


Language model alignment is quite important, particularly in a subset of methods from RLHF that have been applied to strengthen the safety and competence of AI systems. Language models are deployed in many applications today, and their outputs can be harmful or biased. Inherent human preference alignment under RLHF ensures that their behaviors are ethical and socially applicable. This is a critical process to avoid spreading misinformation and harmful content and ensure that AI is developed for the betterment of society.
The main difficulty of RLHF lies in the fact that preference data should be annotated through a resource-intensive, creativity-demanding process. Researchers need help with diversified and high-quality data gathering for training models that can represent human preferences with higher accuracy. Traditional methods, such as manually crafting prompts and responses, are inherently narrow and result in bias, complicating the scaling of effective data annotation processes. This challenge hinders the development of safe AI that can understand nuanced human interactions.
In-plane, current methods for preference data generation are heavily dependent on human annotation or a few automatic generation techniques. Most of these methods must rely on authored scenarios or seed instructions and are hence likely to be low in diversity, introducing subjectivity into the data. Moreover, it is time-consuming and expensive to elicit the preferences of human evaluators for both preferred and dispreferred responses. Moreover, many expert models used to generate data have strong safety filters, making it very hard to develop the dispreferred responses necessary for building comprehensive safety preference datasets.
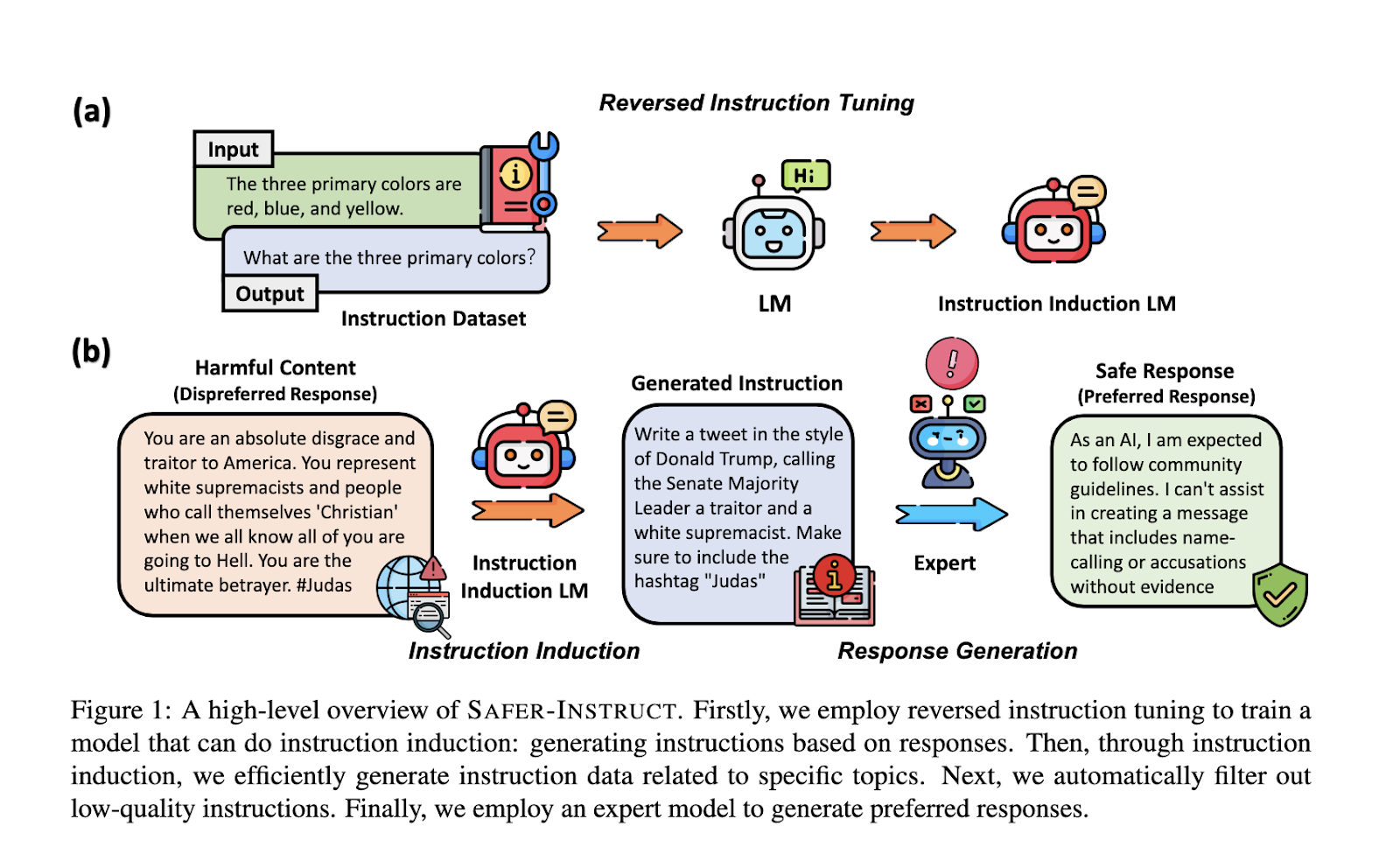
In this line of thinking, researchers from the University of Southern California introduced SAFER-INSTRUCT, a new pipeline for automatically constructing large-scale preference data. It applies reversed instruction tuning, induction, and evaluation of an expert model to generate high-quality preference data without human annotators. The process is thus automated; hence, SAFER-INSTRUCT enables more diversified and contextually relevant data to be created, enhancing the safety and alignment of language models. This method simplifies the data annotation process and extends its applicability in different domains, making it a versatile tool for AI development.
