


Taipy and Streamlit have garnered significant attention among data scientists & machine learning engineers in Python-based web application frameworks. Both platforms offer unique functionalities tailored to different development needs. Let’s compare Taipy’s callback functionalities and Streamlit’s caching mechanisms and how Taipy beats Streamlit in many instances, offering technical insights to help developers choose the right tool for their specific requirements.
Taipy: Advanced Callbacks for Enhanced Interactivity
Taipy, a newer Python web framework ecosystem entrant, offers a robust & flexible environment for building complex data-driven applications. It is an innovative open-source tool designed to streamline the creation, management, and execution of data-driven pipelines with minimal coding effort. It presents a solution for Python developers who find building production-ready web applications challenging due to the complexity of front-end and back-end development. It covers both the frontend and the backend. This dual approach provides a comprehensive and complete solution for developing applications that require both front-end and back-end development, particularly for data-driven tasks.
Callback Mechanisms in Taipy
- Event-Driven Callbacks: Taipy employs a sophisticated callback mechanism that allows developers to create highly interactive applications. Various events, such as user interactions with widgets or changes in data, can trigger callbacks. This event-driven approach ensures that only the relevant parts of the application are updated, enhancing performance and user experience.Scenario Management: Taipy’s unique feature is its scenario management capability, which enables users to conduct what-if analyses and manage different application states effectively. This is handy in applications that require complex decision-making processes or multiple user flows.Design Flexibility: Taipy provides extensive design flexibility, allowing developers to customize the appearance & behavior of their applications beyond the standard templates Streamlit offers. This includes a rich library of UI components & the ability to handle large datasets efficiently through features like pagination and asynchronous execution.Asynchronous Callbacks: Taipy supports asynchronous execution, which is particularly beneficial for handling long-running tasks without blocking the main application thread. This ensures a responsive user interface even when performing complex computations.Data Nodes and Tasks: Taipy’s architecture includes data nodes and tasks that facilitate the creation of complex data pipelines. Data nodes represent the data state at any point in the pipeline, while tasks define operations on these nodes. This modular approach enhances application maintainability and scalability.
Streamlit: Simplifying Caching for Rapid Prototyping
Streamlit has gained popularity for its simplicity and ease of use. It enables developers to convert Python scripts into interactive web applications with minimal effort. One of its key features is its caching system, which optimizes performance by storing the results of expensive computations and preventing redundant executions.
Caching Mechanisms in Streamlit
- st.cache_data: This decorator caches the return value of a function based on the input parameters. It is especially useful for functions that perform data fetching, cleaning, or other repetitive computations. The cached data can be stored in memory or disk, providing flexibility based on the application’s needs.st.cache_resource: Designed for caching resources such as database connections or machine learning models, this decorator ensures that these resources are initialized only once, reducing the overhead of repeatedly re-establishing connections or loading models. This is critical for applications that require persistent and reusable resources across different sessions.Session-Specific Caching: Streamlit supports session-specific caching, ensuring the cached data is unique to each user’s session. This feature is beneficial for applications where users interact with personalized datasets or perform unique operations that should not interfere with one another.Function-Based Caching: Streamlit’s ‘@st.cache’ decorator allows developers to cache function outputs to avoid recomputation. This is particularly useful for data preprocessing and complex computations that do not change often. It helps in speeding up the application by reducing unnecessary recalculations.State Management: Streamlit provides a session state feature that allows developers to persist data across different script runs. This is essential for maintaining user inputs, selections, and other states that must be preserved throughout the session.
Technical Comparison: Taipy vs. Streamlit
- Prototyping and Ease of Use
- Taipy: While Taipy also supports prototyping, it shines in production environments. Its extensive features cater to both early-stage development and the demanding needs of live, user-facing products. This dual capability makes Taipy a versatile tool for long-term projects.Streamlit: Known for its rapid prototyping capabilities, Streamlit’s straightforward API and live reloading features make it ideal for quickly developing and iterating applications.
- Taipy: Although Taipy does not need caching, its strength lies in its advanced callback mechanisms. These callbacks ensure that only the application’s necessary components are updated in response to user interactions, leading to better performance & a more responsive user experience.Streamlit: Streamlit’s caching system is user-friendly and efficient. Caching data and resources minimizes redundant computations and improves overall performance.
- Taipy: Excels in creating highly interactive and customizable user interfaces. Its event-driven callbacks, and scenario management features allow developers to build applications that are not only responsive but also tailored to specific user needs and workflows. Taipy’s design flexibility enables the creation of unique and varied application appearances.Streamlit: It provides a consistent user interface across applications. Its live reloading and rich widget library allows developers to create interactive dashboards with minimal code. However, this can be a limitation for developers seeking more customized and interactive designs.
- Taipy: Designed with scalability in mind, Taipy supports large data handling through features like pagination, chart decimation, and asynchronous execution. Its robust architecture makes it suitable for applications that process and visualize large datasets without compromising performance.Streamlit: While Streamlit handles data well, it does not inherently support large-scale data management or complex data workflows. This can be a limitation for some applications that require extensive data processing or need to handle large datasets efficiently.
