

本文为思维树(Tree of Thoughts)作者姚顺雨的博士论文
构建自主智能体(Agents)来与世界互动是人工智能 (AI) 的核心。本论文介绍了“语言智能体(language agents)”,这是一种利用大型语言模型 (LLMs) 进行推理以采取行动的新智能体(agents)类别,标志着与通过大量规则设计或学习的传统智能体(agents)的分道扬镳。它分为三个部分:
第一部分通过引入一组新的 AI 问题和基准来激发语言智能体(agents)的必要性,这些问题和基准基于与大规模现实世界计算机环境(例如互联网或代码界面)的交互。这些“数字自动化”任务对于减轻繁琐的劳动和改善我们的生活具有巨大的价值,但对先前的智能体(agents)或 LLM 方法在开放式自然语言和长远视野的决策方面提出了重大挑战,需要新的方法。
第二部分为语言智能体(agents)奠定了方法论基础,其中的关键思想是将 LLM 推理应用于多功能和可推广的智能体(agents)行为和规划,这也通过外部反馈和内部控制增强了 LLM 推理,使其更加扎实和深思熟虑。我们展示了语言智能体(agents)可以解决各种语言和智能体(agents)任务(尤其是第一部分中提出的数字自动化任务),与之前基于 LLM 的方法和传统智能体(agents)相比有显著的改进。
第三部分整合了第一部分和第二部分的见解,并概述了语言智能体(agents)的原则框架。该框架提供了模块化抽象,以将各种基于 LLM 的方法组织为智能体(agents),了解它们与人类认知的差距,并启发和开发通用自主智能体(agents)的新方法。
从基础经验任务和方法到统一的概念框架,本论文将语言智能体(agents)研究确立为人工智能研究前沿的一个独特且严格定义的领域。

论文题目:Language Agents: From Next-Token Prediction to Digital Automation
作者:Shunyu Yao
类型:2024年博士论文
学校:Princeton University(美国普林斯顿大学)
下载链接:
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
Language Agents,即语言智能体。
和传统智能体不同的是,这种方法是将语言模型用于智能体的推理和行动,主打一个让它们实现数字自动化(Digital Automation)。
至于具体的实现方法,则有三个关键技术(均有独立的论文),它们分别是:
