
Published on August 8, 2024 6:22 PM GMT
Eliezer Yudkowsky’s main message to his Twitter fans is:
Aligning human-level or superhuman AI with its creators’ objectives is also called “superalignment”. And a month ago, I proposed a solution to that. One might call it Volition Extrapolated by Language Models (VELM).
Apparently, the idea was novel (not the “extrapolated volition” part):
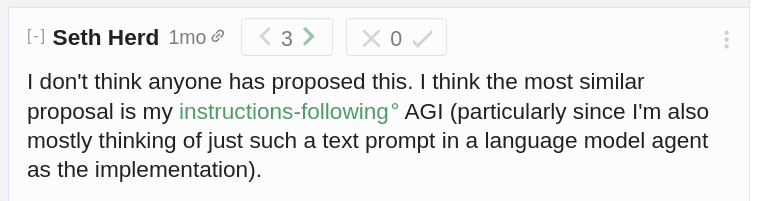
But it suffers from the fact that language models are trained on large bodies of Internet text. And this includes falsehoods. So even in the case of a superior learning algorithm[1], a language model using it on Internet text would be prone to generating falsehoods, mimicking those who generated the training data.
So a week later, I proposed a solution to that problem too. Perhaps one could call it Truthful Language Models (TLM). That idea was apparently novel too. At least no one seems to be able to link prior art.

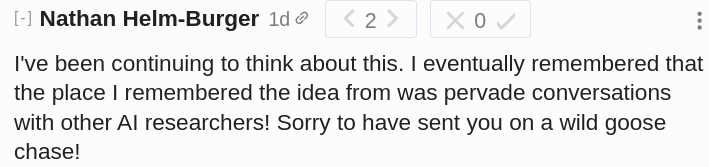
Its combination with the first idea might be called Volition Extrapolated by Truthful Language Models (VETLM). And this is what I was hoping to discuss.
But this community’s response was rather disinterested. When I posted it, it started at +3 points, and it’s still there. Assuming that AGI is inevitable, shouldn’t superalignment solution proposals be almost infinitely important, rationally-speaking?
I can think of five possible critiques:
- It’s not novel. If so, please do post links to prior art.It doesn’t have an “experiments” section. But do experimental results using modern AI transfer to future AGI, possibly using very different algorithms?It’s a hand-waving argument. There is no mathematical proof. But many human concepts are hard to pin down, mathematically. Even if a mathematical proof can be found, your disinterest does not exactly help.Promoting the idea that a solution to superalignment exists doesn’t jibe with the message “stop AGI”. But why do you want to stop it, if it can be aligned? Humanity has other existential risks. They should be weighed against each other.Entertaining the idea that a possible solution to superalignment exists does not help AI safety folks’ job security. Tucker Carlson released an episode recently arguing that "AI safety" is a grift and/or a cult. But I disagree with both. People should try to find the mathematical proofs, if possible, and flaws, if any.
- ^
Think “AIXI running on a hypothetical quantum supercomputer”, if this helps your imagination. But I think that superior ML algorithms will be found for modern hardware.
Discuss
