


Zyphra announced the release of Zyda, a groundbreaking 1.3 trillion-token open dataset for language modeling. This innovative dataset is set to redefine the standards of language model training and research, offering an unparalleled combination of size, quality, and accessibility.
Zyda amalgamates several high-quality open datasets, refining them through rigorous filtering and deduplication. The result is a dataset that boasts an impressive token count and maintains the highest data quality standards.
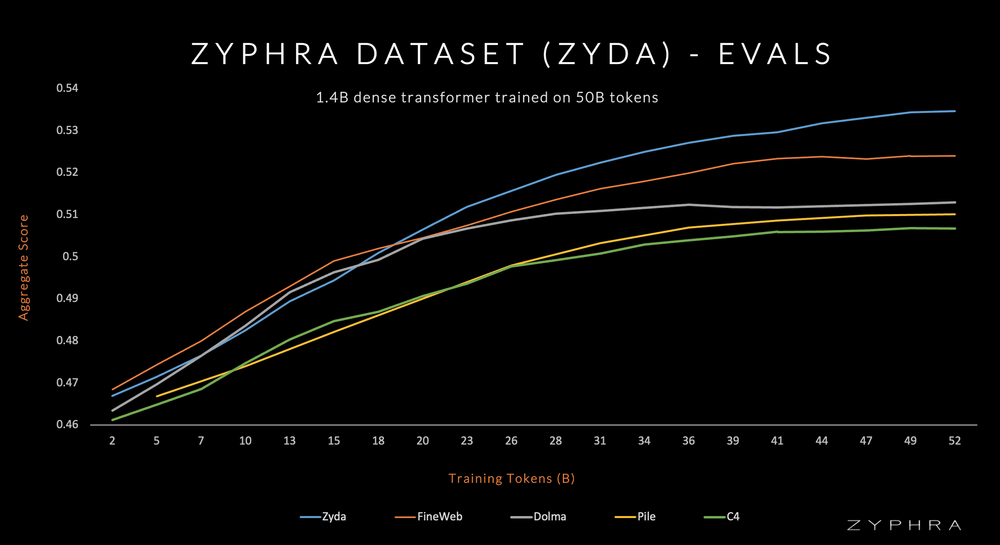
Zyda’s primary aim is to facilitate advanced language modeling experiments and training at a scale previously unattainable with open datasets. Zyda has consistently outperformed existing datasets in comprehensive ablation studies, including Dolma, Fineweb, Pile, RefinedWeb, and SlimPajama. This makes Zyda a crucial resource for researchers & developers seeking to contribute to language modeling.
Key Features of Zyda
- Unmatched Token Count: Zyda comprises 1.3 trillion meticulously filtered and deduplicated tokens collated from high-quality datasets. This extensive token count ensures that models trained on Zyda can achieve unprecedented accuracy and robustness.Superior Performance: Zyda outshines all major open language modeling datasets in comparative evaluations. This includes outperforming individual subsets of these datasets, highlighting the effectiveness of Zyda’s comprehensive approach to data aggregation and processing.Cross-Dataset Deduplication: A standout feature of Zyda is its implementation of cross-dataset deduplication. This process ensures that duplicates are eliminated within and between individual datasets. This is crucial for maintaining the integrity and uniqueness of the data, especially given the common sources of many open datasets.Open and Permissive License: Zyda is released under an open and permissive license, making it freely accessible to the community. This aligns with Zyphra’s commitment to fostering open research and collaboration in NLP.