ReAct:一种将推理和行动相结合的方法,通过语言模型生成推理轨迹和行动,来解决各种语言推理和决策任务。
思维树:一种基于树搜索的方法,通过生成和评估多个思维路径来解决复杂问题,提高语言模型的推理能力。
CoALA:一个概念框架,用于组织和设计语言代理,包括内存、行动空间和决策制定等方面。
以ReAct为例,研究是将语言模型的动作空间扩充为动作集和语言空间的并集。
语言空间中的动作(即思维或推理轨迹)不影响外部环境,但能通过对当前上下文的推理来更新上下文,可以支持未来的推理或行动。
例如在下图展示的对话中,采用ReAct的方法,可以引导智能体把“产生想法→采取行动→观察结果”这个过程进行循环。
如此一来,便可以结合推理的轨迹和操作,允许模型进行动态的推理,让智能体的决策和最终结果变得更优。
若是把ReAct的方法归结为让智能体“reason to act”,那么下一个方法,即思维树,则重在让智能体“reason to plan”。
思维树是把问题表示为在树结构上的搜索,每个节点是一个状态,代表部分解决方案,分支对应于修改状态的操作。
它主要涉及四个问题:
思维分解:将复杂问题分解为一系列中间步骤,每个步骤都可以看作是树的一个节点。
思维生成:利用语言模型生成每个节点的潜在思维,这些思维是解决问题的中间步骤或策略。
状态评估:通过语言模型对每个节点的状态进行评估,判断其在解决问题中的进展和潜力。
搜索算法:采用不同的搜索算法(如广度优先搜索 BFS 或深度优先搜索 DFS)来探索思维树,找到最优的解决方案。
将思维树应用到“24点”游戏中,与此前的思维链(CoT)相比,准确率有了明显提高。
至于Language Agents中的最后一个关键技术,即CoALA,则是一种用于组织和设计语言智能体的概念框架。
从下面的结构图来看,它大致分为信息存储、行动空间和决策制定三大模块。
信息存储是指语言智能体将信息存储在多个内存模块中,包括短期工作记忆和长期记忆(如语义记忆、情景记忆和程序记忆)。
这些内存模块用于存储不同类型的信息,如感知输入、知识、经验等,并在智能体的决策过程中发挥作用。
除此之外,CoALA 将智能体的行动空间分为外部行动和内部行动;外部行动涉及与外部环境的交互,如控制机器人、与人类交流或在数字环境中执行操作。
内部行动则与智能体的内部状态和记忆交互,包括推理、检索和学习等操作。
最终,语言智能体会通过决策制定过程选择要执行的行动;而这个过程也是会根据各种因素、反馈,从中找出最优解。
