


Tabular data, which dominates many genres, such as healthcare, financial, and social science applications, contains rows and columns with structured features, making it much easier for data management or analysis. However, the diversity of tabular data, including numerical, unconditional, and textual, brings huge challenges to attaining robust and accurate predictive performance. Another area for improvement in effectively modeling and analyzing this type of data is the complexity of the relationships inside the data, particularly dependencies between rows and columns.
The main challenge in analyzing tabular data is that it is very difficult to handle its heterogeneous structure. Traditional machine learning models stay far away when considering the complex relationships inside tabular datasets, especially for large and complex datasets. These models require additional guidance to generalize well in the presence of a diversity of data types and interdependencies of tabular data. This challenge becomes even more complex given the need for high predictive accuracy and robustness, especially in critical applications such as health care, where the decisions among data analysis can be quite consequential.
Different methods have been applied to overcome these challenges of modeling tabular data. Early techniques relied largely on conventional machine learning, most of which needed a lot of feature engineering to model the subtleties of the data. The known weakness of these naturally lay in their inability to scale in size and complexity of the input dataset. More recently, techniques from NLP have been adapted for tabular data; more specifically, transformer-based architectures are increasingly implemented. These methods started by training the transformers from scratch over tabular data, but this had the disadvantage of needing huge amounts of training data with significant scalability issues. Against this backdrop, researchers began using PLMs like BERT, which required less data and provided better predictive performance.
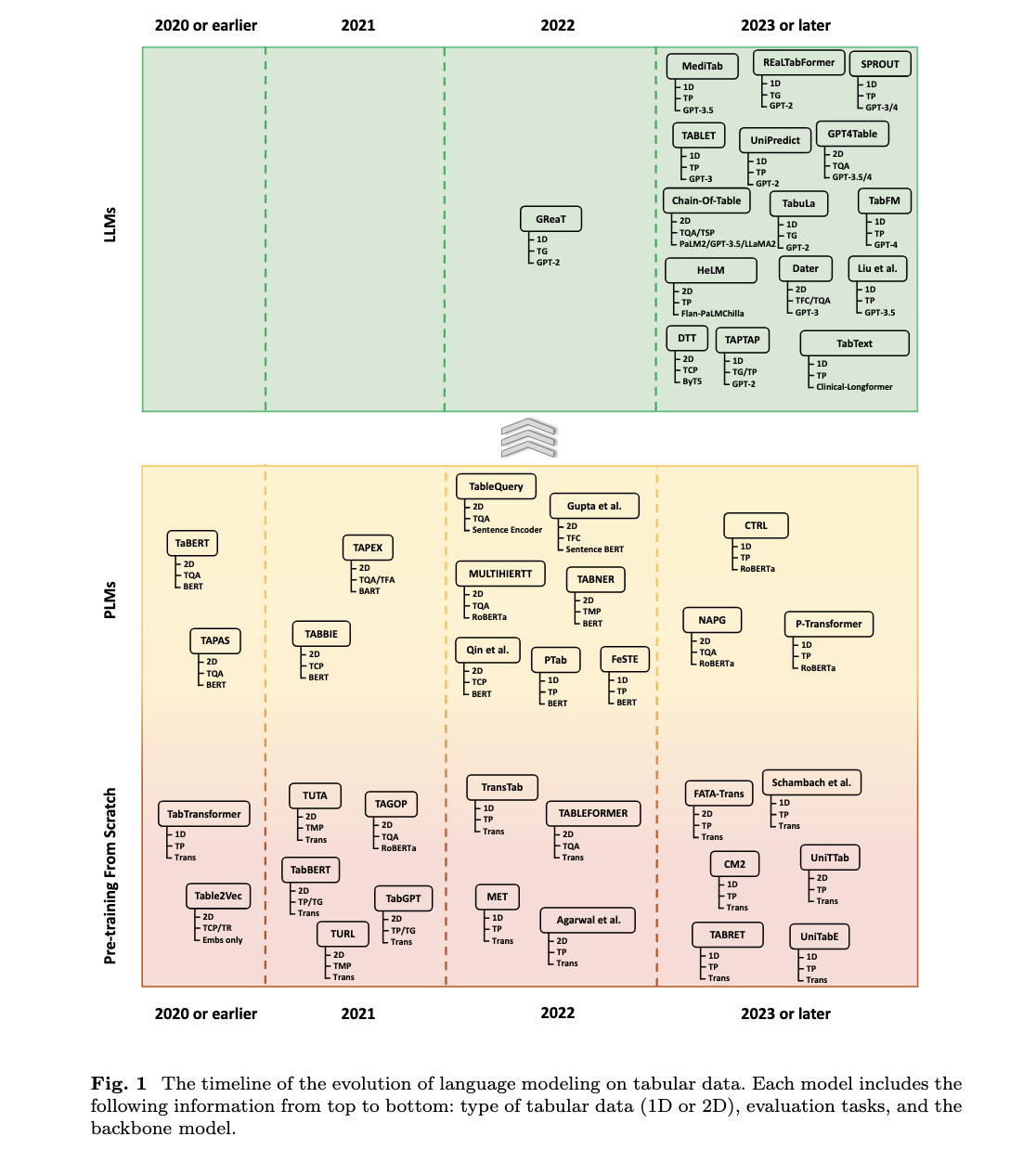
Researchers from the National University of Singapore provided a comprehensive survey of the various language modeling techniques developed for tabular data. The review systematizes classification for literature and further identifies a trend shift from traditional machine learning models to advanced methods using state-of-the-art LLMs like GPT and LLaMA. This research has emphasized the evolution of these models, showing how LLMs have been radical in the field, taking it further into more sophisticated applications in modeling tabular data. This work is important to fill a gap in the relevant literature by providing a detailed taxonomy of the tabular data structures, key datasets, and various modeling techniques.
