
Published on August 24, 2024 4:35 PM GMT
[This is a continuation for the work in my previous post]
Recent work has demonstrated that transformer models can perform complex reasoning tasks using Chain-of-Thought (COT) prompting, even when the COT is replaced with hidden characters. This post summarizes our investigation into methods for decoding these hidden computations, focusing on the 3SUM task.
Background
1. Chain-of-Thought (COT) Prompting: A technique that improves the performance of large language models on complex reasoning tasks by eliciting intermediate steps [1].
2. Hidden COT: Replacing intermediate reasoning steps with hidden characters (e.g., "...") while maintaining model performance [2].
3. 3SUM Task: A problem requiring the identification of three numbers in a set that sum to zero, (here as a proxy for more complex reasoning tasks).
Methodology
We analyzed a 34M parameter LLaMA model with 4 layers, 384 hidden dimension, and 6 attention heads, this setup is same as mentioned in [2], trained on hidden COT sequences for the 3SUM task. Our analysis focused on three main areas:
1. Layer-wise Representation Analysis
2. Token Ranking
3. Modified Greedy Decoding Algorithm
Results:
Layer-wise Analysis:
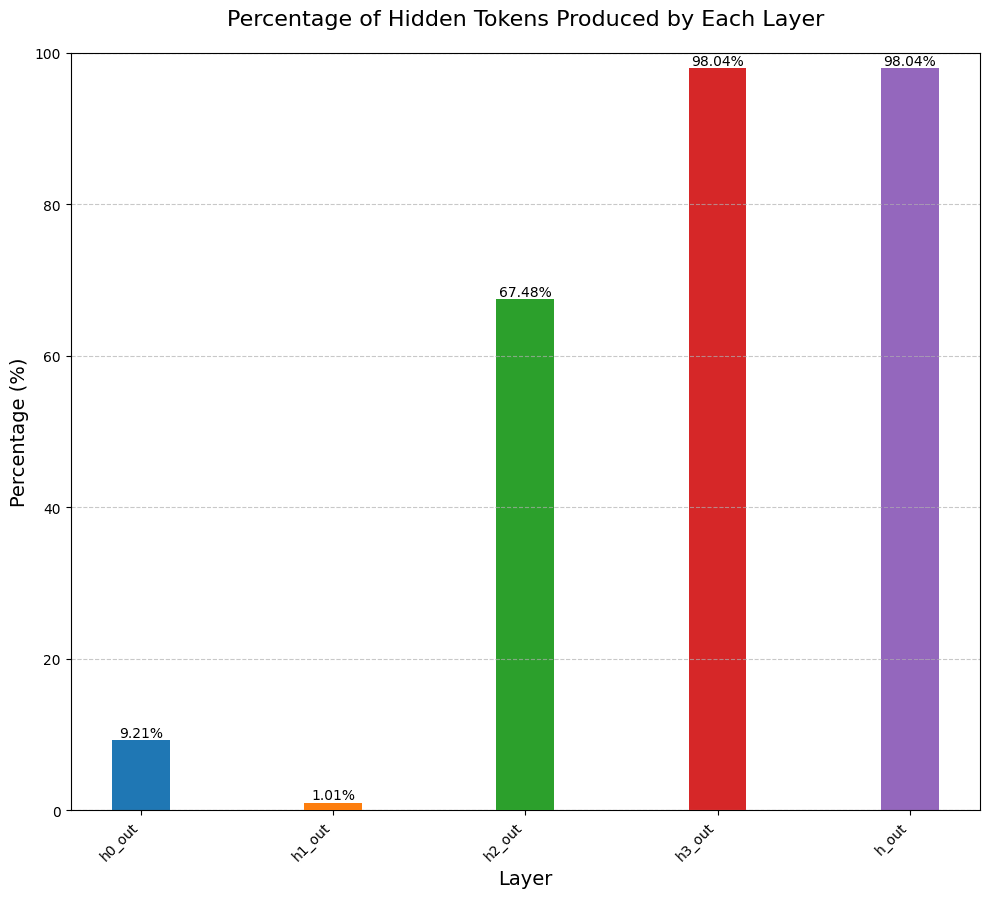
Our analysis revealed a gradual evolution of representations across the model's layers:
- Initial layers: Primarily raw numerical sequences
- Third layer onwards: Emergence of hidden tokens
- Final layers: Extensive reliance on hidden tokens
This suggests the model develops the ability to use hidden tokens as proxies in its deeper layers.
Token Rank Analysis:
- Top-ranked token: Consistently the hidden character (".")
- Lower-ranked tokens: Revealed the original, non-hidden COT sequences
This supports the hypothesis that the model replaces computation with hidden tokens while keeping the original computation intact underneath.
Modified Greedy Decoding Algorithm:
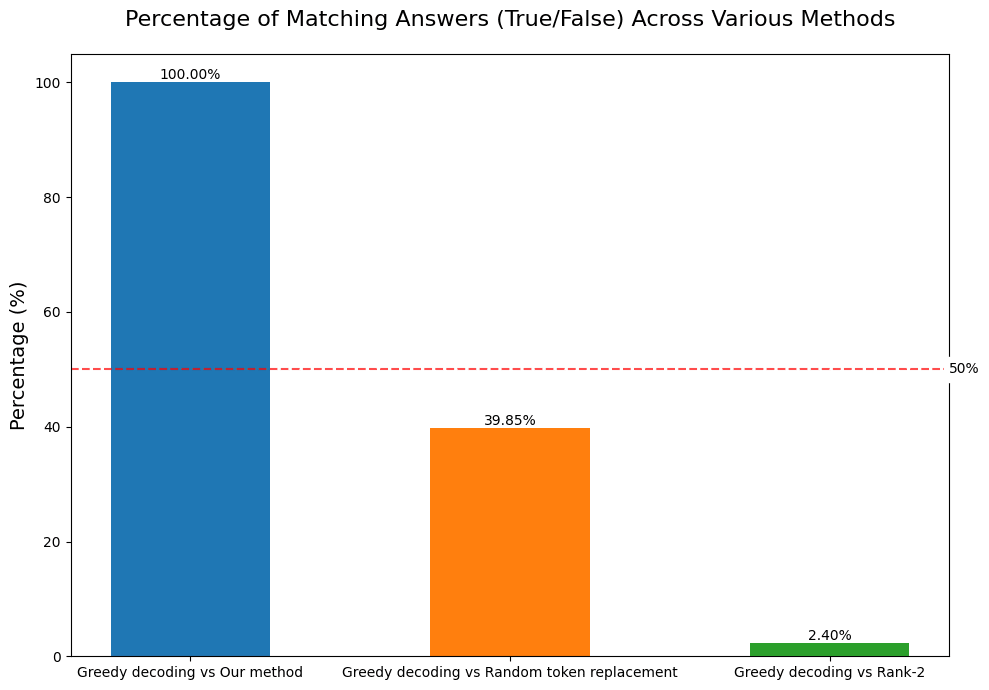
We implemented a modified greedy autoregressive decoding method:
1. Perform standard greedy decoding
2. Select the second-highest probability token when encountering a hidden token
3. Continue this process for the entire sequence
This method resulted in a 100% match in 3SUM task results with and without hidden tokens. I.e, replacing the hidden tokens with the rank-2 tokens do not affect the performance.
Implications and Future Work:
1. New tools for understanding internal reasoning processes