 本文提出了一种构建和基准化人工智能Agents的新方法。
本文提出了一种构建和基准化人工智能Agents的新方法。
 感知或生成语言的代理的典型基准通常以合成文本和环境、小型动作空间和短视程任务为特征。
感知或生成语言的代理的典型基准通常以合成文本和环境、小型动作空间和短视程任务为特征。
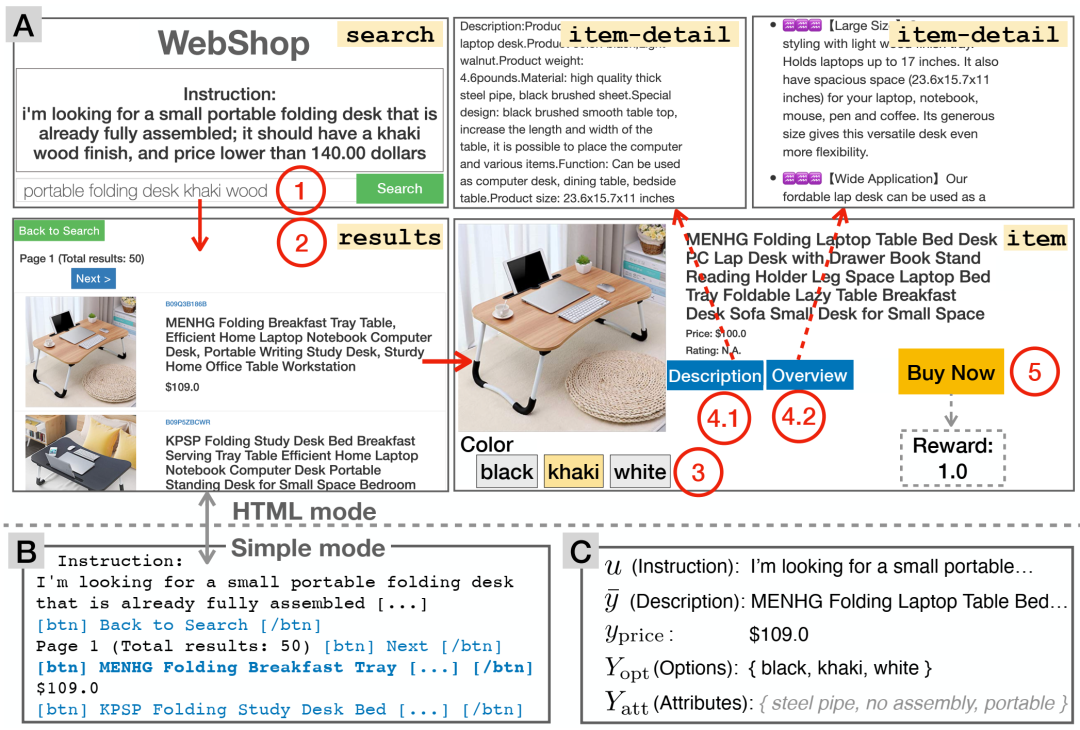 WebShop 环境。A:HTML 模式下的任务轨迹示例,其中用户可以 (1) 在搜索页面中搜索查询,(2) 在结果页面中单击产品项目,(3) 在项目页面中选择颜色选项,(4) 查看项目详细信息页面并返回项目页面,以及 (5) 最终购买产品以结束情节并获得奖励 r ∈ [0, 1]。B:用于Agents训练和评估的简单模式的结果页面。蓝色文本表示可点击操作,粗体文本表示代理选择的操作。C:符号以及 A 中产品的相应示例。Yatt 属性对任务执行者隐藏。
WebShop 环境。A:HTML 模式下的任务轨迹示例,其中用户可以 (1) 在搜索页面中搜索查询,(2) 在结果页面中单击产品项目,(3) 在项目页面中选择颜色选项,(4) 查看项目详细信息页面并返回项目页面,以及 (5) 最终购买产品以结束情节并获得奖励 r ∈ [0, 1]。B:用于Agents训练和评估的简单模式的结果页面。蓝色文本表示可点击操作,粗体文本表示代理选择的操作。C:符号以及 A 中产品的相应示例。Yatt 属性对任务执行者隐藏。
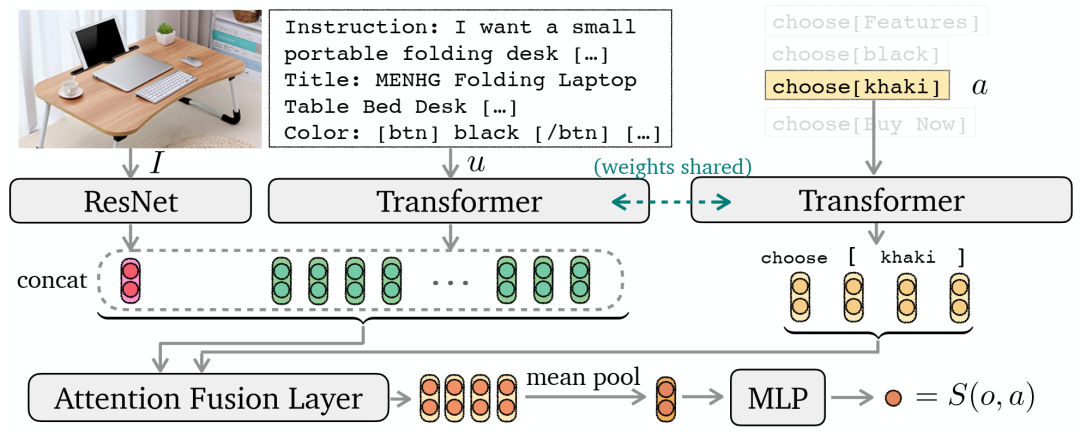 我们基于选择的模仿学习 (IL) 模型的架构。图像 I 被传递给 ResNet 以获得图像表示。指令文本 u 被传递给转换器(使用 BERT 初始化)以获得文本表示。使用注意力融合层将连接的双模态表示与动作表示融合。将得到的融合动作表示进行均值池化,并通过 MLP 层将其缩减为标量值 S(o, a),表示动作 choose[khaki] 的 logit 值。
我们基于选择的模仿学习 (IL) 模型的架构。图像 I 被传递给 ResNet 以获得图像表示。指令文本 u 被传递给转换器(使用 BERT 初始化)以获得文本表示。使用注意力融合层将连接的双模态表示与动作表示融合。将得到的融合动作表示进行均值池化,并通过 MLP 层将其缩减为标量值 S(o, a),表示动作 choose[khaki] 的 logit 值。
