


Large Language Models (LLMs) have gained significant attention due to their remarkable performance across various tasks, revolutionizing research paradigms. However, the training process for these models faces several challenges. LLMs depend on static datasets and undergo long training periods, which require a lot of computational resources. For example, training the LLaMA 65B model took 21 days using 2048 A100 GPUs with 80GB of RAM. This method poses limitations in adapting to changes in data composition or containing new information. So, it is important to develop more efficient and flexible training methodologies for LLMs to improve their adaptability and reduce computational demands.
Researchers from the Language Foundation Model & Software Team at BAAI have proposed the Aquila2 series, a range of AI models with parameter sizes from 7 to 70 billion. These models are trained using the HeuriMentor (HM) Framework, which contains three essential components, (a) the Adaptive Training Engine (ATE), (b) the Training State Monitor (TSM), and (c) the Data Management Unit (DMU). This system enhances the monitoring of the model’s training progress and allows for efficient adjustments to the data distribution, making training more effective. The HM Framework is designed to tackle the challenges of adapting to changes in data and incorporating new information, providing a more flexible and efficient way to train LLMs.

The Aquila2 architecture includes several important features to enhance its performance and efficiency. The tokenizer uses a 100,000-word vocabulary, chosen through initial experiments, and applies Byte Pair Encoding (BPE) to extract this vocabulary. The training data is evenly split between English and Chinese, using the Pile and WudaoCorpus datasets. Aquila2 uses the Grouped Query Attention (GQA) mechanism, which improves efficiency during inference compared to traditional multi-head attention while maintaining similar quality. The model uses a popular method of LLMs, called Rotary Position Embedding (RoPE), for position embedding. RoPE combines the benefits of relative and absolute position encoding, to capture patterns efficiently in sequence data.
The performance of the Aquila2 model has been thoroughly evaluated and compared with other major bilingual (Chinese-English) models released before December 2023. The models included for comparisons are Baichuan2, Qwen, LLaMA2, and InternLM, each having unique characteristics and parameter sizes. Baichuan2 offers 7B and 13B versions trained on 2.6 trillion tokens. Qwen presents a complete series of models, with chat-optimized versions. LLaMA2 ranges from 7B to 70B parameters, with fine-tuned chat versions. InternLM shows a huge 104B parameter model trained on 1.6 trillion tokens, with 7B and 20B versions. These comparisons across various datasets provide a detailed analysis of Aquila2’s capabilities.
The Aquila2-34B model shows strong performance across various NLP tasks, achieving the highest mean score of 68.09 in comparative evaluations. It performs well in English (68.63 average) and Chinese (76.56 average) language tasks. Aquila2-34B outperforms LLaMA2-70B in bilingual understanding, achieving its top score of 81.18 in the BUSTM task. Moreover, Aquila2-34B leads in the challenging HumanEval task with a score of 39.02, indicating strong human-like understanding. The evaluation reveals a competitive landscape across various models, with close contests in tasks like TNEWS and C-Eval. These results show the need for thorough evaluations in diverse tasks to understand model capabilities and drive NLP progress.
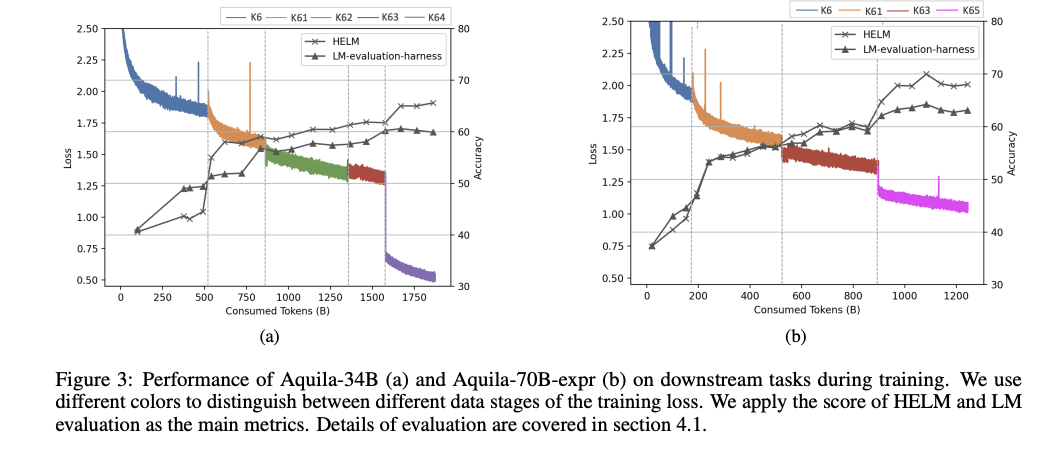
In conclusion, Researchers from the Language Foundation Model & Software Team at BAAI have proposed the Aquila2 series, a range of bilingual models with parameter sizes from 7 to 70 billion. Aquila2-34B shows superior performance across 21 diverse datasets, outperforming LLaMA-2-70B-expr and other benchmarks, even under 4-bit quantization. Moreover, the HM framework developed by researchers, enables dynamic adjustments to data distribution during training, resulting in faster convergence and enhanced model quality. Future research includes exploring Mixture-of-Experts and improving data quality. However, incorporating GSM8K test data in pre-training may affect the validity of Aquila2’s results, requiring caution in future comparisons.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post Aquila2: Advanced Bilingual Language Models Ranging from 7 to 70 Billion Parameters appeared first on MarkTechPost.
