


Emergent abilities in large language models (LLMs) refer to capabilities present in larger models but absent in smaller ones, a foundational concept that has guided prior research. While studies have identified 67 such emergent abilities through benchmark evaluations, some researchers question whether these are genuine or merely artifacts of the evaluation methods used. In response, other works argue that certain abilities are indeed emergent, as LLMs outperform smaller models on specific tasks. Investigations into the roles of memory and in-context learning (ICL) aim to elucidate the mechanisms behind LLM performance. However, previous evaluations have not clearly differentiated between ICL and instruction-tuning settings, an important distinction for understanding the true nature of emergent abilities. This paper seeks to address these gaps in the literature.
Researchers from the Technical University of Darmstadt and The University of Bath present a new theory explaining emergent abilities in large language models (LLMs). LLMs, with their many parameters and large training datasets, often exhibit unexpected skills known as “emergent abilities.” However, these abilities are often confused with skills gained through different prompting methods, such as in-context learning, where models learn from examples. The research, supported by over 1000 experiments, shows that these abilities are not truly emergent but rather stem from a mix of in-context learning, memory, and language knowledge rather than being innate.
Pre-trained language models (PLMs) excel at learning language rules but struggle with real-world language use, which requires more complex understanding. LLMs, being larger versions of PLMs, demonstrate better performance on tasks without specific training, suggesting they have emergent abilities. However, the study argues that successful task performance through techniques like in-context learning and instruction-tuning does not mean the model has an inherent ability. The research aims to clarify which abilities are genuinely emergent and how much in-context learning influences LLM performance, ensuring their safe and effective use in various applications.
The primary objective of this study was to investigate whether the emergent abilities observed in large language models (LLMs) are genuinely emergent or can be attributed to in-context learning (ICL) and other model competencies. The researchers selected a diverse set of tasks, primarily from the BIG-bench dataset, to comprehensively evaluate the capabilities of models like GPT-3 and Flan-T5-large. The evaluation process involved assessing the models’ performance across 21 different tasks, focusing on identifying cases where they significantly outperformed random baselines.
A manual evaluation of 50 examples per task was conducted to ensure the accuracy and quality of the outputs. The researchers employed statistical methods to analyse the performance data, comparing the results of instruction-tuned and non-instruction-tuned models to understand the influence of ICL and other factors on the observed abilities. Additionally, the researchers used an “adversarial prompt setting” to test the models’ capabilities in a more controlled manner. The findings from this systematic approach aim to contribute to a deeper understanding of LLMs’ abilities and limitations, addressing safety concerns related to their use.
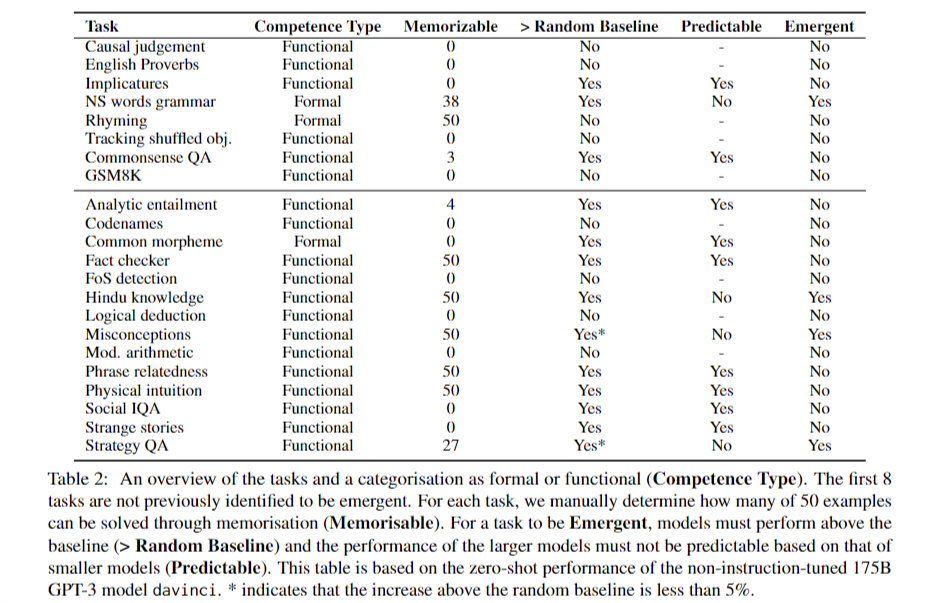
The study evaluated the performance of various large language models (LLMs) across 22 tasks, revealing that while some models performed above the random baseline, the improvements were often modest and not indicative of true emergent abilities. Only five out of the 21 tasks showed significant performance differences between models, suggesting that instruction-tuning plays a crucial role in enhancing model capabilities. The comparative analysis highlighted the overlapping performance of models like Flan-T5-large and GPT-J, indicating that instruction-tuning may enable models to leverage in-context learning more effectively rather than revealing inherent emergent reasoning abilities.
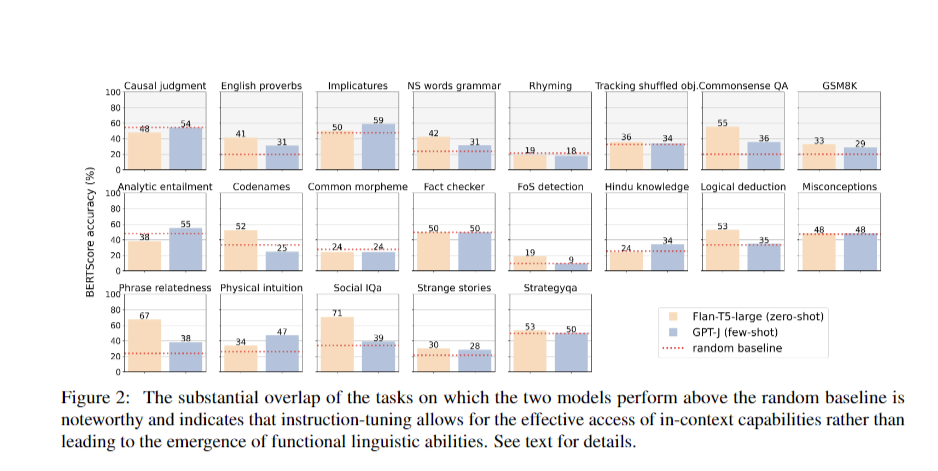
The manual evaluation of responses further revealed that many tasks remained predictable based on smaller model performances, suggesting that the observed improvements do not necessarily reflect emergent abilities but rather the models’ reliance on learned patterns and instructions. Across the various model families tested, a consistent pattern emerged: either the task performance was predictable based on smaller models, or it fell below the baseline. This finding reinforces the notion that the capabilities of LLMs should not be overestimated, as their performance often aligns with learned competencies rather than true emergent reasoning.
In conclusion, this study finds that the so-called emergent abilities of large language models (LLMs) are not truly emergent but rather stem primarily from in-context learning (ICL), model memory, and linguistic knowledge. Through extensive experimentation, the authors demonstrate that LLM performance is often predictable based on smaller models or falls below baseline, challenging the notion of robust emergent abilities. While instruction-tuning enhances the models’ ability to follow instructions, the authors emphasize this does not equate to reasoning capabilities, as evidenced by ‘hallucination.’ To address safety concerns, the study underscores the importance of understanding LLMs’ limitations and advocates developing detection mechanisms and ethical guidelines to mitigate risks. This research lays the groundwork for refining the understanding and safe, ethical application of LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
The post Unraveling the Nature of Emergent Abilities in Large Language Models: The Role of In-Context Learning and Model Memory appeared first on MarkTechPost.
