


The Mixture of Experts (MoE) models enhance performance and computational efficiency by selectively activating subsets of model parameters. While traditional MoE models utilize homogeneous experts with identical capacities, this approach limits specialization and parameter utilization, especially when handling varied input complexities. Recent studies highlight that homogeneous experts tend to converge to similar representations, reducing their effectiveness. To address this, introducing heterogeneous experts could offer better specialization. However, challenges arise in determining the optimal heterogeneity and designing effective load distributions for these diverse experts to balance efficiency and performance.
Researchers from Tencent Hunyuan, the Tokyo Institute of Technology, and the University of Macau have introduced a Heterogeneous Mixture of Experts (HMoE) model, where experts vary in size, enabling better handling of diverse token complexities. To address the activation imbalance, they propose a new training objective that prioritizes the activation of smaller experts, improving computational efficiency and parameter utilization. Their experiments show that HMoE achieves lower loss with fewer activated parameters and outperforms traditional homogeneous MoE models on various benchmarks. Additionally, they explore strategies for optimal expert heterogeneity.
The MoE model divides learning tasks among specialized experts, each focusing on different aspects of the data. Later advancements introduced techniques to selectively activate a subset of these experts, improving efficiency and performance. Recent developments have integrated MoE models into modern architectures, optimizing experts’ choices and balancing their workloads. The study expands on these concepts by introducing an HMoE model, which uses experts of varying sizes to better handle diverse token complexities. This approach leads to more effective resource use and higher overall performance.
Classical MoE models replace the Feed-Forward Network (FFN) layer in transformers with an MoE layer consisting of multiple experts and a routing mechanism that activates a subset of these experts for each token. However, conventional homogeneous MoE models need more expert specialization, efficient parameter allocation, and load imbalance. The HMoE model is proposed to address these, where experts vary in size. This allows better task-specific specialization and efficient use of resources. The study also introduces new loss functions to optimize the activation of smaller experts and maintain overall model balance.
The study evaluates the HMoE model against Dense and Homogeneous MoE models, demonstrating its superior performance, particularly when using the Top-P routing strategy. HMoE consistently outperforms other models across various benchmarks, with benefits becoming more pronounced as training progresses and computational resources increase. The research highlights the effectiveness of the P-Penalty loss in optimizing smaller experts and the advantages of a hybrid expert size distribution. Detailed analyses reveal that HMoE effectively allocates tokens based on complexity, with smaller experts handling general tasks and larger experts specializing in more complex ones.
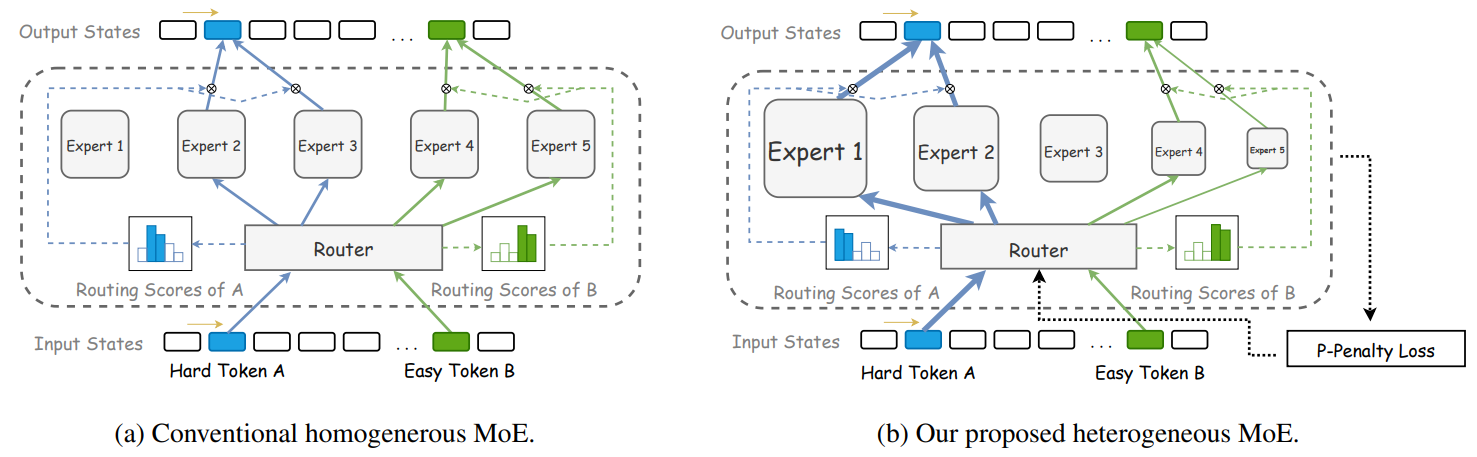
The HMoE model was designed with experts of different sizes to better address varying token complexities. A new training objective was developed to encourage smaller experts’ activation, improving computational efficiency and performance. Experiments confirmed that HMoE outperforms traditional homogeneous MoE models, achieving lower loss with fewer activated parameters. The research suggests that HMoE’s approach opens up new possibilities for large language model development, with potential future applications in diverse natural language processing tasks. The code for this model will be made available upon acceptance.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
The post Heterogeneous Mixture of Experts (HMoE): Enhancing Model Efficiency and Performance with Diverse Expert Capacities appeared first on MarkTechPost.
