


The paper “A Survey of Pipeline Tools for Data Engineering” thoroughly examines various pipeline tools and frameworks used in data engineering. Let’s look into these tools’ different categories, functionalities, and applications in data engineering tasks.
Introduction to Data Engineering
- Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Data scientists often spend up to 80% of their time on data engineering in data science projects.Objective of Data Engineering: The main goal is to transform raw data into structured data suitable for downstream tasks such as machine learning. This involves a series of semi-automated or automated operations implemented through data engineering pipeline frameworks.

Categories of Pipeline Tools
Pipeline tools for data engineering are broadly categorized based on their design and functionality:
- Extract Transform Load (ETL) / Extract Load Transform (ELT) Pipelines:
- ETL Pipelines: Designed for data integration, these pipelines extract data from sources, transform it into the required format, and load it into the destination.ELT Pipelines: Typically used for big data, these pipelines extract data, load it into data warehouses or lakes, and then transform it.
- These pipelines handle the organization of data from multiple sources, ensuring that it is properly integrated and transformed for use.
- These pipelines manage the workflow and coordination of data processes, ensuring data moves seamlessly through the pipeline.
- These pipelines, specifically designed for machine learning tasks, handle machine learning models’ preparation, training, and deployment.
Detailed Examination of Tools
Apache Spark:
An open-source platform supporting multiple languages (Python, Java, SQL, Scala, and R). It is suitable for distributed and scalable large-scale data processing, providing quick big-data query and analysis capabilities.
- Strengths: It offers parallel processing, flexibility, and built-in capabilities for various data tasks, including graph processing.Weaknesses: Long-processing graphs can lead to reliability issues and negatively affect performance.
AWS Glue:
A serverless ETL service that simplifies the monitoring and management of data pipelines. It supports multiple languages & integrates well with other AWS machine learning and analytics tools.
- Strengths: Provides visual and codeless functions, making it user-friendly for data engineering tasks.Weaknesses: Customization and integration with non-AWS tools are limited as a closed-source tool.
Apache Kafka:
An open-source platform supporting real-time data processing with high speed and low latency. It can ingest, read, write, and process data in local and cloud environments.
- Strengths: Fault-tolerant, scalable, and reliable for real-time data processing.Weaknesses: Steep learning curve and complex setup and operational requirements.
Microsoft SQL Server Integration Services (SSIS):
A closed-source platform for building ETL, data integration, and transformation pipeline workflows. It supports multiple data sources & destinations and can run on-premises or integrate with the cloud.
- Strengths: User-friendly with a customizable graphical interface, easy to use, with built-in troubleshooting logs.Weaknesses: Initial setup and configuration can be cumbersome.
Apache Airflow:
An open-source tool for workflow orchestration and management, supporting parallel processing and integration with multiple tools.
- Strengths: Extensible with hooks and operators for connecting with external systems, robust for managing complex workflows.Weaknesses: Steep learning curve, especially during initial setup.

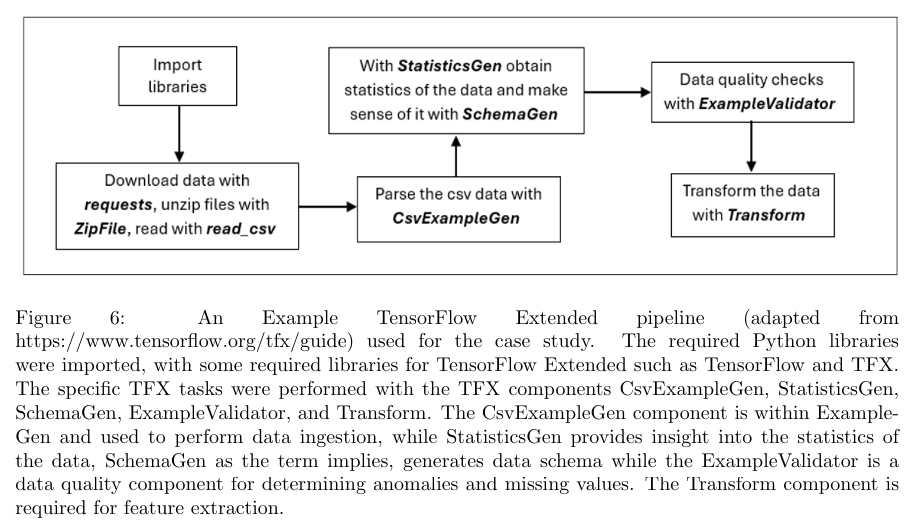
TensorFlow Extended (TFX):
An open-source machine learning pipeline platform supporting end-to-end ML workflows. It provides components for data ingestion, validation, and feature extraction.
- Strengths: Scalable, integrates well with other tools like Apache Airflow and Kubeflow, and provides comprehensive data validation capabilities.Weaknesses: Setting up TFX can be challenging for users unfamiliar with the TensorFlow ecosystem.
Conclusion
The selection of an appropriate data engineering pipeline tool depends on many factors, including the specific requirements of the data engineering tasks, the nature of the data, and the user’s familiarity with the tool. Each tool has strengths and weaknesses, making them suitable for different scenarios. Combining multiple pipeline tools might provide a more comprehensive solution to complex data engineering challenges.
Source: https://arxiv.org/pdf/2406.08335
The post A Comprehensive Overview of Data Engineering Pipeline Tools appeared first on MarkTechPost.
