


Artificial intelligence (AI) development, particularly in large language models (LLMs), focuses on aligning these models with human preferences to enhance their effectiveness and safety. This alignment is critical in refining AI interactions with users, ensuring that the responses generated are accurate and aligned with human expectations and values. Achieving this requires a combination of preference data, which informs the model of desirable outcomes, and alignment objectives that guide the training process. These elements are crucial for improving the model’s performance and ability to meet user expectations.
A significant challenge in AI model alignment lies in the issue of underspecification, where the relationship between preference data and training objectives is not clearly defined. This lack of clarity can lead to suboptimal performance, as the model may need help to learn effectively from the provided data. Underspecification occurs when preference pairs used to train the model contain irrelevant differences to the desired outcome. These spurious differences complicate the learning process, making it difficult for the model to focus on the aspects that truly matter. Current alignment methods often need to account more adequately for the relationship between the model’s performance and the preference data, potentially leading to a degradation in the model’s capabilities.
Existing methods for aligning LLMs, such as those relying on contrastive learning objectives and preference pair datasets, have made significant strides but must be revised. These methods typically involve generating two outputs from the model and using a judge, another AI model, or a human to select the preferred output. However, this approach can lead to inconsistent preference signals, as the criteria for choosing the preferred response might only sometimes be clear or consistent. This inconsistency in the learning signal can hinder the model’s ability to improve effectively during training, as the model may only sometimes receive clear guidance on adjusting its outputs to align better with human preferences.
Researchers from Ghent University – imec, Stanford University, and Contextual AI have introduced two innovative methods to address these challenges: Contrastive Learning from AI Revisions (CLAIR) and Anchored Preference Optimization (APO). CLAIR is a novel data-creation method designed to generate minimally contrasting preference pairs by slightly revising a model’s output to create a preferred response. This method ensures that the contrast between the winning and losing outputs is minimal but meaningful, providing a more precise learning signal for the model. On the other hand, APO is a family of alignment objectives that offer greater control over the training process. By explicitly accounting for the relationship between the model and the preference data, APO ensures that the alignment process is more stable and effective.
The CLAIR method operates by first generating a losing output from the target model, then using a stronger model, such as GPT-4-turbo, to revise this output into a winning one. This revision process is designed to make only minimal changes, ensuring that the contrast between the two outputs is focused on the most relevant aspects. This approach differs significantly from traditional methods, which might rely on a judge to select the preferred output from two independently generated responses. By creating preference pairs with minimal yet meaningful contrasts, CLAIR provides a clearer and more effective learning signal for the model during training.
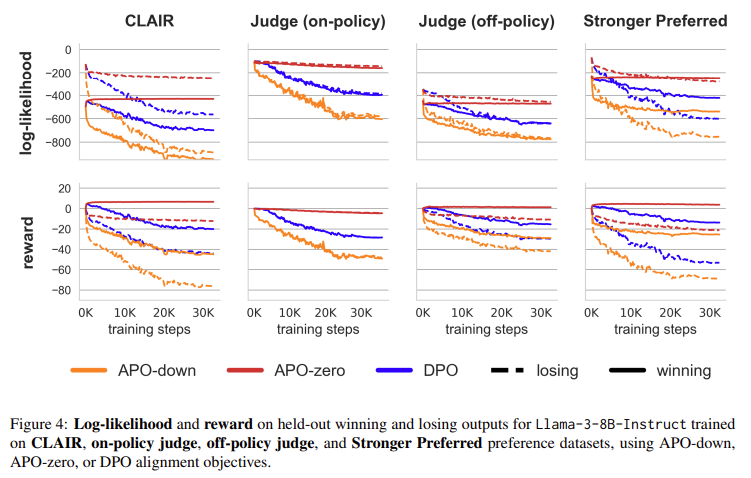
Anchored Preference Optimization (APO) complements CLAIR by offering fine-grained control over the alignment process. APO adjusts the likelihood of winning or losing outputs based on the model’s performance relative to the preference data. For example, the APO-zero variant increases the probability of winning outputs while decreasing the likelihood of losing ones, which is particularly useful when the model’s outputs are generally less desirable than the winning outputs. Conversely, APO-down decreases the likelihood of winning and losing outputs, which can be beneficial when the model’s outputs are already better than the preferred responses. This level of control allows researchers to tailor the alignment process more closely to the specific needs of the model and the data.
The effectiveness of CLAIR and APO was demonstrated by aligning the Llama-3-8B-Instruct model using a variety of datasets and alignment objectives. The results were significant: CLAIR, combined with the APO-zero objective, led to a 7.65% improvement in performance on the MixEval-Hard benchmark, which measures model accuracy across a range of complex queries. This improvement represents a substantial step towards closing the performance gap between Llama-3-8B-Instruct and GPT-4-turbo, reducing the difference by 45%. These results highlight the importance of minimally contrasting preference pairs and tailored alignment objectives in improving AI model performance.

In conclusion, CLAIR and APO offer a more effective approach to aligning LLMs with human preferences, addressing the challenges of underspecification and providing more precise control over the training process. Their success in improving the performance of the Llama-3-8B-Instruct model underscores their potential to enhance the alignment process for AI models more broadly.
Check out the Paper, Model, and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
The post Contrastive Learning from AI Revisions (CLAIR): A Novel Approach to Address Underspecification in AI Model Alignment with Anchored Preference Optimization (APO) appeared first on MarkTechPost.