- Taipy: Offers comprehensive backend support, including pre-built components for data pipelines and scenario management. Taipy’s architecture includes data nodes and tasks that facilitate the creation of complex data pipelines. This integrated approach simplifies the development of full-stack applications.Streamlit: Primarily focused on the front end, Streamlit does not provide extensive backend support or data pipeline management. Developers often need to integrate Streamlit with other tools to handle backend processes.
- Taipy: Supports asynchronous execution, which is particularly beneficial for handling long-running tasks without blocking the main application thread. This ensures a responsive user interface even when performing complex computations.Streamlit: Streamlit supports asynchronous execution to some extent, but its primary focus is on synchronous operations. This can limit applications requiring real-time data processing or long-running tasks.
Comparative Table: Taipy’s Callbacks and Streamlit’s Caching
Difference in UML infrastructure between Taipy and Streamlit
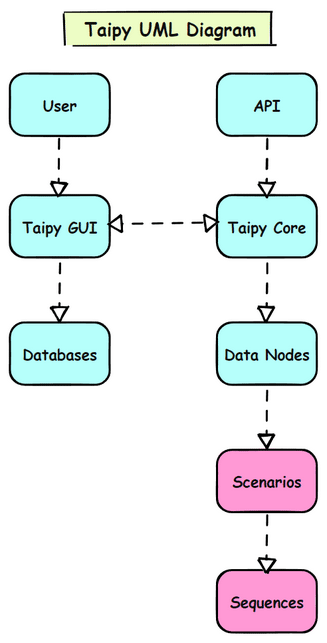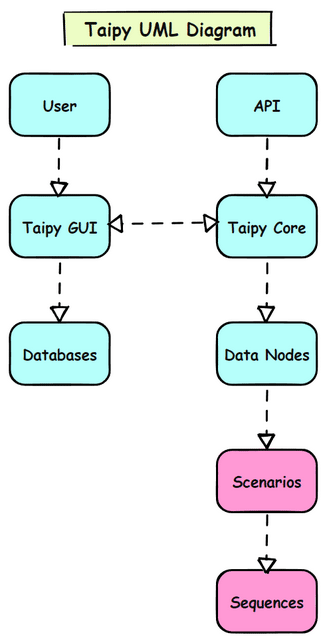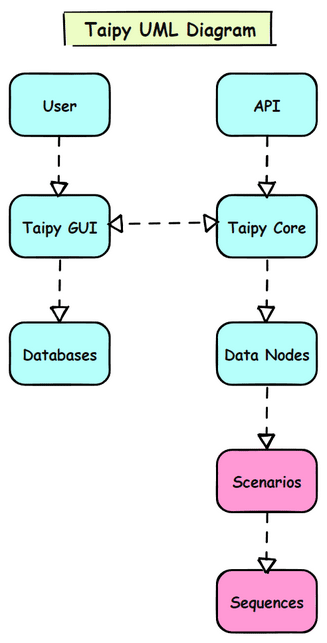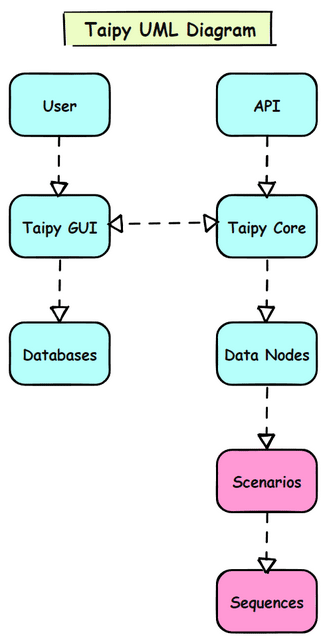
Taipy Infrastructure
Taipy is an advanced enterprise application development framework that handles complex workflows and data dependencies. Its infrastructure includes:
- Core Components:
- Taipy GUI: The user interface component.Taipy Core: Manages workflows, data nodes, and scenarios.Data Nodes: Represent data storage or data sources.Scenarios: Define sets of actions to achieve specific goals.Tasks: Units of work to be executed, usually data processing steps.Sequences: Sequences of tasks forming complete workflows.
- External Interactions:
- Databases: For storing and retrieving data.APIs: These are used to integrate with external services or data sources.User Interface (UI): Interacts with end-users.
