
图文并茂的PDF长文档在日常生活中无处不在。过去人们通常使用OCR,layout detection等方法对PDF长文档进行解析。但随着多模态大模型的发展,PDF长文档的端到端阅读理解成为了可能。
为了评测多模态大模型在PDF长文档上的阅读理解能力,由上海AI Lab领衔提出的MMLongBench-Doc评估基准测试了14个LVLMs(视觉语言大模型)。
评估结果表明:表现最好的GPT-4o在整体F1分数上也只达到了 44.9%。
GPT-4V排名第二,得分30.5%。
除了这两个模型,其他被评测LVLMs的表现更是要弱于OCR+LLMs形式。
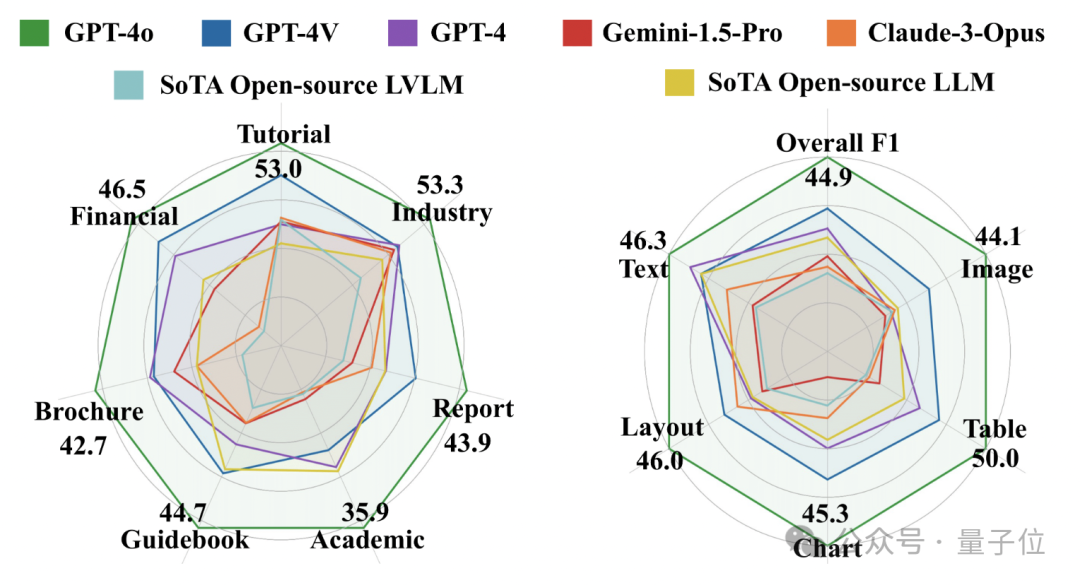
这些结果表明,目前的LVLMs在端到端PDF长文档阅读任务上虽然表现出了一定的潜力,但仍然还有很大的提升空间。
135个PDF、1091个问题
LVLMs的出现有效促进了文档理解任务的解决。针对单页文档,常见的闭源和开源模型都展示出了相当不错的表现(DocVQA > 90%;ChartQA > 80%)。然而,日常生活中阅读的文档,如论文、财报、宣传资料,往往有更多的页数,许多文档长度可以达到数十页甚至上百页。面对长文档,无论是单页信息的查询还是跨页信息的理解都极具挑战性,因此对LVLMs的能力提出了更高的要求。
因此研究团队提出了《MMLONGBENCH-DOC: Benchmarking Long-context Document Understanding with Visualizations》,以进一步评估LVLMs在超长文档解析方面的能力。

MMLongBench-Doc的数据统计量、文档格式和问题类型示例如图1所示。
与之前的文档理解数据集相比,MMLongBench-Doc在文档侧和问题侧都具有显著优势:
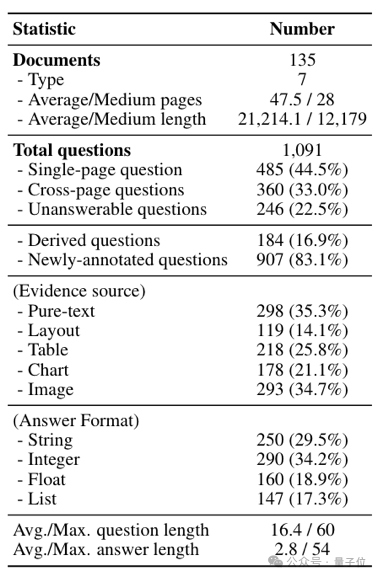
△MMLongBench-Doc的数据统计量