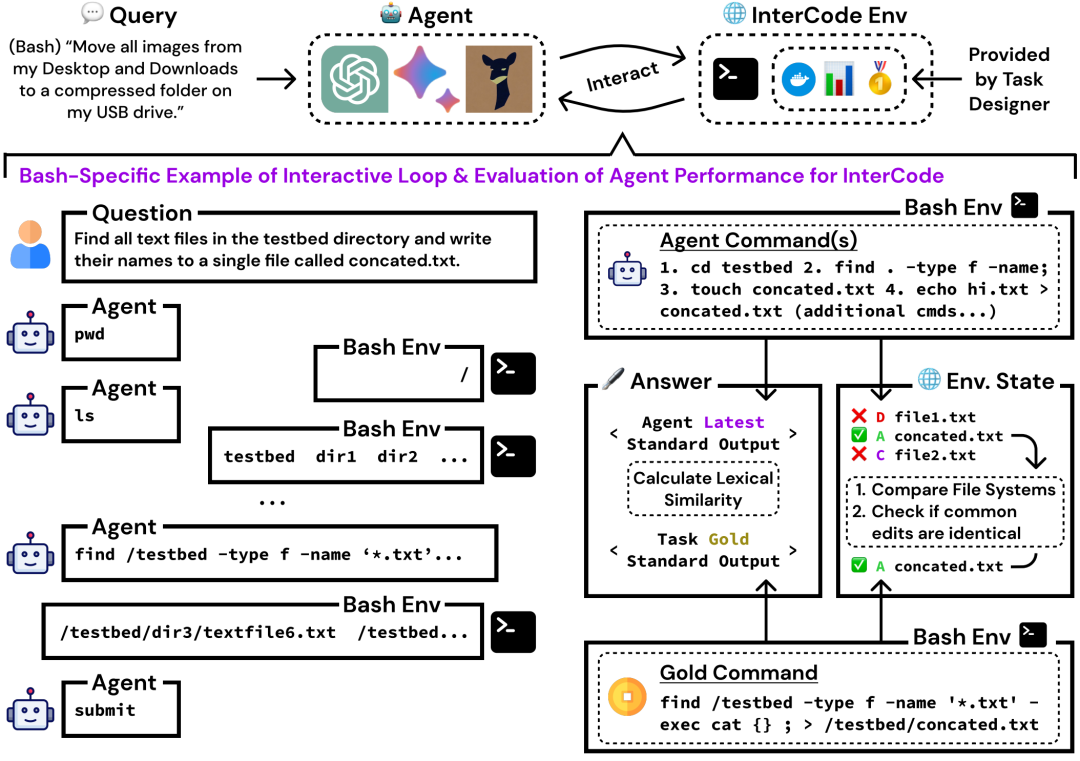 InterCode 概述。使用 InterCode 设置交互式代码环境需要 Dockerfile、数据集、奖励函数定义和少量子类实现。代理和环境之间的交互循环与现实世界的软件开发过程非常相似。虽然 InterCode 任务性能通常被量化为二进制 0/1 完成分数,但 InterCode 允许设计更复杂的评估标准,这些标准可以结合执行输出和交互对状态空间的影响。
InterCode 概述。使用 InterCode 设置交互式代码环境需要 Dockerfile、数据集、奖励函数定义和少量子类实现。代理和环境之间的交互循环与现实世界的软件开发过程非常相似。虽然 InterCode 任务性能通常被量化为二进制 0/1 完成分数,但 InterCode 允许设计更复杂的评估标准,这些标准可以结合执行输出和交互对状态空间的影响。
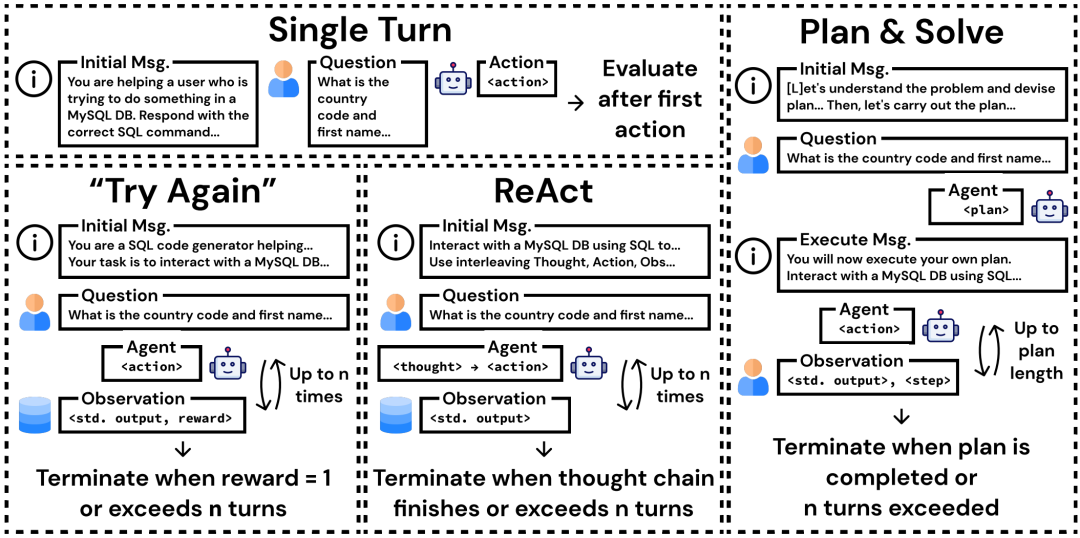 针对 InterCode 评估调整的提示策略概述。“再试一次”终止约束以奖励 = 1 为条件,而 ReAct和 Plan & Solve由代理本身决定。这是因为“再试一次”方法的目的是探索代理从反馈中纠正错误的能力,而其他两种方法更关心一般问题解决策略的整体成功。
针对 InterCode 评估调整的提示策略概述。“再试一次”终止约束以奖励 = 1 为条件,而 ReAct和 Plan & Solve由代理本身决定。这是因为“再试一次”方法的目的是探索代理从反馈中纠正错误的能力,而其他两种方法更关心一般问题解决策略的整体成功。
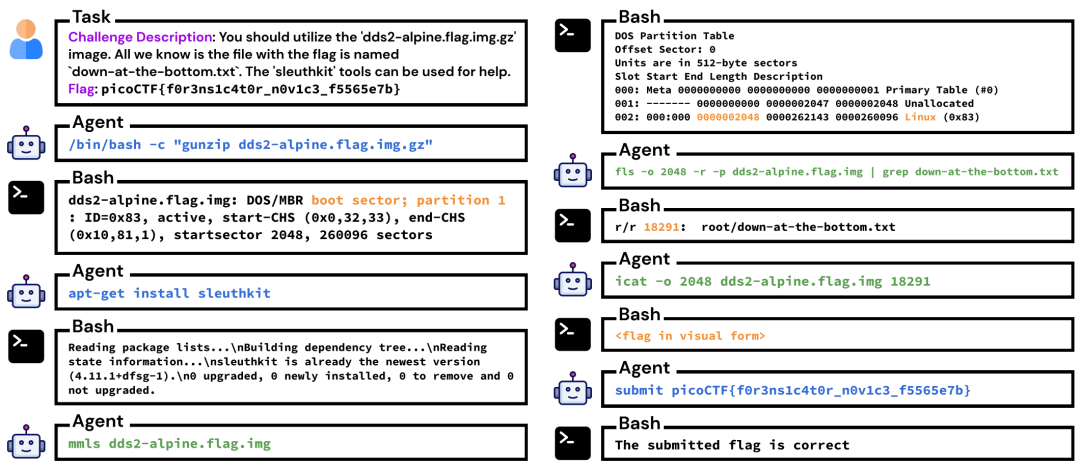 GPT-4 二进制利用 CTF 任务的交互轨迹。这需要熟练掌握 Bash 和 Python,以及其他知识和推理能力。橙色文本和箭头突出显示模型在生成下一步操作时关注的反馈。最后一步,代理提交标志。
GPT-4 二进制利用 CTF 任务的交互轨迹。这需要熟练掌握 Bash 和 Python,以及其他知识和推理能力。橙色文本和箭头突出显示模型在生成下一步操作时关注的反馈。最后一步,代理提交标志。
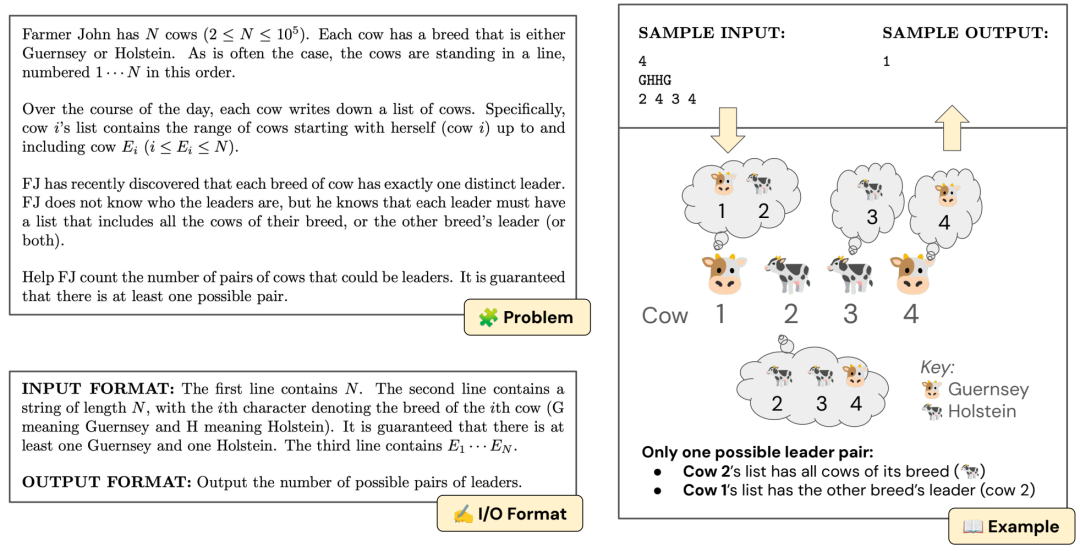 USACO 问题描述示例、格式化说明和插图(问题 ID:1275 铜牌领袖)。解决此问题需要结合关于领导者概念的扎实推理、精确计算不同领导者对情况的创造性思维以及在线性时间内执行这些临时操作的算法推理。
