


The ability to convert natural language questions into structured query language (SQL), known as text-to-SQL, helps non-experts easily interact with databases using natural language. This makes data access and analysis more accessible to everyone. Recent studies have highlighted significant achievements in powerful closed-source large language models (LLMs) like GPT-4, which use advanced prompting techniques. However, adopting closed-source LLMs raises concerns about openness, privacy, and substantial costs. As a result, open-source LLMs gained great attention for offering similar performance to their closed-source counterparts in various natural language processing tasks.
Previous methods like IRNET used attention-based models to learn representations for text-to-SQL parsing, while later methods introduced models based on fine-tuning. Recently, LLMs have become a focus, with various works exploring new prompting techniques. For example, ACT-SQL automatically generates Chain-of-Thought examples, DIN-SQL breaks down complex tasks into sub-tasks, and DAIL-SQL organizes samples all of which have greatly improved performance in the text-to-SQL field. However, most of these methods are dependent on closed-source LLMs. Another work shows recent progress in generating synthetic data, such as Self-Instruct, which introduced a framework for enhancing instruction-following skills, and other works that have created mathematical questions and enhanced samples.
Researchers from the Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences, University of Chinese Academy of Sciences, and Alibaba Group have proposed a synthetic data approach that combines strong data generated by larger, more powerful models with weak data generated by smaller, less accurate models. This method enhances domain generalization in text-to-SQL models and explores the potential of using weak data supervision through preference learning. Moreover, the researchers used this synthetic data method to fine-tune open-source large language models, creating SENSE, a specialized text-to-SQL model. SENSE has proven its effectiveness by achieving top results on the SPIDER and BIRD benchmarks.
The effectiveness of SENSE is tested using popular text-to-SQL benchmarks on five datasets. The general benchmark, Spider contains 7,000 text-SQL pairs in its training set and 1,034 pairs in its development set, covering 200 different databases and 138 domains. The challenge benchmark, BIRD is a new benchmark focused on large real-world databases, having 95 large databases with high-quality text-SQL pairs, with a total data of 33.4GB across 37 fields. Unlike Spider, BIRD emphasizes real and huge database contents, that require knowledge to reason between natural language questions and database content.
The results show that prompting methods perform better than fine-tuning in text-to-SQL tasks, due to the strengths of closed-source LLMs and custom prompts. However, open-source LLMs still pose challenges with generalization. It is found that larger models tend to produce better outcomes, and instruction tuning enhances performance, highlighting the value of using synthetic data. Moreover, the SENSE model created by the researchers sets a new standard for the Spider dataset, outperforming the GPT-4-based DAILSQL. Especially, the SENSE-13B model shows a 21.8% improvement over CodeLLaMA-13B-Instruct on the development set and slightly outperforms DAILSQL.
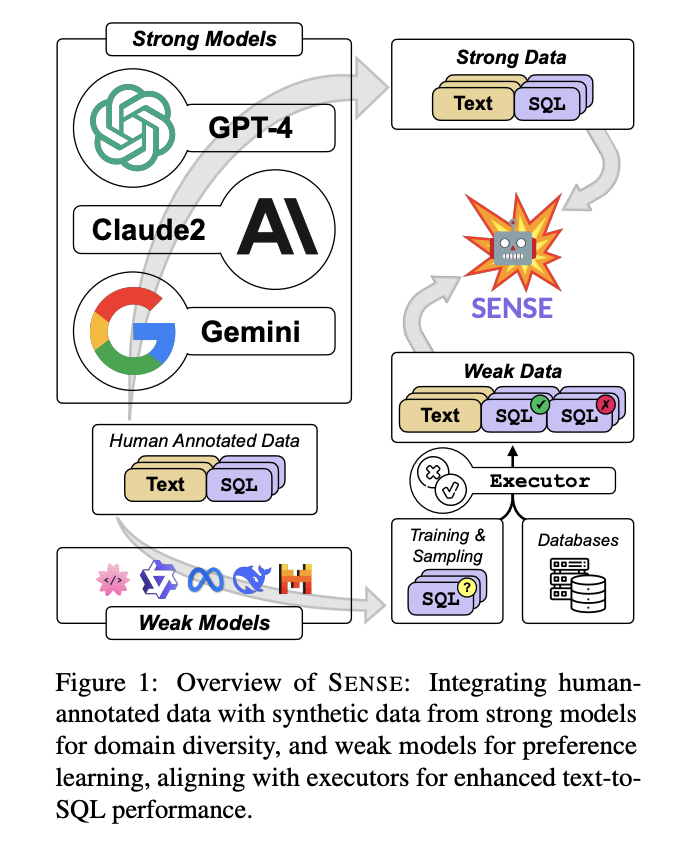
In this paper, researchers introduced SENSE, a new model to explore the use of synthetic data in text-to-SQL parsing. By combining strong synthetic data from larger models with weaker data from smaller models, SENSE improves domain generalization and learns from feedback through preference learning. The experiments show that SENSE achieves top performance on well-known benchmarks, bringing open-source models closer to the performance of closed-source models. However, due to limited computational resources and time, the researchers could not fine-tune their method on LLMs such as LLaMA2-70B, which might further enhance the performance.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post SENSE: Bridging the Gap Between Open-Source and Closed-Source LLMs for Advanced Text-to-SQL Parsing appeared first on MarkTechPost.
