


Unit testing aims to identify and resolve bugs at the earliest stages by testing individual components or units of code. This process ensures software reliability and quality before the final product is delivered. Traditional methods of unit test generation, such as search-based, constraint-based, and random-based techniques, have been utilized to automate the creation of unit tests. These methods aim to maximize the coverage of software components, thereby minimizing the chances of undetected bugs. However, the manual creation and maintenance of unit tests are time-consuming and labor-intensive, necessitating the development of automated solutions.
The primary challenge in automated unit test generation lies in the limitations of existing methods. Large Language Models (LLMs), such as ChatGPT, have shown significant potential in generating unit tests. However, these models often fall short due to their inability to create valid test cases consistently. Common issues include compilation errors caused by insufficient context, runtime errors resulting from inadequate feedback mechanisms, and repetitive loops during self-repair attempts, which hinder the models from producing high-quality test cases. These limitations highlight the need for more robust and reliable methods to leverage LLMs’ strengths while addressing their inherent weaknesses.
Existing automated unit test generation tools, including those based on search-based software testing (SBST) and LLMs, offer various approaches to tackle these challenges. SBST tools like EvoSuite employ evolutionary algorithms to create test cases that aim to improve code coverage. However, the tests generated by these tools often differ significantly from human-written tests, making them difficult to read, understand, and modify. On the other hand, while more aligned with human-like reasoning, LLM-based methods still need help with issues such as invalid context handling and low pass rates. These existing methods need to be revised to ensure the development of a more effective solution.

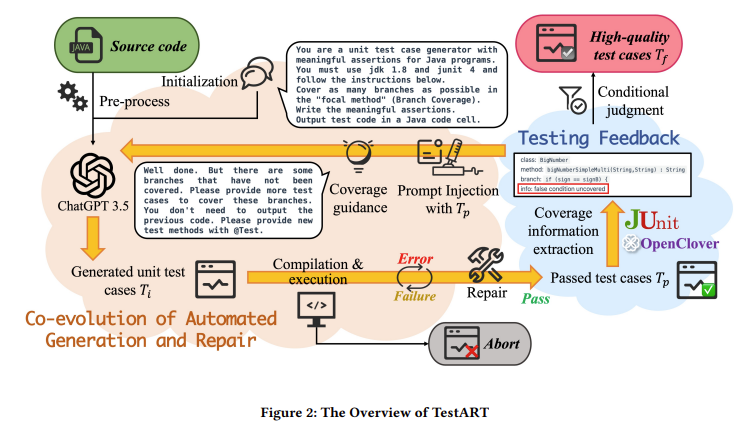
Researchers from Nanjing University and Huawei Cloud Computing Technologies Co., Ltd. have introduced a novel approach called TestART. This method enhances LLM-based unit test generation through a co-evolutionary process integrating automated generation with iterative repair. TestART is designed to overcome the limitations of LLMs by incorporating template-based repair techniques and prompt injection mechanisms. These innovations guide the model’s subsequent generation processes, helping to avoid repetition and enhance the overall quality of the generated test cases.
TestART operates by first generating initial unit test cases using the ChatGPT-3.5 model. These initial test cases are then subjected to a rigorous repair process that addresses common issues such as compilation errors, runtime failures, and assertion errors. The repair process employs fixed templates tailored to correct the mistakes typically produced by LLM-generated tests. Once repaired, the test cases are recompiled and executed, with coverage information being extracted to provide feedback for further refinement. This iterative process continues until the test cases meet the desired quality standards, focusing on achieving higher coverage and accuracy.
The effectiveness of TestART has been demonstrated through extensive experiments conducted on the widely adopted Defects4J benchmark, which includes 8192 focal methods extracted from five Java projects. The results of these experiments show that TestART significantly outperforms existing methods, including EvoSuite and ChatUniTest. Specifically, TestART achieved a pass rate of 78.55% for the generated test cases, approximately 18% higher than the pass rates of both the ChatGPT-4.0 model and the ChatUniTest method based on ChatGPT-3.5. TestART achieved an impressive line coverage rate of 90.96% on the focal methods that passed the test, exceeding EvoSuite by 3.4%. These results underscore TestART’s superior ability to produce high-quality unit test cases by effectively harnessing the power of LLMs while addressing their inherent flaws.

In conclusion, TestART, by addressing the limitations of existing LLM-based methods, achieves higher pass rates and better coverage, making it a valuable tool for software developers seeking to ensure the reliability and quality of their code. The research conducted by the team from Nanjing University and Huawei Cloud Computing Technologies Co., Ltd. demonstrates the potential of combining LLMs with co-evolutionary repair processes to produce more effective and reliable unit tests. With a pass rate of 78.55% and a coverage rate of 90.96%, TestART sets a new standard for automated unit test generation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post TestART: Achieving 78.55% Pass Rate and 90.96% Coverage with a Co-Evolutionary Approach to LLM-Based Unit Test Generation and Repair appeared first on MarkTechPost.
