


The research paper titled “ControlNeXt: Powerful and Efficient Control for Image and Video Generation” addresses a significant challenge in generative models, particularly in the context of image and video generation. As diffusion models have gained prominence for their ability to produce high-quality outputs, the need for fine-grained control over these generated results has become increasingly important. Traditional methods, such as ControlNet and Adapters, have attempted to enhance controllability by integrating additional architectures. However, these approaches often lead to substantial increases in computational demands, particularly in video generation, where the processing of each frame can double GPU memory consumption. This paper highlights the limitations of existing methods, which need to improve with high resource requirements and weak control. It introduces ControlNeXt as a more efficient and robust solution for controllable visual generation.
Existing architectures typically rely on parallel branches or adapters to incorporate control information, which can significantly inflate the model’s complexity and training requirements. For instance, ControlNet employs additional layers to process control conditions alongside the main generation process. However, this architecture can lead to increased latency and training difficulties, particularly due to the introduction of zero convolution layers that complicate convergence. In contrast, the proposed ControlNeXt method aims to streamline this process by replacing heavy additional branches with a more straightforward, efficient architecture. This design minimizes the computational burden while maintaining the ability to integrate with other low-rank adaptation (LoRA) weights, allowing for style alterations without necessitating extensive retraining.
Delving deeper into the proposed method, ControlNeXt introduces a novel architecture that significantly reduces the number of learnable parameters to 90% less than its predecessors. This is achieved using a lightweight convolutional network to extract conditional control features rather than relying on a parallel control branch. The architecture is designed to maintain compatibility with existing diffusion models while enhancing efficiency. Furthermore, the introduction of Cross Normalization (CN) replaces zero convolution, addressing the slow convergence and training challenges typically associated with standard methods. Cross Normalization aligns the data distributions of new and pre-trained parameters, facilitating a more stable training process. This innovative approach optimizes the training time and enhances the model’s overall performance across various tasks.
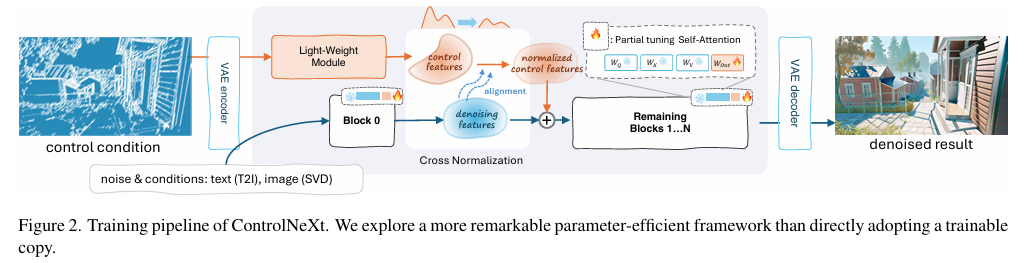
The performance of ControlNeXt has been rigorously evaluated through a series of experiments involving different base models for image and video generation. The results demonstrate that ControlNeXt effectively retains the original model’s architecture while introducing only a minimal number of auxiliary components. This lightweight design allows seamless integration as a plug-and-play module with existing systems. The experiments reveal that ControlNeXt achieves remarkable efficiency, with significantly reduced latency overhead and parameter counts compared to traditional methods. The ability to fine-tune large pre-trained models with minimal additional complexity positions ControlNeXt as a robust solution for a wide range of generative tasks, enhancing the quality and controllability of generated outputs.
In conclusion, the research paper presents ControlNeXt as a powerful and efficient method for image and video generation that addresses the critical issues of high computational demands and weak control in existing models. By simplifying the architecture and introducing Cross Normalization, the authors provide a solution that not only enhances performance but also maintains compatibility with established frameworks. ControlNeXt stands out as a significant advancement in the field of controllable generative models, promising to facilitate more precise and efficient generation of visual content.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post Efficient and Robust Controllable Generation: ControlNeXt Revolutionizes Image and Video Creation appeared first on MarkTechPost.