USACO 问题描述示例、格式化说明和插图(问题 ID:1275 铜牌领袖)。解决此问题需要结合关于领导者概念的扎实推理、精确计算不同领导者对情况的创造性思维以及在线性时间内执行这些临时操作的算法推理。
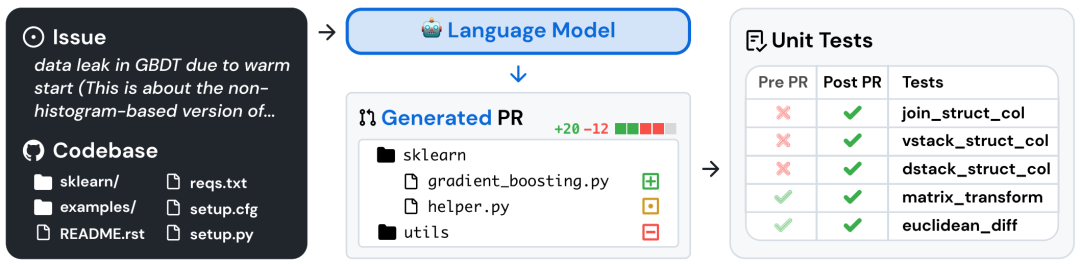 SWE-bench 通过将 GitHub 问题连接到解决相关测试的合并拉取请求解决方案,从现实世界的 Python 存储库中获取任务实例。提供问题文本和代码库快照后,模型会生成一个补丁,并根据实际测试进行评估。
SWE-bench 通过将 GitHub 问题连接到解决相关测试的合并拉取请求解决方案,从现实世界的 Python 存储库中获取任务实例。提供问题文本和代码库快照后,模型会生成一个补丁,并根据实际测试进行评估。
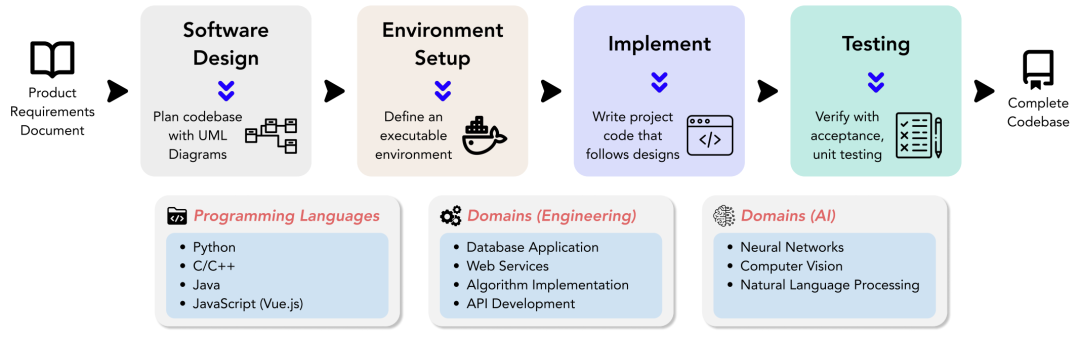 DevBench 具有软件开发的多个阶段,包括软件设计、环境设置、实施和测试(验收和单元测试)。
DevBench 具有软件开发的多个阶段,包括软件设计、环境设置、实施和测试(验收和单元测试)。
 (1)比较 4 种提示方法,(a)标准、(b)思维链(CoT,仅推理)、(c)仅行动和(d)ReAct(推理+行动),解决 HotpotQA问题。(2)比较(a)仅行动和(b)ReAct 提示以解决 AlfWorld游戏。在这两个领域中,我们省略了提示中的上下文示例,仅显示由模型(行动、思维)和环境(观察)生成的任务解决轨迹。
(1)比较 4 种提示方法,(a)标准、(b)思维链(CoT,仅推理)、(c)仅行动和(d)ReAct(推理+行动),解决 HotpotQA问题。(2)比较(a)仅行动和(b)ReAct 提示以解决 AlfWorld游戏。在这两个领域中,我们省略了提示中的上下文示例,仅显示由模型(行动、思维)和环境(观察)生成的任务解决轨迹。
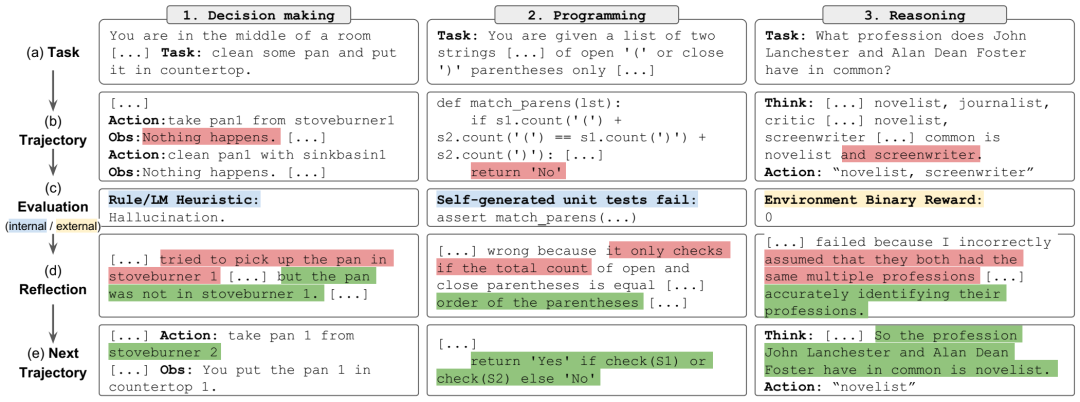 Reflexion 适用于决策(ALFWorld)、编程(HumanEval)和推理(HotpotQA)任务。与通过标量反馈反向传播的传统强化学习相比,Reflexion 可以看作是通过更通用、更灵活的语言反馈的反射推理进行的“语言强化学习”。
Reflexion 适用于决策(ALFWorld)、编程(HumanEval)和推理(HotpotQA)任务。与通过标量反馈反向传播的传统强化学习相比,Reflexion 可以看作是通过更通用、更灵活的语言反馈的反射推理进行的“语言强化学习”。