文档侧:研究团队手动选取了135篇PDF格式的文档,涵盖学术论文、财务报告、教程、宣传手册等7个不同领域。绝大多数文档都具有复杂的版式结构,并且包含多种模态(文字、表格、图片等)的内容。文档的平均长度为47.5页,文本信息超过两万个单词,篇幅和信息量远远超过其他数据集中的文档。
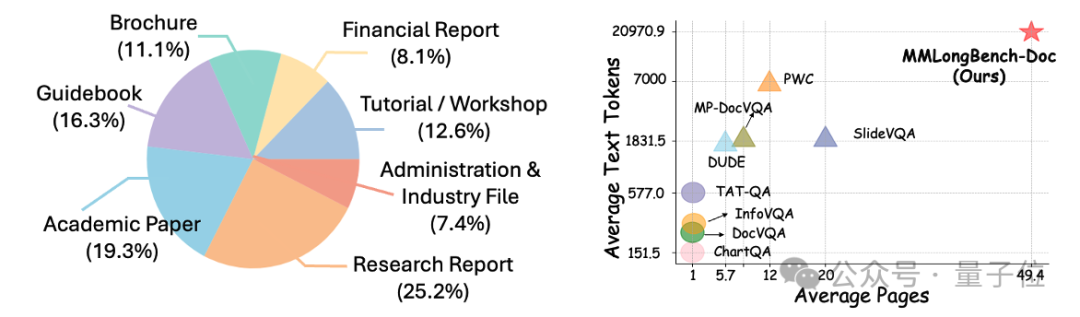
△文档的分布(左)。文档的页数与字符数统计(右;包含和之前数据集的比较)
问题侧:由10名phd-level的标注者人工标注了1091个问题:
这些问题可以分为三类:single-page、cross-page和unanswerable。
Single-page question:44.5%的问题是针对某一页内容设计的,重点考察大模型从长文本中查找信息的能力(类似于大海捞针);
Cross-page question: 33%的问题需要综合两页甚至更多页内容的信息来回答,重点考察大模型面对多跳问题的综合推理能力;
Unanswerable question: 为了防止模型利用文档中的捷径回答问题,22.5%的问题被设计为没有答案,即无法根据文档中提供的信息进行回答。
这些问题均匀分布在文档的不同位置(page index)和不同模态(分为text, layout, table, chart, image五种)的内容中。
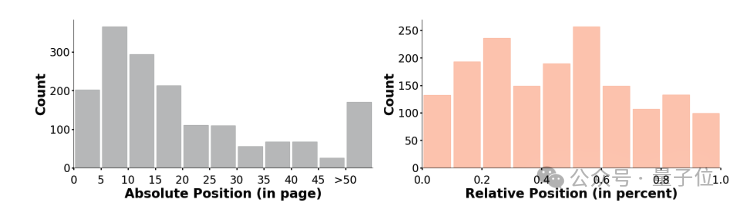
△问题均匀分布在文章的不同位置
其他被评测LVLMs整体表现弱于OCR+LLMs
研究评测了14个LVLMs(4个闭源模型,10个开源模型)在MMLongBench-Doc上的表现。
通过给定一篇文档和一个基于该文档的问题,研究人员将PDF格式的文档转化成多张PNG格式的页面截图,并将这些截图输入给LVLMs。作为比较,还使用OCR工具将PDF文档转化为TXT文本,并使用这些TXT文本评测了10个LLMs的表现。评测的具体结果如下所示。
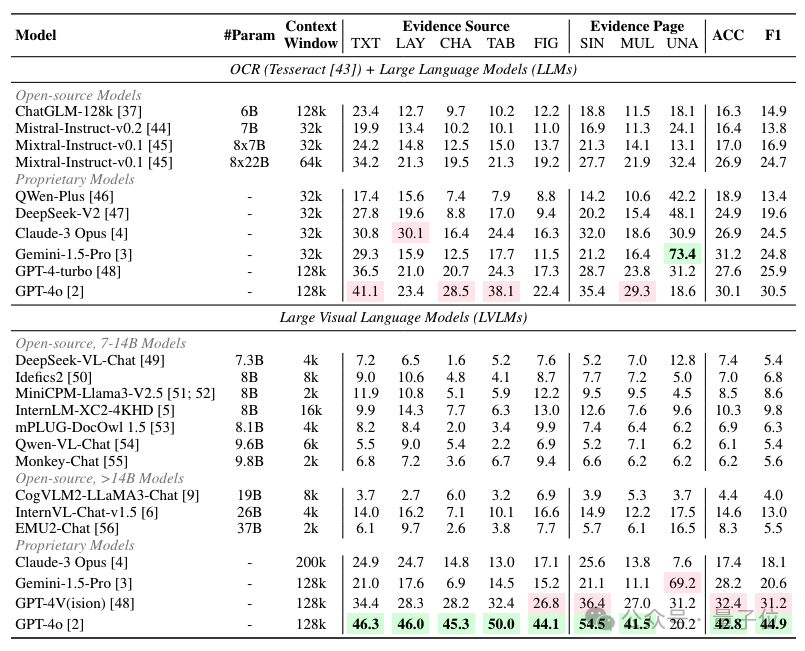
△LVLMs与LLMs在MMLongBench-Doc上的实验结果
研究团队发现:
