
来源:雪球App,作者: 闷得而蜜,(https://xueqiu.com/5672579962/299860241)
一、Scaling-Law 与Moore-Law剪刀差v2.0
我在今年3月份提出AI算力基建投资策略的底层逻辑,是Scaling-Law与Moore-Law的剪刀差(网页链接)后,引起了热烈的反响,在AI算力基建板块,比如中际旭创、工业富联、沪电股份的频道中,广为流传。
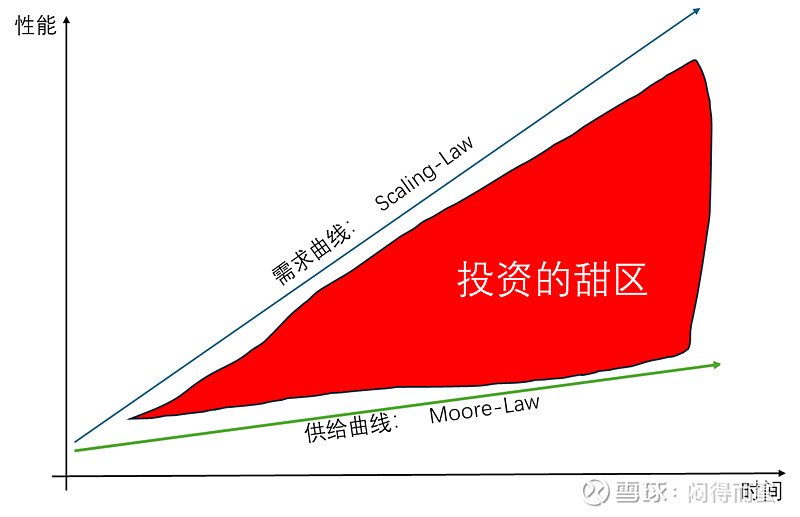
时过境迁,到了8月份,有了进一步思考,推出v2.0版本。
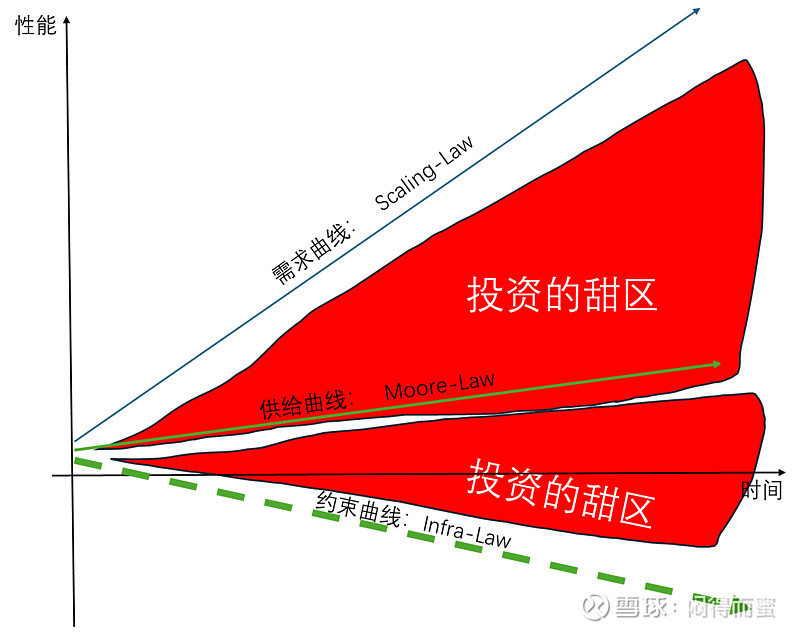
增加了约束曲线。大家都知道AI算力基建Capex中,有50%投向Infrastructure(地产、电力、散热、布线、安防…),另外50%投向AI服务器及配套产品。
从投资比例就可以看出,超过一半的资金在基建。需求曲线、供给曲线持续向上翘,而基建呢,反其道,比如,电力供应,每增加一倍总量的电力需求,所需要的投资可能是数倍。功率密度每增加一倍,capex投资可能是指数级增长。所以,Infra-Law是一个隐形的约束曲线,很大程度上,决定了AI算力基建的架构选择。
二、约束曲线将是未来AI算力的核心要素
剪刀差的结果就是摊大饼。这个饼怎么摊很有讲究,归根结底,有约束曲线决定。
B100的NVL36,每Rack的功耗达到130kw,NVL72的每rack功耗达到250kw。据统计,全世界只有6%的数据中心满足这个条件。按照Nv的战略规划,每18个月一个大的代际(性能翻倍),而半导体工艺从5nm演进到3nm、3nm演进到2nm,功耗贡献只有15%。也就是说,为了实现性能翻倍的代价目标,每隔18个月,数据中心的供电功率密度必须接近翻倍。
以前10年一代的DC供电升级需求,被压速到18个月一次!
Moore-Law的增益越来越低,约束曲线越来于强,怎么办?
Nv在B100这一代抛弃光纤转向铜缆,就是基于性价比的最优解。但是,我们也应该看到铜缆因为2米的距离限制,就导致了超高功率密度(250kw/rack),导致大量的Infra投资,从光模块上剩下的钱,用来拉电线、液冷散热成本还不够。这种出道即巅峰的架构,注定了没有持续演进的空间。
另外,2023、2024、2025这三年,大量的先导型客户累计投资超过5000亿的AI算力基建,到2026、2027,就进入更新换代的周期。在H100、B100这两代,Nvidia可以一张白纸只考虑GreenField问题,而到了R100这一代,BrownField将成为首要的场景。怎么办?难道要那些真正的大客户(前三年花大价钱的公司,都是AI的骨灰级玩家)推翻重新来一遍?
