


LLMs excel in natural language understanding but are resource-intensive, limiting their accessibility. Smaller models like MiniCPM offer better scalability but often need targeted optimization to perform. Text embeddings, vector representations that capture semantic information, are essential for tasks like document classification and information retrieval. While LLMs such as GPT-4, LLaMA, and Mistral achieve strong performance due to extensive training, smaller models like Gemma, Phi, and MiniCPM require specific optimizations to close the performance gap and remain efficient.
Tsinghua University’s researchers investigated ways to enhance smaller language models by improving their text embeddings. They focused on three models—MiniCPM, Phi-2, and Gemma—and applied contrastive fine-tuning using the NLI dataset. The findings revealed that this method significantly improved text embedding quality across various benchmarks, with MiniCPM showing a notable 56.33% performance gain. This research addresses the lack of focus on smaller models. It aims to make MiniCPM more effective for resource-limited applications, demonstrating its potential alongside other models like Gemma and Phi-2 after fine-tuning.
Text embeddings are low-dimensional vector representations of text that capture semantic meaning, supporting tasks like information retrieval, classification, and similarity matching. Traditional models like SBERT and Sentence T5 aim to provide versatile text encoding, while more recent methods such as Contriever and E5 enhance embeddings through multi-stage training strategies. Contrastive representation learning, involving techniques like triplet loss and InfoNCE, focuses on learning effective representations by contrasting similar and dissimilar data points. Lightweight language models like Phi, Gemma, and MiniCPM address the resource demands of large-scale models by offering more efficient alternatives. Fine-tuning methods like Adapter modules and LoRA enable task-specific adaptation of pre-trained models with reduced computational costs.
The methodology addresses Semantic Textual Similarity (STS) in English by leveraging smaller language models to create an efficient and scalable solution. The approach uses contrastive fine-tuning to enhance text embeddings, training the model to differentiate between similar and dissimilar text pairs, thus producing more accurate and contextually relevant embeddings. Low-rank adaptation (LoRA) is employed during fine-tuning to maintain computational efficiency. The study uses a processed NLI dataset with 275k samples, and experiments are conducted on smaller models, including Gemma, Phi-2, and MiniCPM. The fine-tuning process uses the InfoNCE objective with in-batch and hard negatives to improve embedding quality.
Experiments focus on measuring the similarity score of embeddings for sentence pairs using cosine similarity and Spearman correlations. MiniCPM, Gemma, and Phi-2 are evaluated across nine benchmarks, including STS12-17, STSBenchmark, BIOSSES, and SICK-R. Results show that MiniCPM consistently outperforms the other models, achieving the highest Spearman correlations across all datasets. Fine-tuning with LoRA significantly enhances performance, with MiniCPM showing a 56-point improvement. Ablation studies reveal the impact of learning rate, prompting, and hard negatives on performance, indicating that MiniCPM benefits greatly from contrastive fine-tuning and hard negative penalization.
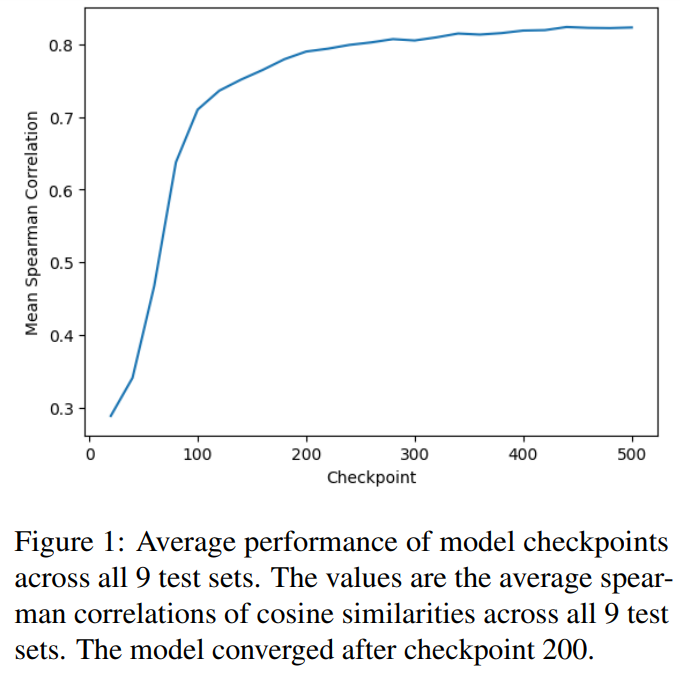
The study successfully enhanced MiniCPM’s text embedding capabilities using contrastive fine-tuning on the NLI dataset. The fine-tuning led to a notable 56.33% performance improvement, allowing MiniCPM to outperform other models like Gemma and Phi-2 across nine STS benchmarks. Multiple ablation studies were conducted to explore the impact of prompt tuning, training efficiency, and the incorporation of hard negative penalties. The research improves the robustness and reliability of text embeddings in smaller-scale language models, offering a scalable and resource-efficient alternative to larger models while maintaining high performance in natural language understanding tasks.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post Enhancing Text Embeddings in Small Language Models: A Contrastive Fine-Tuning Approach with MiniCPM appeared first on MarkTechPost.
