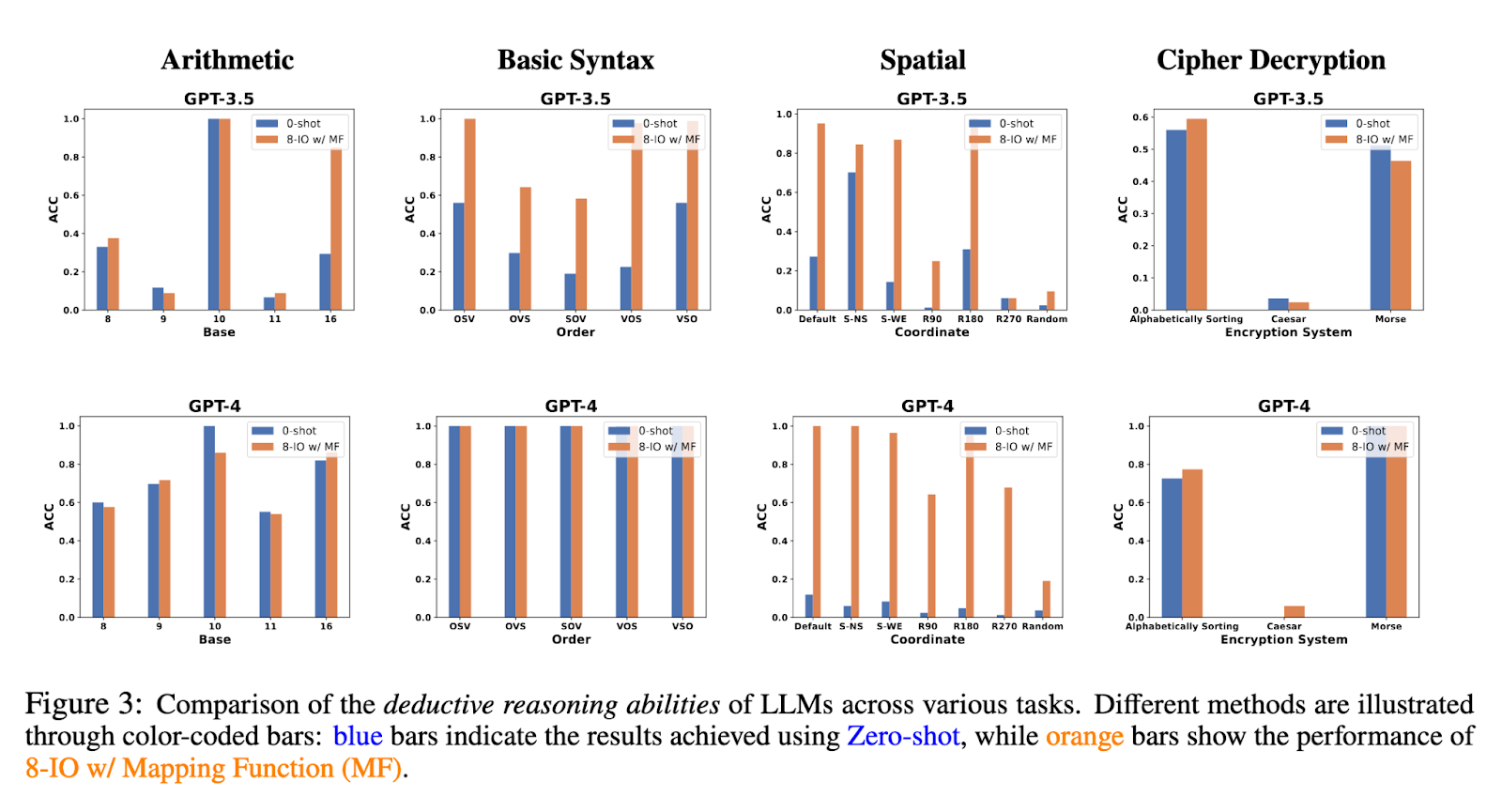
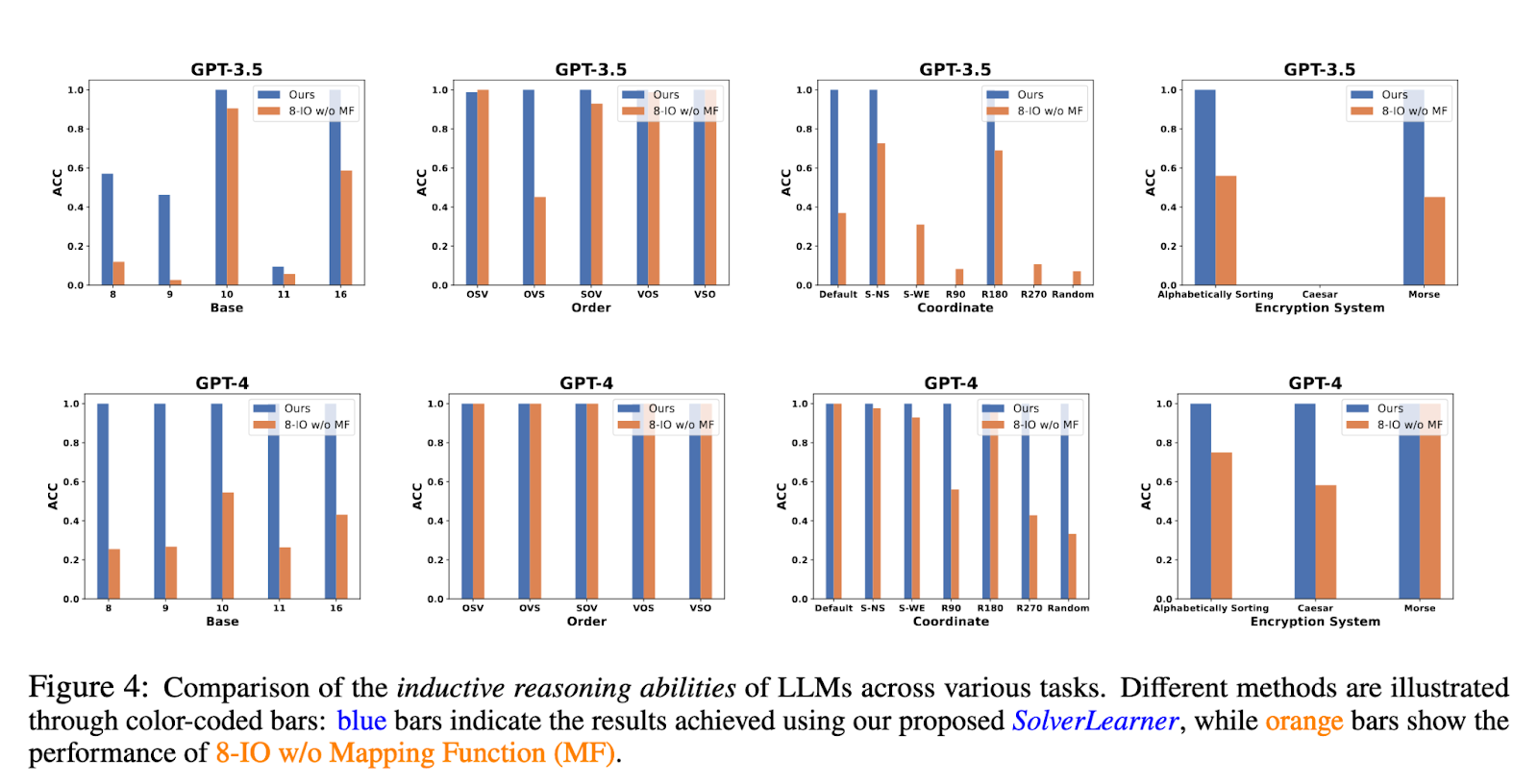
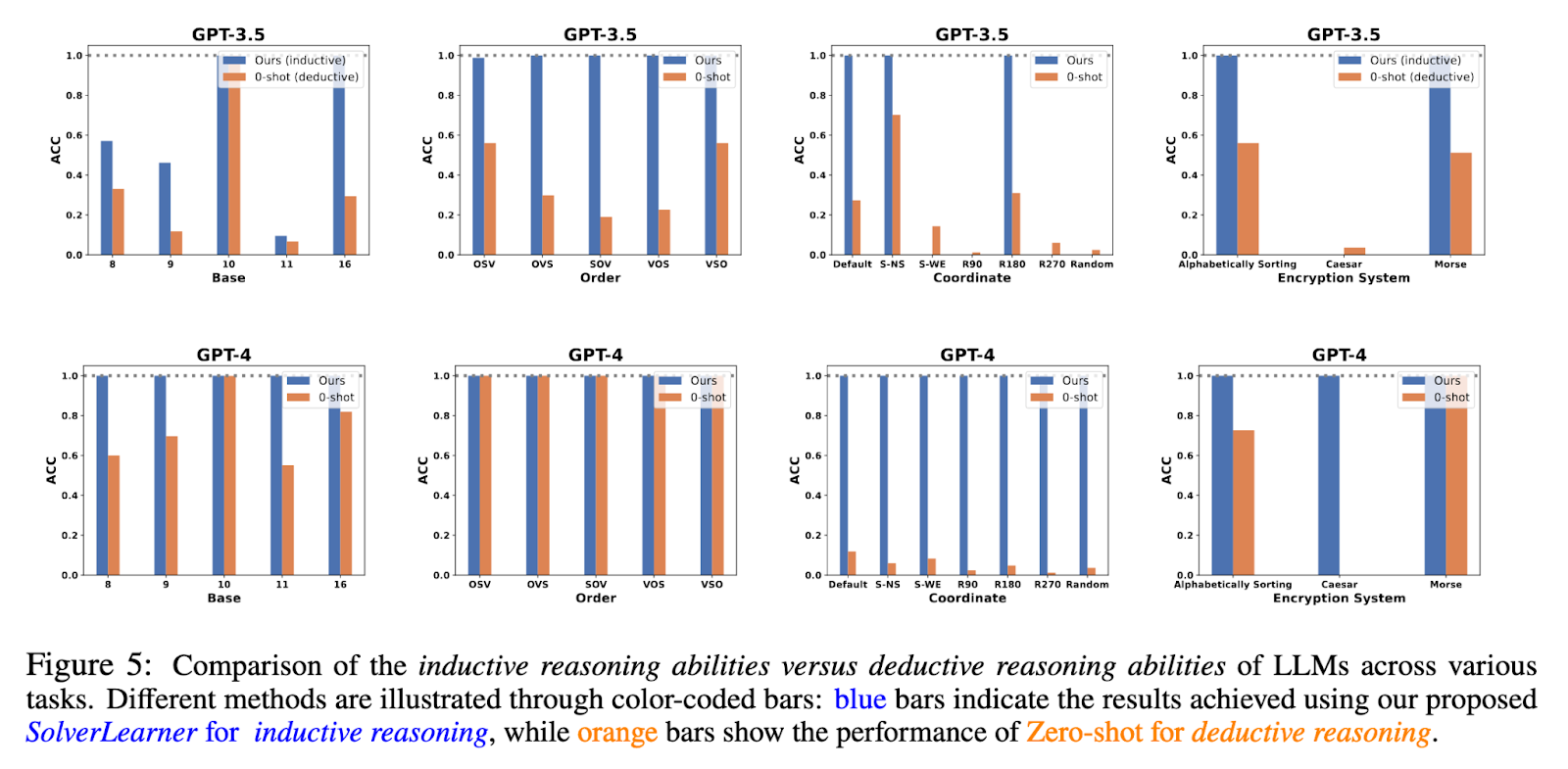
Findings from the study indicate that large language models generally, and GPT-4 specifically, can achieve state-of-the-art inductive reasoning scores when tested by the SolverLearner framework. These results demonstrate that GPT-4 has been consistently maintaining almost flawless accuracy, with an ACC of 1 in most cases, hence always showing a strong generalizing capability from in-context examples. For example, if GPT-4 is tested on arithmetic operations based on different bases, it would correctly infer the base system in which it had to calculate the output without being explicitly told to do so. This would mean that GPT-4 learns the underlying patterns to solve new, unseen problems.