所以,那些基于现在的架构线性外推的预言,将来被打脸的概率很大。
三、TSMC出选择题,Nvidia答题
整个AI世界,大体上是一个金字塔结构。
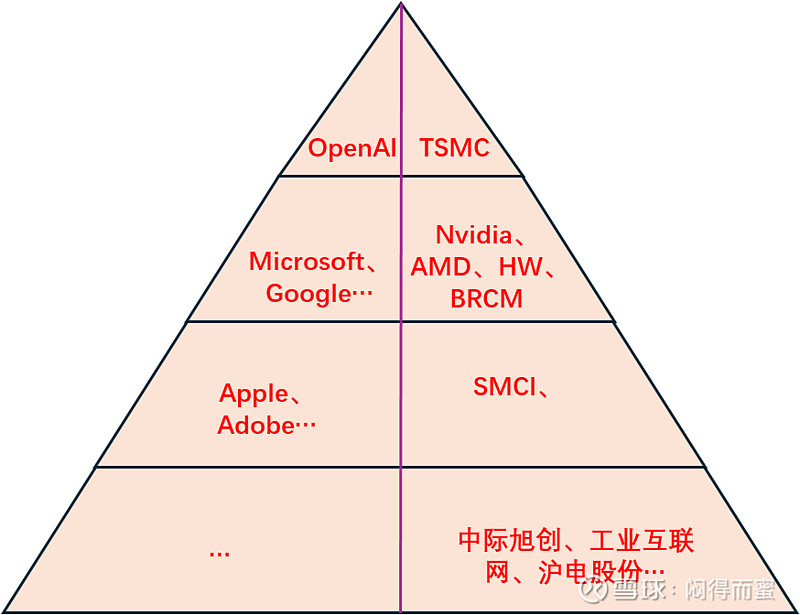
OpenAI负责持续拔高Scaling-Law天花板。
TSMC负责持续推高Moore-Law天花板。
Scaling-Law与Moore-Law的剪刀差持续扩大,同时约束曲线的牵制力持续增强,那么AI算力的未来之路到底在哪里呢?
大家都知道,Nvidia在H100的代际,主推8GPU的算力卡,曾经也试图推广过H100 NVL256,但是因为性价比很差,没有实际商用。在B100这一代,推出了铜缆互联的NVL72。
表面上看,Nvidia是这个世界上AI算力架构的主宰者,他的选择决定了产业的走向。但是,真正的决定者是TSMC,如果他没有新工艺、没有3D封装、没有更大尺寸的封装,这一切都是纸上谈兵。
真实情况是:TSMC负责出选择题,Nvidia负责答题。
这个世界上有几个选项,TSMC说了算。最优解是什么,Nvidia来答题。
TSMC的每一个技术路线,以10年 + 1000亿美金起步。所以,围绕TSMC的产业链,具有较长的周期,持续性会更好。
而Nvidia的技术路线呢,则像小女孩的脸,容易变。Nvidia的下游配套产业链,具有较为鲜明的周期性特征。去年到现在,短短一年多时间,每一次Nvidia的重大活动,都会催生一波主题投资机会。看上去挺热闹,其实,鲜明的快周期特征藏不住。
认识清楚这些本质问题,对于我们判断手上的股票,到底是个香饽饽,还是一个烫手的山芋,至关重要。
四、A股算力基建思考v2.0
我现在深刻认识到,映射Nvidia而诞生的A股算力硬件链,有明显的周期性,必须跳出这个禁锢。
Nvidia的每一代新架构产品,注定了A股几家欢乐几家愁。作为下游的配套厂家,你没得选择权,只有服从,运气好轮到你就发财,运气背就该你倒霉。下一代产品,都有一个潜在的估值“Reset”的风险,如果Nvidia改变方案,一夜之间(比如GTC大会)归零的可能。当然,也有一夜之间暴富(如铜缆)的可能。
相对来说,TSMC的产业链建立在物理学、工程技术的底层根基上,稳定很多。比如3D封装就是典型代表。
所以,AI算力要持续摊大饼,再往下,面临哪些困境和可能的解决之道,我们更应该从TSMC的技术选择和战略规划去洞察,去寻找潜在的投资机会。
那么TSMC的战略方向在哪里呢?
1、践行Moore-Law,持续引领工艺升级;
2、在工艺红利逐渐消褪的时候,率先开辟2.5D、3D封装路线,延续封装的Moore-Law。
3、3D封装的红利也即将见顶,接下来通过什么继续引领全球IT硬件呢? 在去年和今年的几次投资者交流会这种正式的会议上,TSMC的总经理已经旗帜鲜明指出。嗅觉敏锐的投资者应该早就成竹在胸。
总结
1、A股目前那些英伟达映射AI算力标的,都有一种说不清道不明的快周期隐痛,根因我已经解释清楚了。
2、未来A股的AI算力基建底层逻辑,要从Nvidia映射,逐步转变为TSMC映射,寻求更长周期的稳定性。