GPT-4o在所有LVLMs中表现最佳,F1分数达到了约45%;排名第二的GPT-4V的F1分数则为约31%。其余LVLMs的表现则在20%左右甚至更低。这说明,目前的LVLMs尚不足以胜任端到端的长文档阅读理解。
通过对比LVLMs和OCR+LLMs的表现。尽管OCR解析会对PDF文本带来损耗(尤其是对图表类信息),除了GPT-4o和GPT-4V这两个模型外,其他被评测的LVLMs整体表现弱于OCR+LLMs。这进一步说明目前的LVLMs在长文档阅读理解上还有很大的潜力。
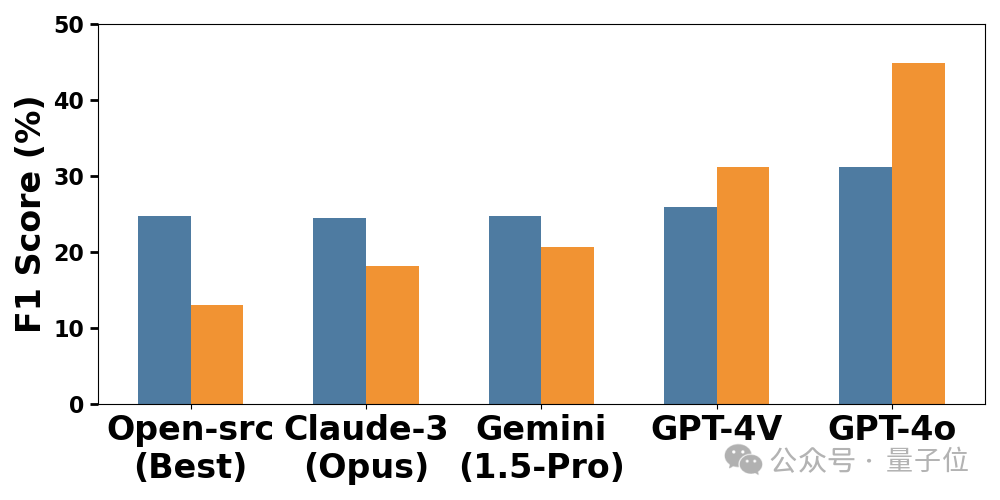
△LVLMs与LLMs的实验结果对比
对于能力更强的LVLM模型,比如GPT-4o,其直接读取PDF图片的表现则优于其读取OCR版本的文档,这说明了多模态大语言模型在端到端的长文档阅读理解任务上具有更高的上限。
此外,研究团队还对六个不同模型进行了定性分析。
如下图所示,这个问题来自于一个40页长的文档,需要综合第9,10页中的两个表格和第16页中的一个图表进行多步推理才能够回答。
可以看到除了GPT-4o回答正确外,GPT-4V也给出了正确的分析思路(但因为在抽取第10页的信息时出错导致最终的答案不正确),而其他模型的回答则明显存在很大的问题。
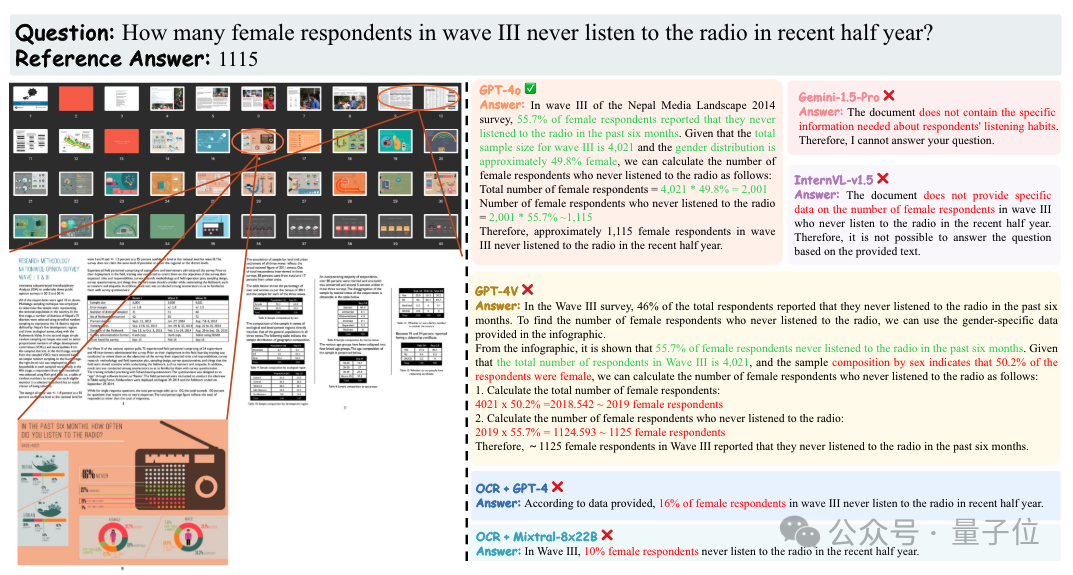
△案例分析
更多定量和定性的分析讨论可阅读论文原文。
论文地址:https://arxiv.org/pdf/2407.01523
项目页:https://mayubo2333.github.io/MMLongBench-Doc/
数据集:https://huggingface.co/datasets/yubo2333/MMLongBench-Doc
GitHub:https://github.com/mayubo2333/MMLongBench-Doc
投稿请发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

点这里?关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见 ~