On the other hand, it also presents some significant challenges related to LLMs’ deductive reasoning. While GPT-4 did well in inductive reasoning in this study, the authors point out that in tasks revolving around deductive reasoning, especially in those that require counterfactual abilities since the model has to implement something it learned in situations different from what it had during training, the output remained poor. In particular, when exposed to arithmetic problems in a novel number base, performance dramatically worsened, reflecting weakness in its deductive logic applied to new situations. This striking contrast of the performance in inductive and deductive reasoning tasks further indicates that, even though LLMs like GPT-4 are strong generalizers, such models have an important challenge when reasoning requires strict adherence to logical rules at hand.
This work, therefore, underlines an important insight into the reasoning powers of LLMs. The introduction of the SolverLearner framework allowed researchers to begin to isolate and assess the inductive reasoning powers of LLMs and thus demonstrate a surprising range of strengths they possess. On the other hand, this present study highlights the fact that future research is necessary in order to achieve a much-improved level of LLM deductive reasoning competence, especially on tasks involving the application of learned rules to novel situations. Results showed that while LLMs have indeed achieved remarkable progress in NLP, much work is still to be done to fully comprehend and enhance their reasoning capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Here is a highly recommended webinar from our sponsor: ‘Building Performant AI Applications with NVIDIA NIMs and Haystack’
The post SolverLearner: A Novel AI Framework for Isolating and Evaluating the Inductive Reasoning Capabilities of LLMs appeared first on MarkTechPost.