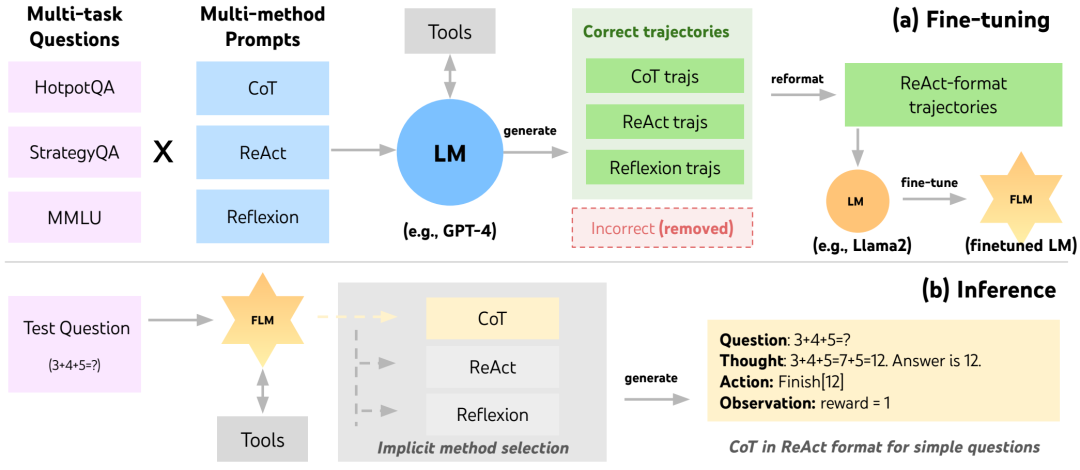 FireAct 的图示。(a)在微调过程中,大型 LM(例如 GPT-4)根据来自不同数据集的问题和来自不同方法的提示生成任务解决轨迹。然后将成功的轨迹转换为 ReAct 格式以微调较小的 LM。(b)在推理过程中,经过微调的 LM 可以在没有少量提示的情况下运行,并且可以隐式地选择一种提示方法来完成具有灵活长度的 ReAct 轨迹,以适应不同的问题复杂性。例如,一个简单的问题可以只使用一个思考-行动-观察回合来解决,而无需使用工具。
FireAct 的图示。(a)在微调过程中,大型 LM(例如 GPT-4)根据来自不同数据集的问题和来自不同方法的提示生成任务解决轨迹。然后将成功的轨迹转换为 ReAct 格式以微调较小的 LM。(b)在推理过程中,经过微调的 LM 可以在没有少量提示的情况下运行,并且可以隐式地选择一种提示方法来完成具有灵活长度的 ReAct 轨迹,以适应不同的问题复杂性。例如,一个简单的问题可以只使用一个思考-行动-观察回合来解决,而无需使用工具。
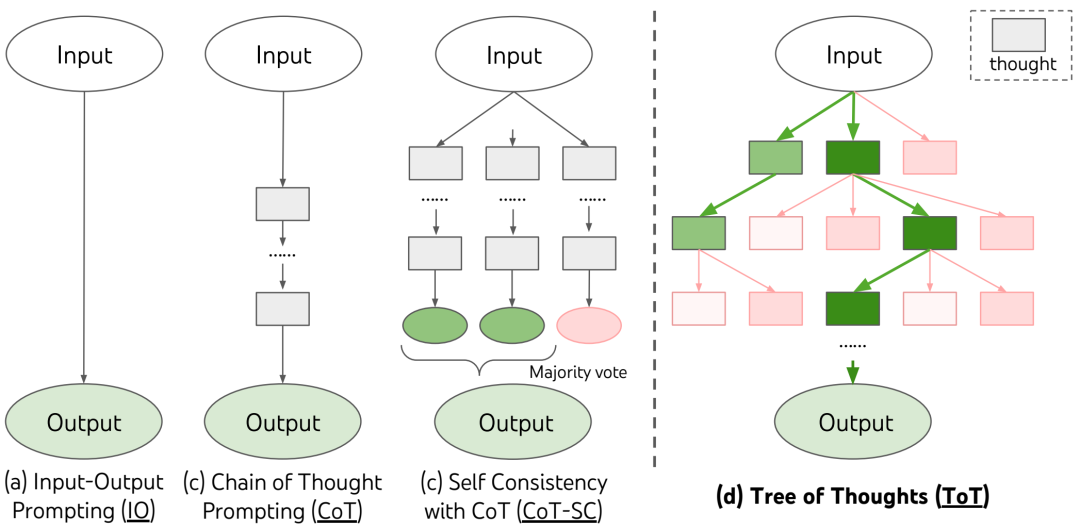 示意图展示了使用 LLM 解决问题的各种方法。每个矩形框代表一个想法,这是一个连贯的语言序列,是解决问题的中间步骤。请参见图 5.2、5.4、5.6 中关于如何生成、评估和搜索想法的具体示例。
示意图展示了使用 LLM 解决问题的各种方法。每个矩形框代表一个想法,这是一个连贯的语言序列,是解决问题的中间步骤。请参见图 5.2、5.4、5.6 中关于如何生成、评估和搜索想法的具体示例。
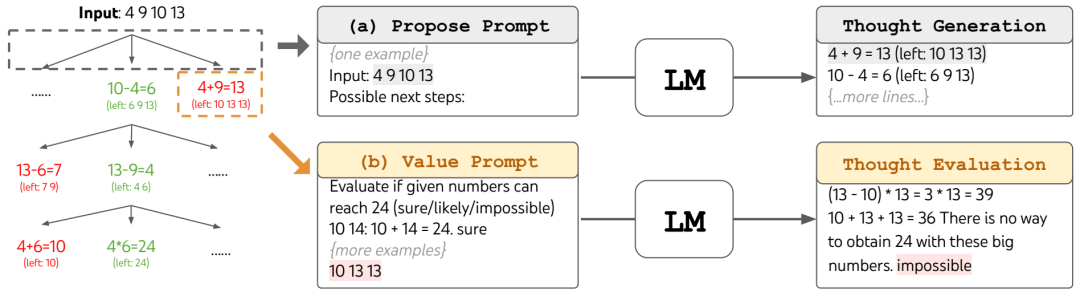 24 场游戏中的 ToT。LM 被提示 (a) 产生思想和 (b) 评估。
24 场游戏中的 ToT。LM 被提示 (a) 产生思想和 (b) 评估。
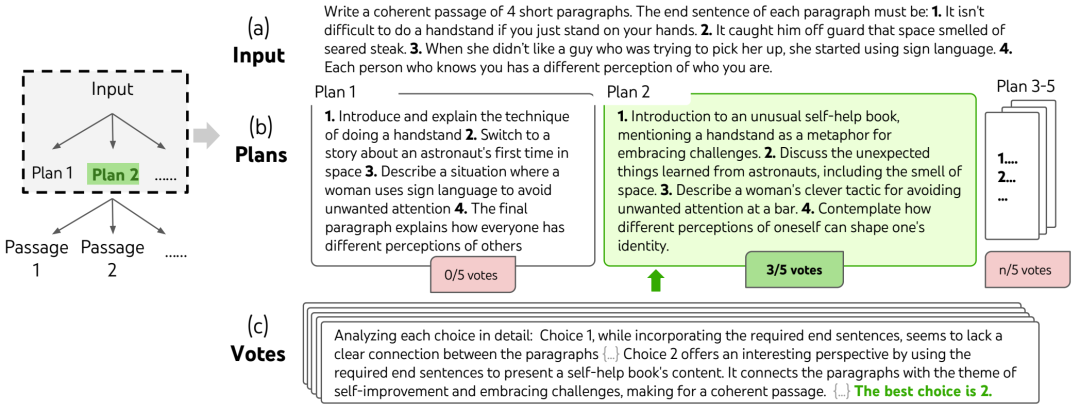 随机挑选的创意写作任务中的深思熟虑搜索步骤。给定输入,LM 抽样 5 个不同的方案,然后投票 5 次以决定哪个方案最佳。随后使用多数选择,通过相同的抽样投票程序编写输出段落。
随机挑选的创意写作任务中的深思熟虑搜索步骤。给定输入,LM 抽样 5 个不同的方案,然后投票 5 次以决定哪个方案最佳。随后使用多数选择,通过相同的抽样投票程序编写输出段落。
