


The Technology Innovation Institute (TII) in Abu Dhabi has recently unveiled the FalconMamba 7B, a groundbreaking artificial intelligence model. This model, the first strong attention-free 7B model, is designed to overcome many of the limitations existing AI architectures face, particularly in handling large data sequences. The FalconMamba 7B is released under the TII Falcon License 2.0. It is available as an open-access model within the Hugging Face ecosystem, making it accessible for researchers and developers globally.
FalconMamba 7B distinguishes itself based on the Mamba architecture, originally proposed in the paper “Mamba: Linear-Time Sequence Modeling with Selective State Spaces.” This architecture diverges from the traditional transformer models that dominate the AI landscape today. Transformers, while powerful, have a fundamental limitation in processing large sequences due to their reliance on attention mechanisms, which increase compute and memory costs with sequence length. FalconMamba 7B, however, overcomes these limitations through its architecture, which includes extra RMS normalization layers to ensure stable training at scale. This enables the model to process sequences of arbitrary length without an increase in memory storage, making it capable of fitting on a single A10 24GB GPU.
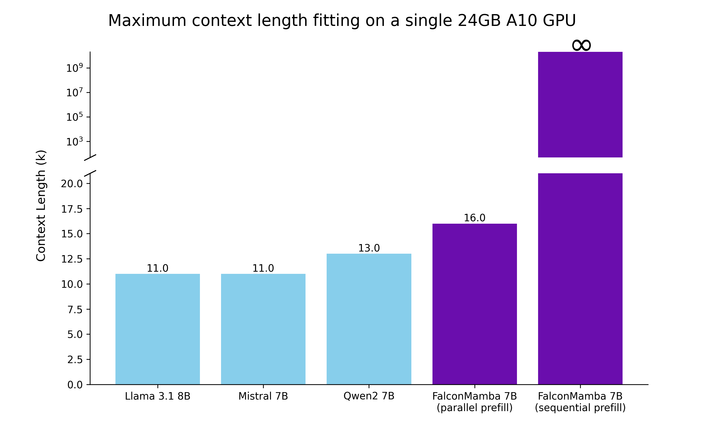
One of the standout features of FalconMamba 7B is its constant token generation time, irrespective of the context size. This is a great advantage over traditional models, where generation time typically increases with the context length due to the need to attend to all previous tokens in the context. The Mamba architecture addresses this by storing only its recurrent state, thus avoiding the linear scaling of memory requirements and generation time.
The training of FalconMamba 7B involved approximately 5500GT, primarily composed of RefinedWeb data, supplemented with high-quality technical and code data from public sources. The model was trained using a constant learning rate for most of the process, followed by a short learning rate decay stage. A small portion of high-quality curated data was added during this final stage to enhance the model’s performance further.

In terms of benchmarks, FalconMamba 7B has demonstrated impressive results across various evaluations. For example, the model scored 33.36 in the MATH benchmark, while in the MMLU-IFEval and BBH benchmarks, it scored 19.88 and 3.63, respectively. These results highlight the model’s strong performance compared to other state-of-the-art models, particularly in tasks requiring long sequence processing.
FalconMamba 7B’s architecture also enables it to fit larger sequences in a single 24GB A10 GPU compared to transformer models. It maintains a constant generation throughput without any increase in CUDA peak memory. This efficiency in handling large sequences makes FalconMamba 7B a highly versatile tool for applications requiring extensive data processing.
FalconMamba 7B is compatible with the Hugging Face transformers library (version >4.45.0). It supports features like bits and bytes quantization, which allows the model to run on smaller GPU memory constraints. This makes it accessible to many users, from academic researchers to industry professionals.
TII has introduced an instruction-tuned version of FalconMamba, fine-tuned with an additional 5 billion tokens of supervised fine-tuning data. This version enhances the model’s ability to perform instructional tasks more precisely and effectively. Users can also benefit from faster inference using torch.compile, further increasing the model’s utility in real-world applications.
In conclusion, the release of FalconMamba 7B by the Technology Innovation Institute, with its innovative architecture, impressive performance on benchmarks, and accessibility through the Hugging Face ecosystem, FalconMamba 7B, is poised to make a substantial impact across various sectors.
Check out the Model and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post FalconMamba 7B Released: The World’s First Attention-Free AI Model with 5500GT Training Data and 7 Billion Parameters appeared first on MarkTechPost.
