


Retrieval Augmented Generation (RAG) represents a cutting-edge advancement in Artificial Intelligence, particularly in NLP and Information Retrieval (IR). This technique is designed to enhance the capabilities of Large Language Models (LLMs) by seamlessly integrating contextually relevant, timely, and domain-specific information into their responses. This integration allows LLMs to perform more accurately and effectively in knowledge-intensive tasks, especially where proprietary or up-to-date information is crucial. RAG has gained significant attention because it addresses the need for more precise, context-aware outputs in AI-driven systems. This requirement becomes increasingly important as the complexity of tasks and user queries rises.
One of the most significant challenges in current RAG systems lies in effectively synthesizing information from large and diverse datasets. These datasets often contain a substantial amount of noise, which can either be intrinsic to the task at hand or a result of the lack of standardization across various documents, which may come in different formats like PDFs, PowerPoint presentations, or Word documents. Document chunking, breaking down documents into smaller parts for processing, can lead to a loss of semantic context, making it difficult for retrieval models to extract and use relevant information effectively. This issue is compounded when dealing with user queries that are typically short, ambiguous, or complex, requiring a retrieval system capable of high-level reasoning across multiple documents.
Traditional RAG pipelines generally follow a retrieve-then-read framework, where a retriever searches for document chunks related to a user’s query and then provides these chunks as context for the LLM to generate a response. These pipelines often use a dual-encoder dense retrieval model, which encodes the query and the documents into a high-dimensional vector space and measures their similarity by computing the inner product. However, this method has several limitations, particularly because the retrieval process is often unsupervised and needs more human-labeled relevance information. As a result, the quality of the retrieved context can vary significantly, leading to less precise and sometimes irrelevant answers. The choice of document chunking strategy is critical, affecting the information retained and the context maintained during retrieval.
The research team from Amazon Web Services introduced a novel data-centric workflow that significantly advances the traditional RAG system. This new approach transforms the existing pipeline into a more sophisticated prepare-then-rewrite-then-retrieve-then-read framework. The key innovations in this methodology include generating metadata and synthetic Question and Answer (QA) pairs for each document and introducing the concept of a Meta Knowledge Summary (MK Summary). The MK Summary involves clustering documents based on metadata, allowing for more personalized user-query augmentation and enabling deeper and more accurate information retrieval across the knowledge base. This approach marks a significant shift from simply retrieving and reading document chunks to a more comprehensive method that better prepares, rewrites, and retrieves information to match the user’s query.
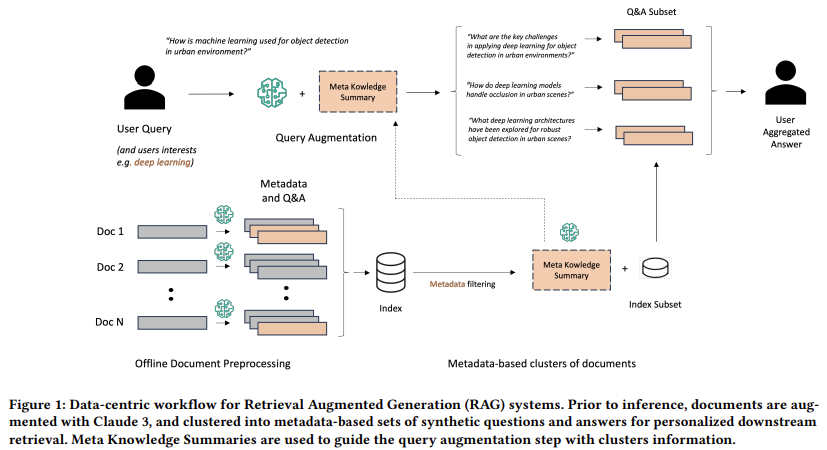
The proposed methodology processes documents by generating custom metadata and QA pairs using advanced LLMs, such as Claude 3 Haiku. For instance, in their study, the researchers generated 8,657 QA pairs from 2,000 research documents, with the average cost of processing each document being approximately $20. These synthetic QAs are then used to augment user queries, allowing the system to reason across multiple documents rather than relying on isolated chunks. The MK Summary further refines this process by summarizing key concepts across documents tagged with similar metadata, significantly enhancing the retrieval process’s precision and relevance. This approach is designed to be cost-effective and easily applicable to new datasets, making it a versatile solution for various knowledge-intensive applications.

In their evaluation, the research team demonstrated that their new approach significantly outperforms traditional RAG systems in several key metrics. Specifically, the augmented queries using synthetic QAs and MK Summaries achieved higher retrieval precision, recall, specificity, and overall quality of the responses. For example, the recall rate was improved from 77.76% in traditional systems to 88.39% using their method, while the breadth of the search increased by over 20%. The system’s ability to generate more relevant and specific responses was enhanced, with relevancy scores reaching 90.22%, compared to lower scores in traditional methods.

In conclusion, the research team’s innovative approach to Retrieval Augmented Generation addresses the key challenges associated with traditional RAG systems, particularly the issues of document chunking and query underspecification. By leveraging metadata and synthetic QAs, their data-centric methodology significantly enhances retrieval, resulting in more precise, relevant, and comprehensive responses. This advancement improves the quality of AI-driven information systems and offers a cost-effective and scalable solution that can be applied across various domains. As AI continues to evolve, such innovative approaches will be crucial in ensuring that LLMs can meet the growing demands for accuracy and contextual relevance in information retrieval.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
The post AWS Enhancing Information Retrieval in Large Language Models: A Data-Centric Approach Using Metadata, Synthetic QAs, and Meta Knowledge Summaries for Improved Accuracy and Relevancy appeared first on MarkTechPost.