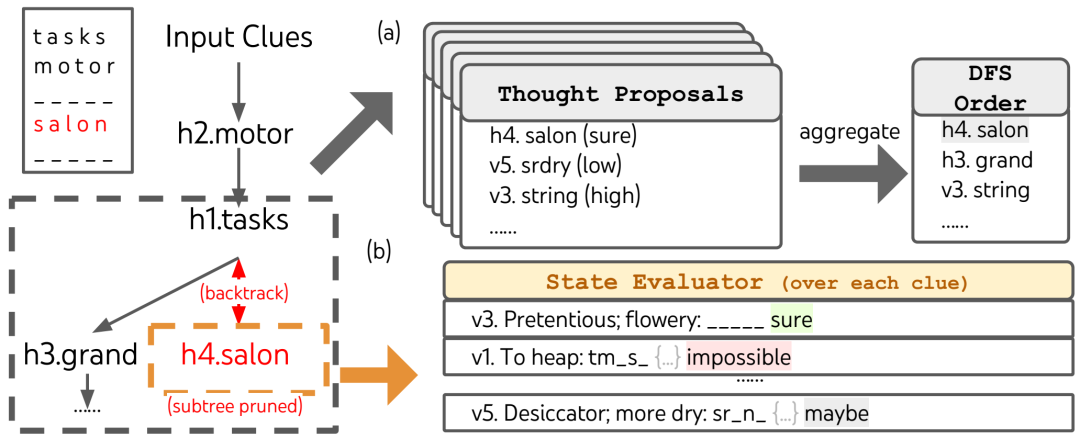 在迷你填字游戏中,(a) 如何提出想法并将其汇总到优先级队列中以进行深度优先搜索 (DFS),以及 (b) 如何根据填写每个剩余单词线索的可能性来评估状态,如果任何剩余线索被 LM 认为不可能填写,则删除该状态。然后,DFS 回溯到父状态并探索下一个有希望的线索想法。
在迷你填字游戏中,(a) 如何提出想法并将其汇总到优先级队列中以进行深度优先搜索 (DFS),以及 (b) 如何根据填写每个剩余单词线索的可能性来评估状态,如果任何剩余线索被 LM 认为不可能填写,则删除该状态。然后,DFS 回溯到父状态并探索下一个有希望的线索想法。
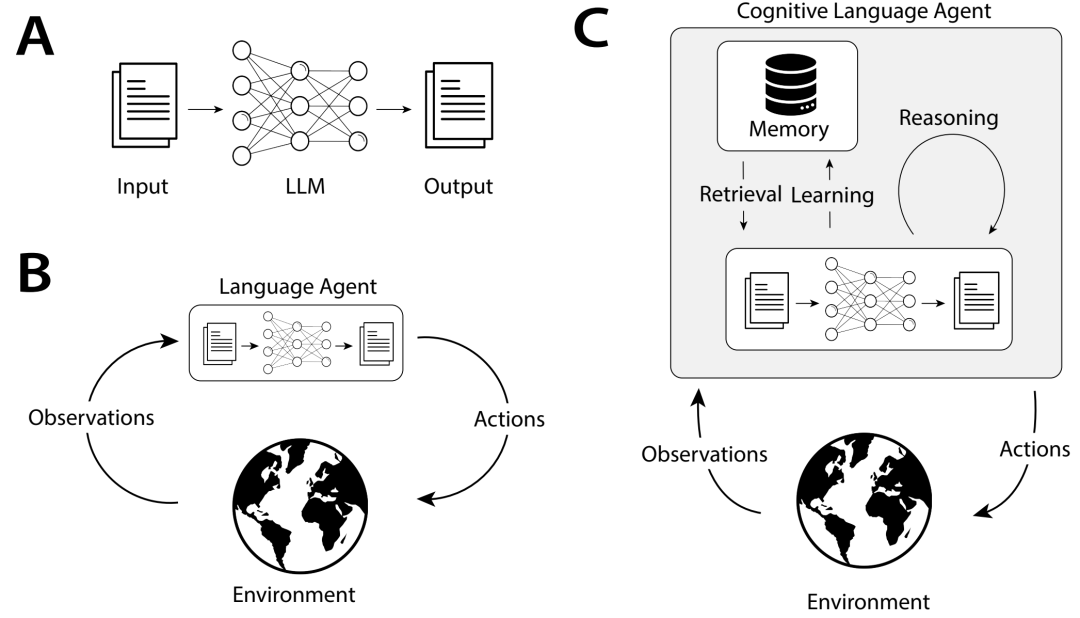 大型语言模型 (LLM) 的不同用途。A:在自然语言处理 (NLP) 中,LLM 将文本作为输入并输出文本。B:语言Agents通过将观察结果转换为文本并使用 LLM 选择操作,将 LLM 置于与外部环境的直接反馈循环中。C:认知语言Agents还使用 LLM 通过学习和推理等过程来管理Agents的内部状态。在这项工作中,我们提出了构建此类Agents的蓝图。
大型语言模型 (LLM) 的不同用途。A:在自然语言处理 (NLP) 中,LLM 将文本作为输入并输出文本。B:语言Agents通过将观察结果转换为文本并使用 LLM 选择操作,将 LLM 置于与外部环境的直接反馈循环中。C:认知语言Agents还使用 LLM 通过学习和推理等过程来管理Agents的内部状态。在这项工作中,我们提出了构建此类Agents的蓝图。
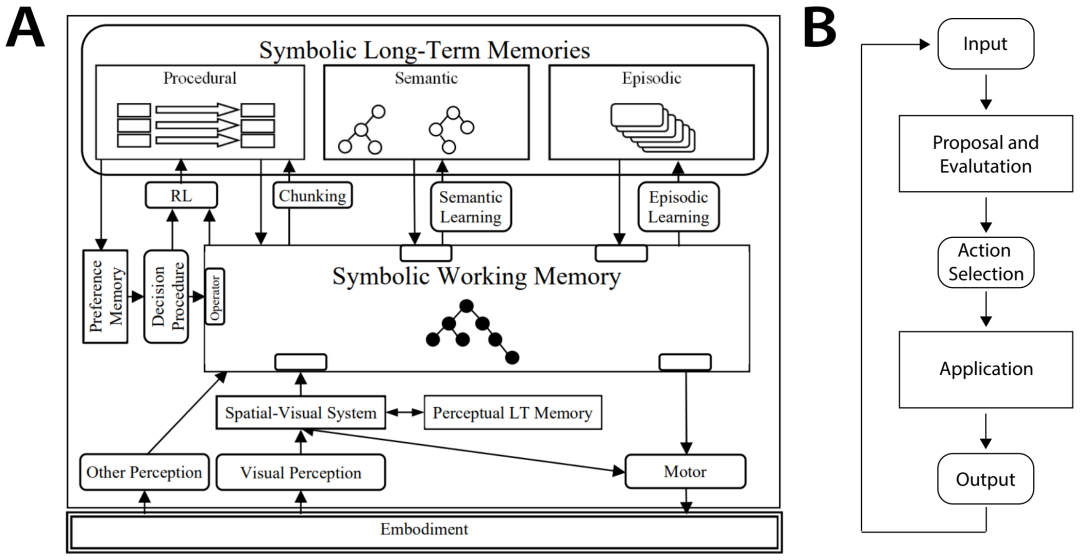 认知架构通过感官基础、长期记忆和选择动作的决策程序增强了生产系统。A:Soar 架构。B:Soar 的决策程序使用生产来选择和实施动作。这些动作可能是内部的(例如修改Agents的记忆)或外部的(例如运动命)令)。
认知架构通过感官基础、长期记忆和选择动作的决策程序增强了生产系统。A:Soar 架构。B:Soar 的决策程序使用生产来选择和实施动作。这些动作可能是内部的(例如修改Agents的记忆)或外部的(例如运动命)令)。