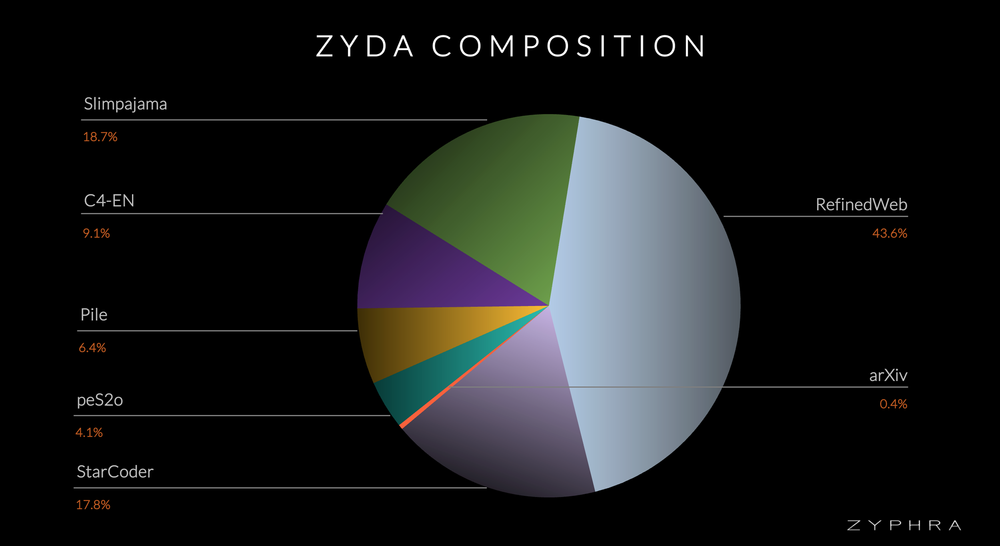
Zyda was meticulously crafted by merging seven well-respected open language modeling datasets: RefinedWeb, Starcoder, C4, Pile, Slimpajama, pe2so, and arXiv. Each dataset underwent a uniform post-processing pipeline designed to enhance quality and coherence.
The creation process involved thorough syntactic filtering to eliminate low-quality documents, followed by an aggressive deduplication pass. Cross-deduplication was particularly important, as many datasets contained significant overlaps due to common data sources like Common Crawl. This extensive cleaning process reduced the initial 2 trillion tokens to a more refined and manageable 1.3 trillion.
The efficacy of Zyda is evident in the performance of Zamba, a language model trained on Zyda. Zamba demonstrates significant strength on a per-token basis compared to models trained on competing datasets. This is a testament to Zyda’s superior quality and potential to drive language modeling advancements.
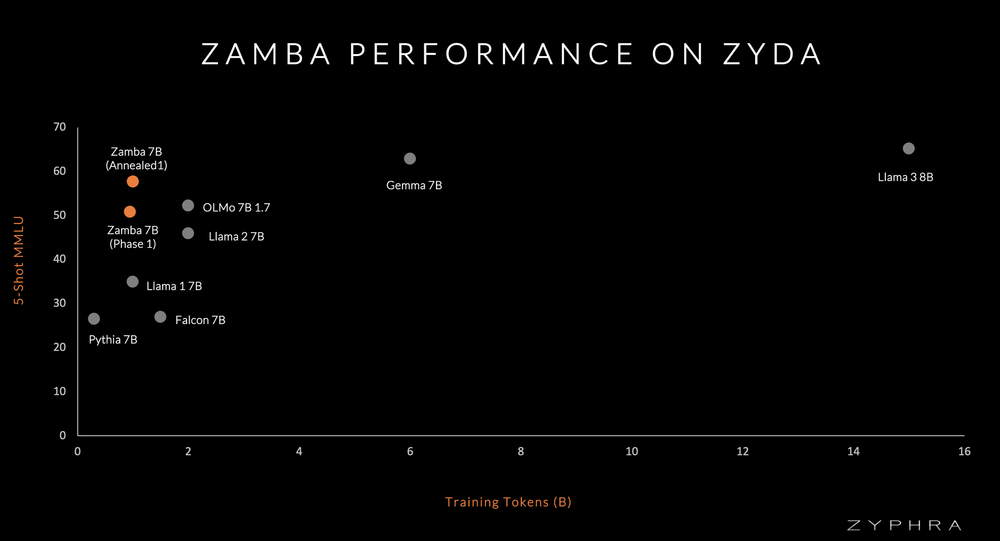
In conclusion, Zyda represents a monumental leap forward in language modeling. Zyphra is paving the way for the next generation of NLP research and applications by providing a massive, high-quality, open dataset. The release of Zyda not only underscores Zyphra’s leadership in the field but also sets a new benchmark for what is possible with open datasets.
The post Zyphra Introduces Zyda Dataset: A 1.3 Trillion Token Dataset for Open Language Modeling appeared first on MarkTechPost.