Taipy UML Diagram
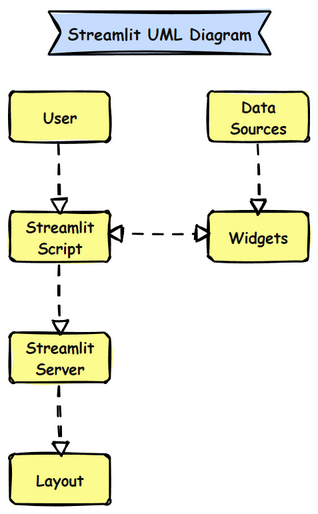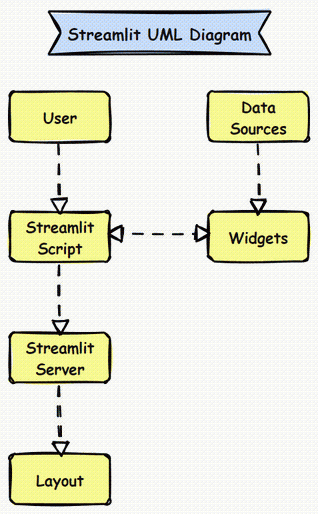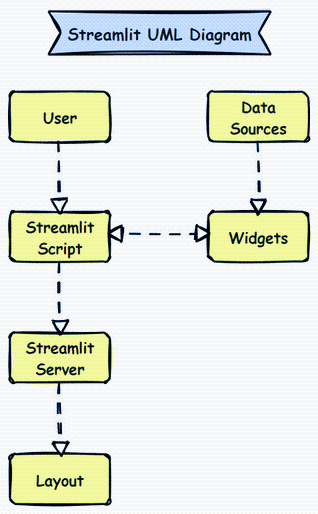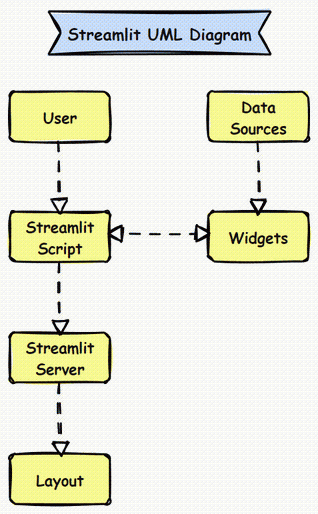
Streamlit Infrastructure
Streamlit is a lightweight framework designed to create data applications quickly. Its infrastructure consists of:
- Core Components:
- Streamlit Script: The Python script that defines the app.Widgets: User interface elements like sliders, buttons, and text inputs.Data: Direct interaction with data sources within the script.Layout: Arrangement of widgets and visualizations on the app page.Streamlit Server: Manages the app’s serving to users.
- External Interactions:
- Data Sources: Directly accessed within the script (e.g., files, databases, APIs).UI: Interacts with end-users via the web app.
Streamlit UML Diagram
Why are Taipy infrastructure and UML better compared to Streamlit?
The Taipy infrastructure, as illustrated in the UML diagram, offers a comprehensive and robust framework well-suited for enterprise-level applications. Its infrastructure is designed to handle complex workflows and data dependencies with advanced features such as automation, asynchronous execution, and tight integration of core components like data nodes, pipelines, scenarios, and tasks. This structured approach ensures that all aspects of the workflow are well-coordinated, reliable, and maintainable, providing a significant edge over simpler frameworks. By supporting sophisticated data pipelines and automatic task triggering, Taipy enhances efficiency and reduces manual intervention, making it ideal for large-scale data processing and real-time analytics. This level of sophistication and integration makes Taipy a superior choice for building highly efficient, scalable, and adaptive enterprise applications compared to straightforward solutions like Streamlit.
Why are Taipy Callbacks a Better Solution?
- Advanced Features and Flexibility
- Complex Workflows: Handle sophisticated data pipelines that trigger tasks and scenarios based on data changes or events.Automation: Reduce manual intervention and enhance efficiency by automating workflow processes.Asynchronous Execution: Support parallel processing for faster response times, crucial for large-scale data processing and real-time analytics.
- Tightly Coupled Workflows: Ensure the workflow is well-coordinated, leading to reliable and maintainable applications.Complex Dependencies Management: Manage and execute tasks in a well-defined sequence, ideal for enterprise applications requiring high reliability and scalability.Adaptive Applications: Build responsive applications that adapt easily to changing business requirements and data environments. It provides a significant edge over simpler frameworks like Streamlit.
Use Cases Where Taipy Callbacks are Better Compared to Streamlit Caching
Taipy callbacks excel in use cases where complex data workflows and dependencies are prevalent. For instance, in financial analytics, where real-time data processing and complex computational models are essential, Taipy’s ability to automate task execution based on data changes ensures timely and accurate results. Similarly, managing patient data, diagnostics, and treatment plans in healthcare applications requires robust workflow management that Taipy’s callbacks can handle seamlessly. In contrast, Streamlit’s caching is more suitable for simpler scenarios where the primary goal is to improve app performance by storing frequently accessed data. Streamlit needs caching to speed up repetitive tasks, whereas the advanced automation and dependency management that Taipy offers makes it independent of caching requirements. Taipy is designed to empower developers to build sophisticated Python data and AI web applications effortlessly. Its advanced infrastructure supports large data sets, ensuring smooth and efficient data processing and visualization.
Conclusion
In conclusion, Taipy offers a more comprehensive solution for developers building complex, scalable applications. Its advanced callback mechanisms, design flexibility, and robust support for large datasets make it a powerful tool for production environments. Whether for prototyping or full-scale deployment, Taipy’s features provide a seamless pathway from development to execution.
Thanks to Taipy for the thought leadership/ Resources for this article. Taipy has supported us in this content/article.
The post Comparing Taipy’s Callbacks and Streamlit’s Caching: A Detailed Technical Analysis appeared first on MarkTechPost.