2. Increased confidence in COT-based approaches for improving model interpretability
3. Potential for developing better decoding methods or identifying circuits that hide tokens
4. Investigating generalizability to tasks beyond 3SUM, including natural language tasks
5. Improving token hiding methods (currently limited to one hidden token)
Conclusion:
Our approach to understanding hidden computations in transformer models through token ranking analysis, layer-wise representations, and a modified decoding algorithm provides new insights into how models encode and process information in hidden COT sequences. This work opens avenues for improving interpretability, efficiency, and safety in language models.
The code used for the experiments and analysis is available on GitHub: https://github.com/rokosbasilisk/filler_tokens/tree/v2
Appendix: Layerwise View of Sequences Generated via Various Decoding Methods
To provide a more detailed look at our results, we've included visualizations of the sequences generated by different decoding methods across the model's layers.
1. Greedy Decoding
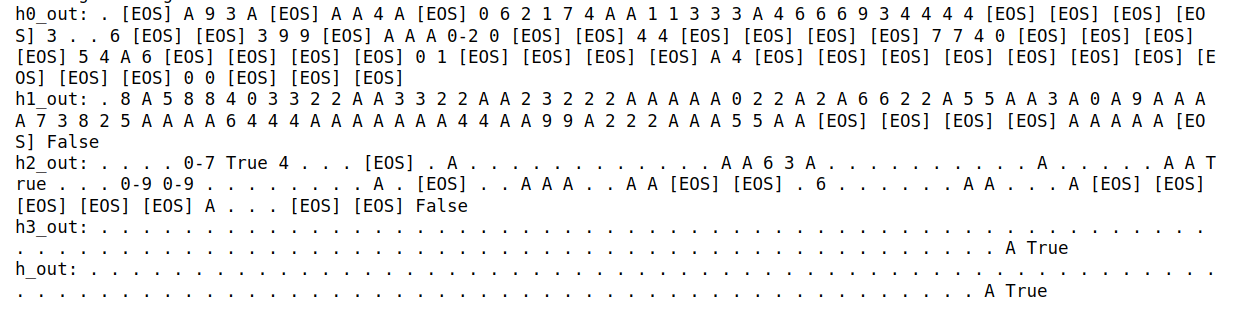
This plot shows the sequences generated by standard greedy decoding across different layers of the model.
2. Greedy Decoding with Rank-2 Tokens

Here, we visualize the sequences generated when we replace the top-ranked token (usually the hidden character) with the second-highest probability token.
3. Our Method: Greedy Decoding with Hidden Tokens Replaced by Rank-2 Tokens

This plot demonstrates our proposed method, where we perform greedy decoding but replace hidden tokens with the second-highest probability token.
4. Greedy Decoding with Hidden Tokens Replaced by Randomly Selected Tokens

For comparison, this plot shows what happens when we replace hidden tokens with randomly selected tokens instead of using the rank-2 tokens.
These visualizations provide insight into how different decoding methods affect the generated sequences across the model's layers, helping us understand the nature of hidden computation in transformer models.
References:
1. Pfau, J., Merrill, W., & Bowman, S. R. (2023). Let's Think Dot by Dot: Hidden Computation in Transformer Language Models. arXiv:2404.15758.
2. Wei, J., Wang, X., Schuurmans, D., et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. arXiv:2201.11903.
3. nostalgebraist (2020). interpreting GPT: the logit lens LessWrong post.
4. Touvron, H., Lavril, T., Izacard, G., et al. (2023). LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971.
Discuss
