


Cloud AI infrastructure is vital to modern technology, providing the backbone for various AI workloads and services. Ensuring the reliability of these infrastructures is crucial, as any failure can lead to widespread disruption, particularly in large-scale distributed systems where AI workloads are synchronized across numerous nodes. This synchronization means that a failure in one node can have cascading effects, magnifying the impact and causing significant downtime or performance degradation. The complexity and scale of these systems make it essential to have robust mechanisms in place to maintain their smooth operation and minimize incidents that could affect the quality of service provided to users.
One of the primary challenges in maintaining cloud AI infrastructure is addressing hidden degradations due to hardware redundancies. These subtle failures, often termed “gray failures,” do not cause immediate, catastrophic problems but gradually degrade performance over time. These issues are particularly problematic because they are not easily detectable with conventional monitoring tools, typically designed to identify more apparent binary failure states. The insidious nature of gray failures complicates the task of root cause analysis, making it difficult for cloud providers to identify and rectify the underlying problems before they escalate into more significant issues that could impact the entire system.
Cloud providers have traditionally relied on hardware redundancies to mitigate these hidden issues and ensure system reliability. Redundant components, such as extra GPU compute units or over-provisioned networking links, are intended to act as fail-safes. However, these redundancies can inadvertently introduce their own set of problems. Over time, continuous and repetitive use of these redundant components can lead to gradual performance degradation. For example, in Azure A100 clusters, where InfiniBand top-of-rack (ToR) switches have multiple redundant uplinks, the loss of some of these links can lead to throughput regression, particularly under certain traffic patterns. This gradual degradation type often goes unnoticed until it significantly impacts AI workloads, which becomes much more challenging to address.
A team of researchers from Microsoft Research and Microsoft introduced SuperBench, a proactive validation system designed to enhance cloud AI infrastructure’s reliability by addressing the hidden degradation problem. SuperBench performs a comprehensive evaluation of hardware components under realistic AI workloads. The system includes two main components: a Validator, which learns benchmark criteria to identify defective components, and a Selector, which optimizes the timing and scope of the validation process to ensure it is both effective and efficient. SuperBench can run diverse benchmarks representing most real AI workloads, allowing it to detect subtle performance regressions that might otherwise go unnoticed.
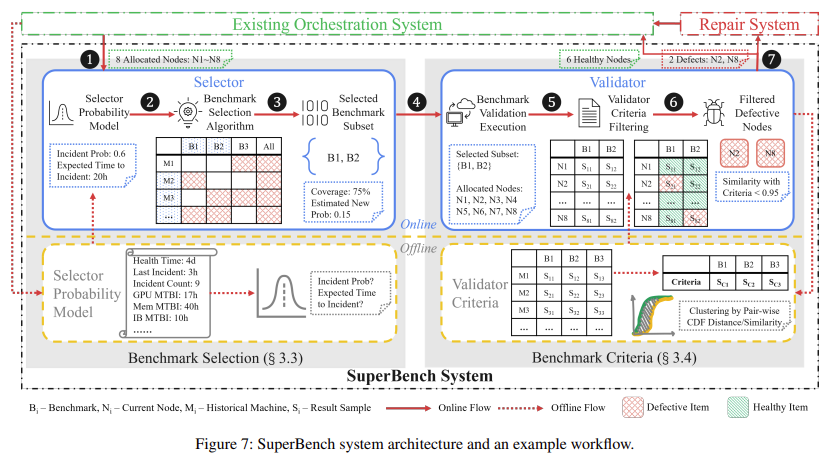
The technology behind SuperBench is sophisticated and tailored to address the unique challenges cloud AI infrastructures pose. The Validator component of SuperBench conducts a series of benchmarks on specified nodes, learning to distinguish between normal and defective performance by analyzing the cumulative distribution of benchmark results. This approach ensures that even slight deviations in performance, which could indicate a potential problem, are detected early. Meanwhile, the Selector component balances the trade-off between validation time and the possible impact of incidents. Using a probability model to predict the likelihood of incidents, the Selector determines the optimal time to run specific benchmarks. This ensures that validation is performed when it is most likely to prevent issues.
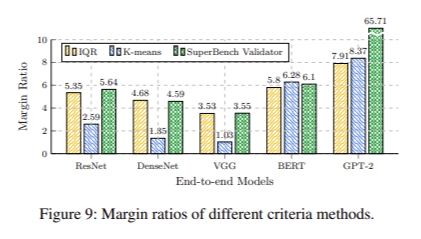
The effectiveness of SuperBench is demonstrated by its deployment in Azure’s production environment, where it has been used to validate hundreds of thousands of GPUs. Through rigorous testing, SuperBench has been shown to increase the mean time between incidents (MTBI) by up to 22.61 times. By reducing the time required for validation and focusing on the most critical components, SuperBench has decreased the cost of validation time by 92.07% while simultaneously increasing user GPU hours by 4.81 times. These impressive results highlight the system’s ability to detect and prevent performance issues before they impact end-to-end workloads.

In conclusion, SuperBench, by focusing on the early detection and resolution of hidden degradations, offers a robust solution to the complex challenge of ensuring the continuous and reliable operation of large-scale AI services. The system’s ability to identify subtle performance regressions and optimize the validation process makes it an invaluable tool for cloud service providers looking to enhance the reliability of their AI infrastructures. With SuperBench, Microsoft has set a new standard for cloud infrastructure maintenance, ensuring that AI workloads can be executed with minimal disruption and maximum efficiency, thus maintaining high-performance standards in a rapidly evolving technological landscape.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post Microsoft Released SuperBench: A Groundbreaking Proactive Validation System to Enhance Cloud AI Infrastructure Reliability and Mitigate Hidden Performance Degradations appeared first on MarkTechPost.