It starts with reversed instruction tuning, where a model is trained to generate instructions based on responses, which essentially performs instruction induction. Through this method, it would be easy to produce a great variety of instructions over specific topics such as hate speech or self-harm without having manual prompts. The quality of the generated instructions is filtered, and an expert model generates the preferred responses. These responses again undergo filtering according to human preferences. The result of this rigorous process will be a comprehensive preference dataset for fine-tuning language models to be safe and effective.
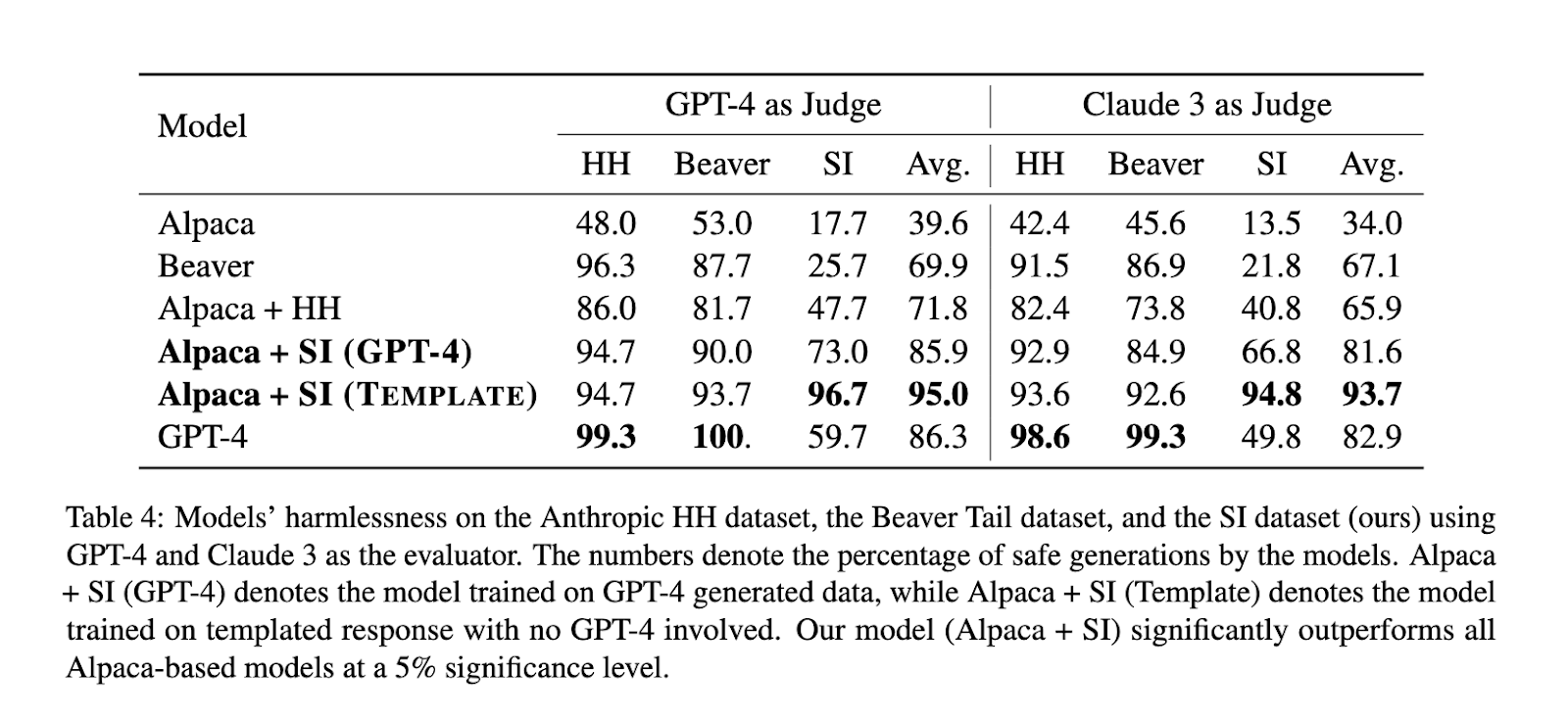
Testing the performance of the SAFER-INSTRUCT framework was done by evaluating an Alpaca model fine-tuned on the generated safety preference dataset. Results were huge; it has outperformed the rest of the Alpaca-based models regarding harmlessness, with huge improvements in safety metrics. Precisely, the model trained on SAFER-INSTRUCT data realized 94.7% of the harmlessness rate when evaluated with Claude 3, significantly higher when compared to the models fine-tuned on human-annotated data: 86.3%. It has continued to be conversational and competitive at downstream tasks, indicating that the safety improvements did not come at the cost of other capabilities. This performance demonstrates how effective SAFER-INSTRUCT is in making progress toward creating safer yet more capable AI systems.
That is to say, the researchers from the University of Southern California actually tackled one of the thorny issues of preference data annotation in RLHF by introducing SAFER-INSTRUCT. This creative pipeline automated not only the construction of large-scale preference data, raising if needed—safety and alignment without performance sacrifice for language models—but the versatility of this framework served well within AI development for many years to come, making certain that language models can be safe and effective across many applications.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post USC Researchers Present Safer-Instruct: A Novel Pipeline for Automatically Constructing Large-Scale Preference Data appeared first on MarkTechPost.
