


Effectively aligning large language models (LLMs) with human instructions is a critical challenge in the field of AI. Current LLMs often struggle to generate responses that are both accurate and contextually relevant to user instructions, particularly when relying on synthetic data. Traditional methods, such as model distillation and human-annotated datasets, have their own limitations, including scalability issues and a lack of data diversity. Addressing these challenges is essential for enhancing the performance of AI systems in real-world applications, where they must interpret and execute a wide range of user-defined tasks.
Current approaches to instruction alignment primarily rely on human-annotated datasets and synthetic data generated through model distillation. While human-annotated data is high in quality, it is expensive and difficult to scale. On the other hand, synthetic data, often produced via distillation from larger models, tends to lack diversity and may lead to models that overfit to specific types of tasks, thereby limiting their ability to generalize to new instructions. These limitations, including high costs and the “false promise” of distillation, hinder the development of robust, versatile LLMs capable of handling a broad spectrum of tasks.
A team of researchers from University of Washington and Meta Fair propose a novel method known as “instruction back-and-forth translation.” This approach enhances the generation of synthetic instruction-response pairs by integrating backtranslation with response rewriting. Initially, instructions are generated from pre-existing responses extracted from large-scale web corpora. These responses are then refined by an LLM, which rewrites them to better align with the generated instructions. This innovative method leverages the rich diversity of information available on the web while ensuring high-quality, instruction-following data, marking a significant advancement in the field.
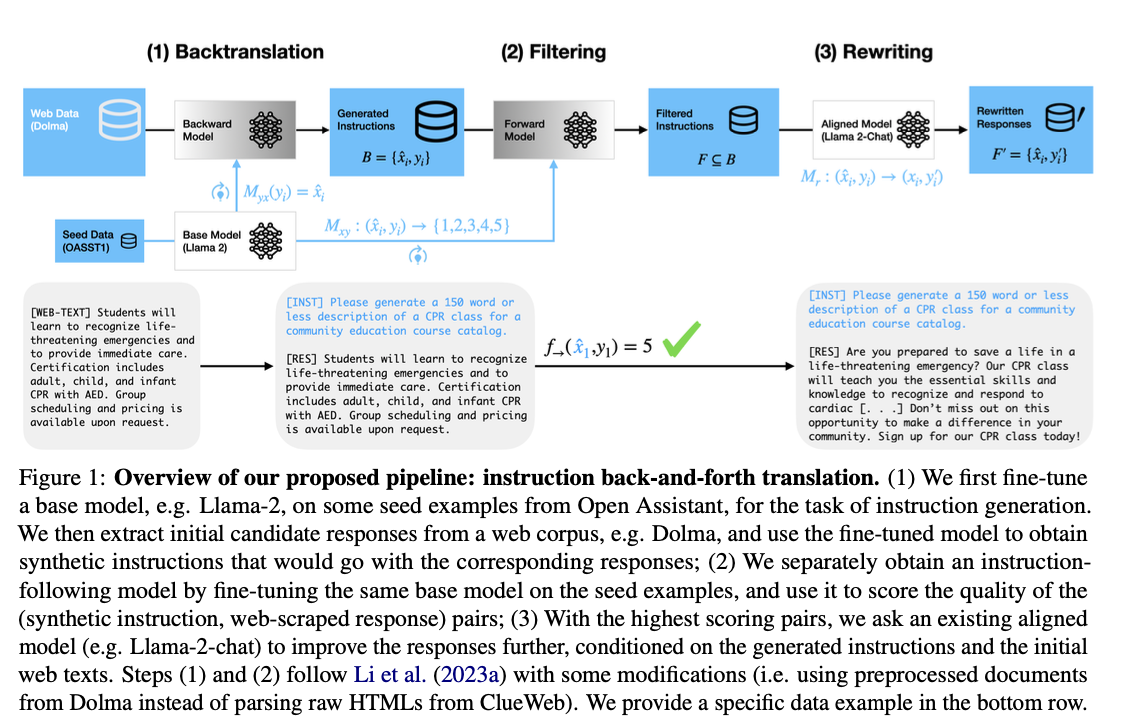
The approach involves fine-tuning a base LLM on seed data to create instructions that match web-scraped responses. The Dolma corpus, a large-scale open-source dataset, provides the source of these responses. After generating the initial instruction-response pairs, a filtering step retains only the highest quality pairs. An aligned LLM, such as Llama-2-70B-chat, then rewrites the responses to further enhance their quality. Nucleus sampling is employed for response generation, with a focus on both filtering and rewriting to ensure data quality. Testing against several baseline datasets reveals superior performance for models fine-tuned on synthetic data generated through this technique.
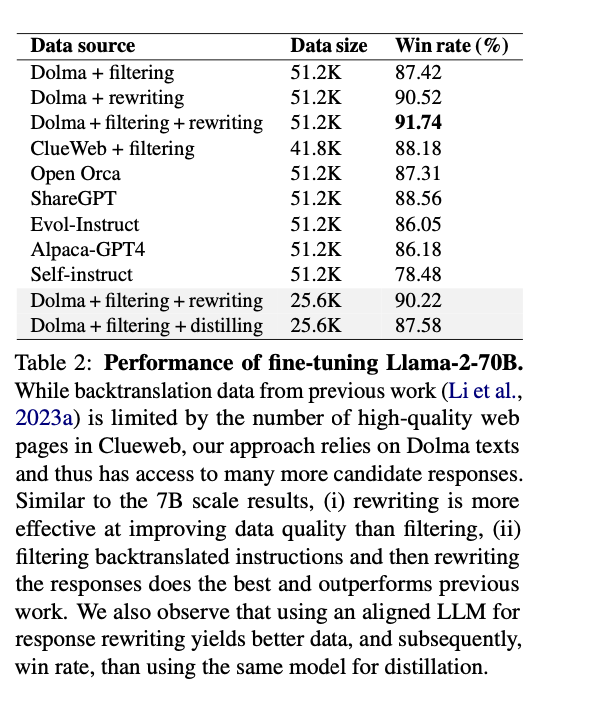
This new method achieves significant improvements in model performance across various benchmarks. Models fine-tuned using the Dolma + filtering + rewriting dataset attain a win rate of 91.74% on the AlpacaEval benchmark, surpassing models trained on other prevalent datasets such as OpenOrca and ShareGPT. Additionally, it outperforms previous approaches using data from ClueWeb, demonstrating its effectiveness in generating high-quality, diverse instruction-following data. The enhanced performance underscores the success of the back-and-forth translation technique in producing better-aligned and more accurate large language models.
In conclusion, the introduction of this new method for generating high-quality synthetic data marks a significant advancement in aligning LLMs with human instructions. By combining back-translation with response rewriting, researchers have developed a scalable and effective approach that improves the performance of instruction-following models. This advancement is crucial for the AI field, offering a more efficient and accurate solution for instruction alignment, which is essential for deploying LLMs in practical applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post Cracking the Code of AI Alignment: This AI Paper from the University of Washington and Meta FAIR Unveils Better Alignment with Instruction Back-and-Forth Translation appeared first on MarkTechPost.