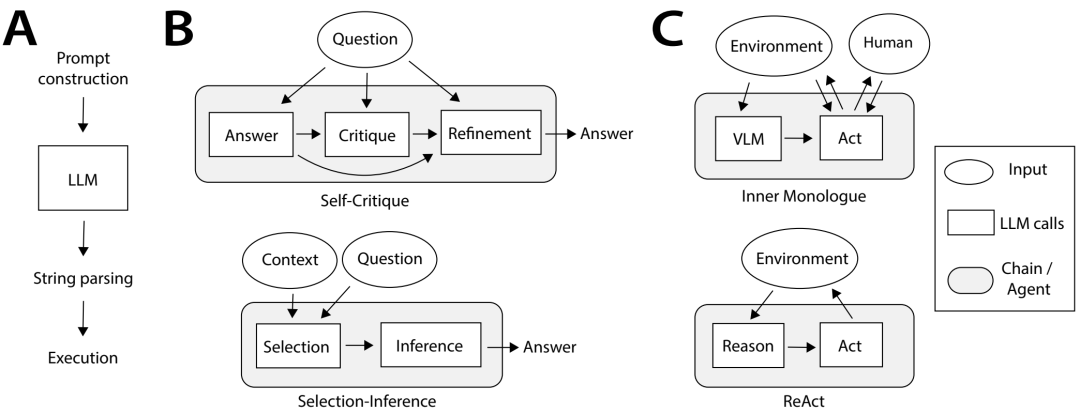 从语言模型到语言Agents。A:LLM 调用的基本结构。提示构造选择一个模板并用工作内存中的变量填充它。调用 LLM 后,字符串输出被解析为动作空间并执行。LLM 调用可能导致一个或多个动作 - 例如,返回答案、调用函数或发出运动命令。B:提示链技术(如自我批评或选择推理)使用预定义的 LLM 调用序列来生成输出。C:语言Agents(如 Inner Monologue和 ReAct)改为使用与外部环境的交互式反馈循环。视觉语言模型 (VLM) 可用于将感知数据转换为文本以供 LLM 处理。
从语言模型到语言Agents。A:LLM 调用的基本结构。提示构造选择一个模板并用工作内存中的变量填充它。调用 LLM 后,字符串输出被解析为动作空间并执行。LLM 调用可能导致一个或多个动作 - 例如,返回答案、调用函数或发出运动命令。B:提示链技术(如自我批评或选择推理)使用预定义的 LLM 调用序列来生成输出。C:语言Agents(如 Inner Monologue和 ReAct)改为使用与外部环境的交互式反馈循环。视觉语言模型 (VLM) 可用于将感知数据转换为文本以供 LLM 处理。
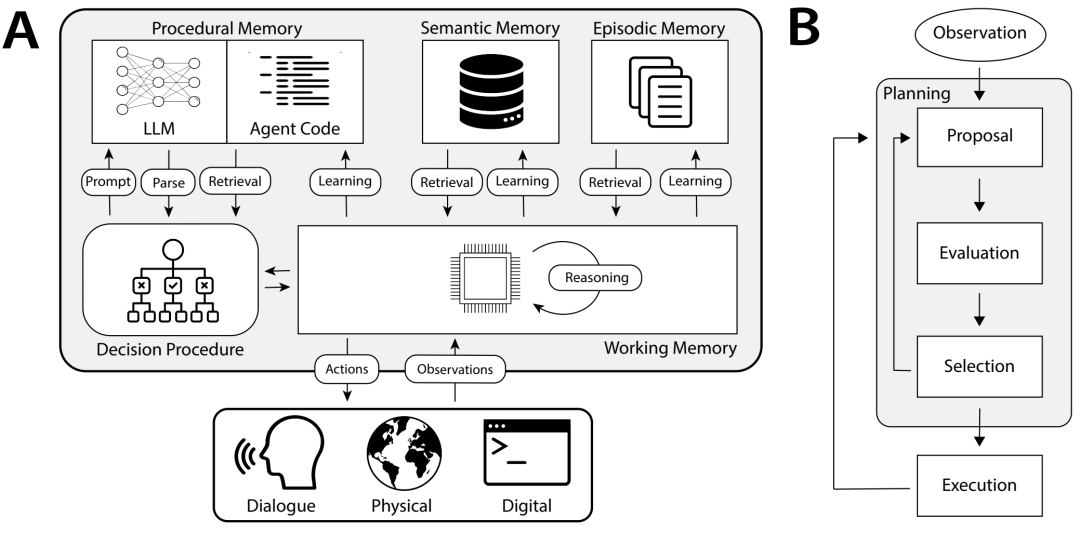 语言Agents的认知架构 (CoALA)。A:CoALA 定义了一组交互模块和流程。决策程序执行Agents的源代码。此源代码由与 LLM(提示模板和解析器)、内部存储器(检索和学习)和外部环境(基础)交互的程序组成。B:从时间上讲,Agents的决策程序与外部环境一起循环执行决策周期。在每个周期中,Agents使用检索和推理来规划,提出和评估候选学习或基础操作。然后选择并执行最佳操作。可以进行观察,然后循环再次开始。
语言Agents的认知架构 (CoALA)。A:CoALA 定义了一组交互模块和流程。决策程序执行Agents的源代码。此源代码由与 LLM(提示模板和解析器)、内部存储器(检索和学习)和外部环境(基础)交互的程序组成。B:从时间上讲,Agents的决策程序与外部环境一起循环执行决策周期。在每个周期中,Agents使用检索和推理来规划,提出和评估候选学习或基础操作。然后选择并执行最佳操作。可以进行观察,然后循环再次开始。
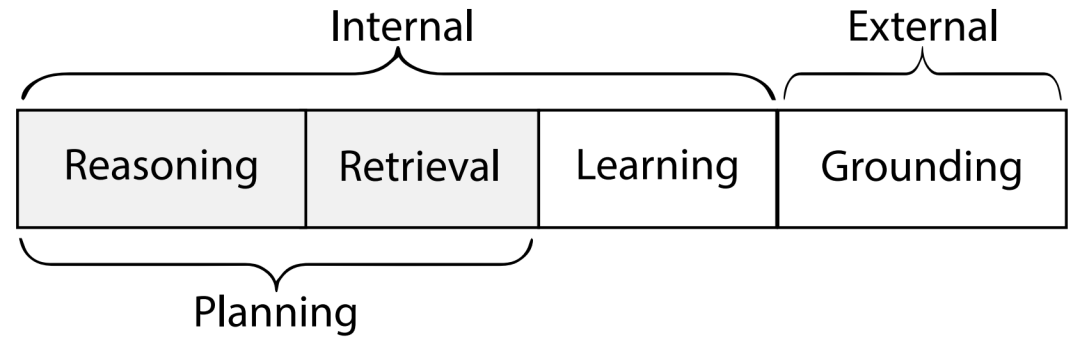 Agents的动作空间可以分为内部记忆访问和与世界的外部交互。推理和检索动作用于支持规划。
Agents的动作空间可以分为内部记忆访问和与世界的外部交互。推理和检索动作用于支持规划。





微信群 公众号