The methodology proposed by the research team categorizes tabular data into two major categories: 1D and 2D. On the other hand, 1D tabular data usually contains only one table, with the main work coming at the row level, which, of course, is simpler but very important for tasks like classification and regression. In contrast, 2D tabular data consists of multiple related tables, requiring more complex modeling techniques for tasks such as table retrieval and table question-answering. The researchers delve into different strategies for turning tabular data into forms that their language model can consume. These strategies include flattening sequences, row processing, and integrating this information in prompts. Through these methods, the language models lever a more profound understanding and processing abilities of tabular data towards assured predictive outcomes.
The research shows how strong the ability of great big language models is in most tasks of tabular data. These models have demonstrated marked improvement in understanding and processing complex data structures on functions such as Table Question Answering and Table Semantic Parsing. The authors illustrate how LLMs enable a standard rise in all tasks at higher levels of accuracy and efficiency by exploiting pre-trained knowledge and advanced attention mechanisms that set new tabular data modeling standards across many applications.
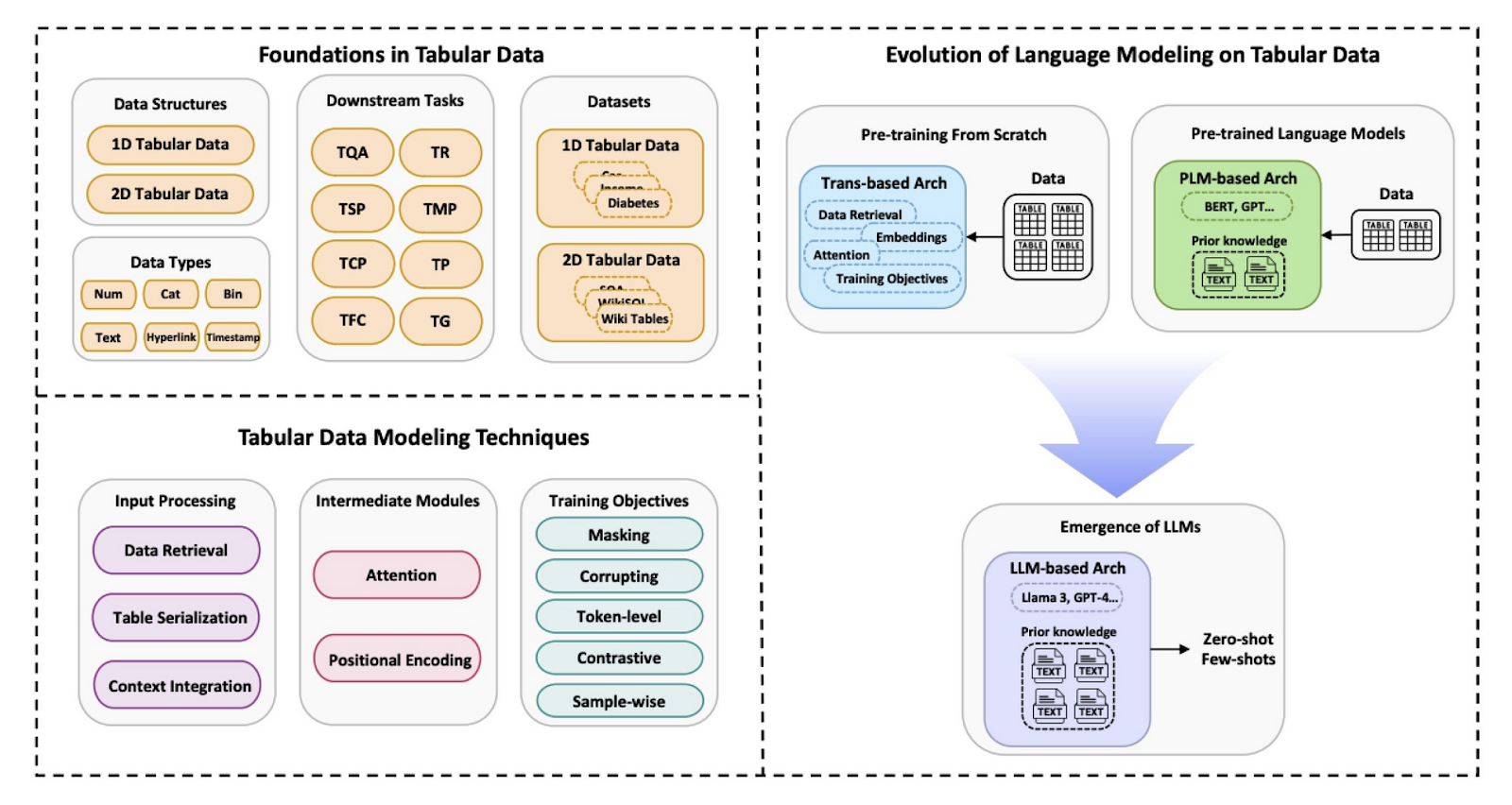
In conclusion, the research has underscored the potential that NLP techniques have for effectively changing the very nature of tabular data analysis in the presence of large language models. By systematizing the review and categorization of existing methods, researchers have proposed a very clear roadmap for future developments in this area. The proposed methodologies negate the intrinsic challenges of tabular data and open up new advanced applications with guarantees of relevance and effectiveness, including when the complexity of data rises.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
The post This AI Paper by National University of Singapore Introduces A Comprehensive Survey of Language Models for Tabular Data Analysis appeared first on MarkTechPost.
