


Empowering LLMs to handle long contexts effectively is essential for many applications, but conventional transformers require substantial resources for extended context lengths. Long contexts enhance tasks like document summarization and question answering. Yet, several challenges arise: transformers’ quadratic complexity increases training costs, LLMs need help with longer sequences even after fine-tuning, and obtaining high-quality long-text datasets is difficult. To mitigate these issues, methods like modifying attention mechanisms or token compression have been explored, but they often result in information loss, hindering precise tasks like verification and question answering.
Researchers from Tsinghua and Xiamen Universities introduced FocusLLM, a framework designed to extend the context length of decoder-only LLMs. FocusLLM divides long text into chunks and uses a parallel decoding mechanism to extract and integrate relevant information. This approach enhances training efficiency and versatility, allowing LLMs to handle texts up to 400K tokens with minimal training costs. FocusLLM outperforms other methods in tasks like question answering and long-text comprehension, demonstrating superior performance on Longbench and ∞-Bench benchmarks while maintaining low perplexity on extensive sequences.
Recent advancements in long-context modeling have introduced various approaches to overcome transformer limitations. Length extrapolation methods, like positional interpolation, aim to adapt transformers to longer sequences but often struggle with distractions from noisy content. Other methods modify attention mechanisms or use compression to manage long texts but fail to utilize all tokens effectively. Memory-enhanced models improve long-context comprehension by integrating information into persistent memory or encoding and querying long texts in segments. However, these methods face limitations in memory length extrapolation and high computational costs, whereas FocusLLM achieves greater training efficiency and effectiveness on extremely long texts.
The methodology behind FocusLLM involves adapting the LLM architecture to handle extremely long text sequences. FocusLLM segments the input into chunks, each processed by an augmented decoder with additional trainable parameters. Local context is appended to each chunk, allowing for parallel decoding, where candidate tokens are generated simultaneously across chunks. This approach reduces computational complexity significantly, particularly with long sequences. FocusLLM’s training uses an auto-regressive loss, focusing on predicting the next token, and employs two loss functions—Continuation and Repetition loss—to improve the model’s ability to handle diverse chunk sizes and contexts.
The evaluation of FocusLLM highlights its strong performance in language modeling and downstream tasks, especially with long-context inputs. Trained efficiently on 8×A100 GPUs, FocusLLM surpasses LLaMA-2-7B and other fine-tuning-free methods, maintaining stable perplexity even with extended sequences. On downstream tasks using Longbench and ∞-Bench datasets, it outperformed models like StreamingLLM and Activation Beacon. FocusLLM’s design, featuring parallel decoding and efficient chunk processing, enables it to handle long sequences effectively without the computational burden of other models, making it a highly efficient solution for long-context tasks.
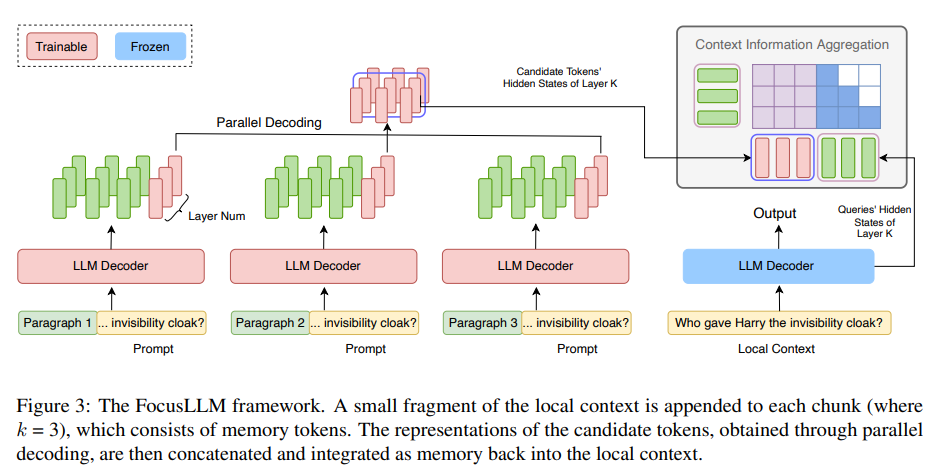
In conclusion, FocusLLM introduces a framework that significantly extends the context length of LLMs by utilizing a parallel decoding strategy. This approach divides long texts into manageable chunks, extracting essential information from each and integrating it into the context. FocusLLM performs superior downstream tasks while maintaining low perplexity, even with sequences up to 400K tokens. Its design allows for remarkable training efficiency, enabling long-context processing with minimal computational and memory costs. This framework offers a scalable solution for enhancing LLMs, making it a valuable tool for long-context applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
The post FocusLLM: A Scalable AI Framework for Efficient Long-Context Processing in Language Models appeared first on MarkTechPost.
