

大模型周报将从【技术前瞻】【企业动态】【政策法规】【专家观点】四部分,带你快速跟进大模型行业热门动态。
01 技术前瞻
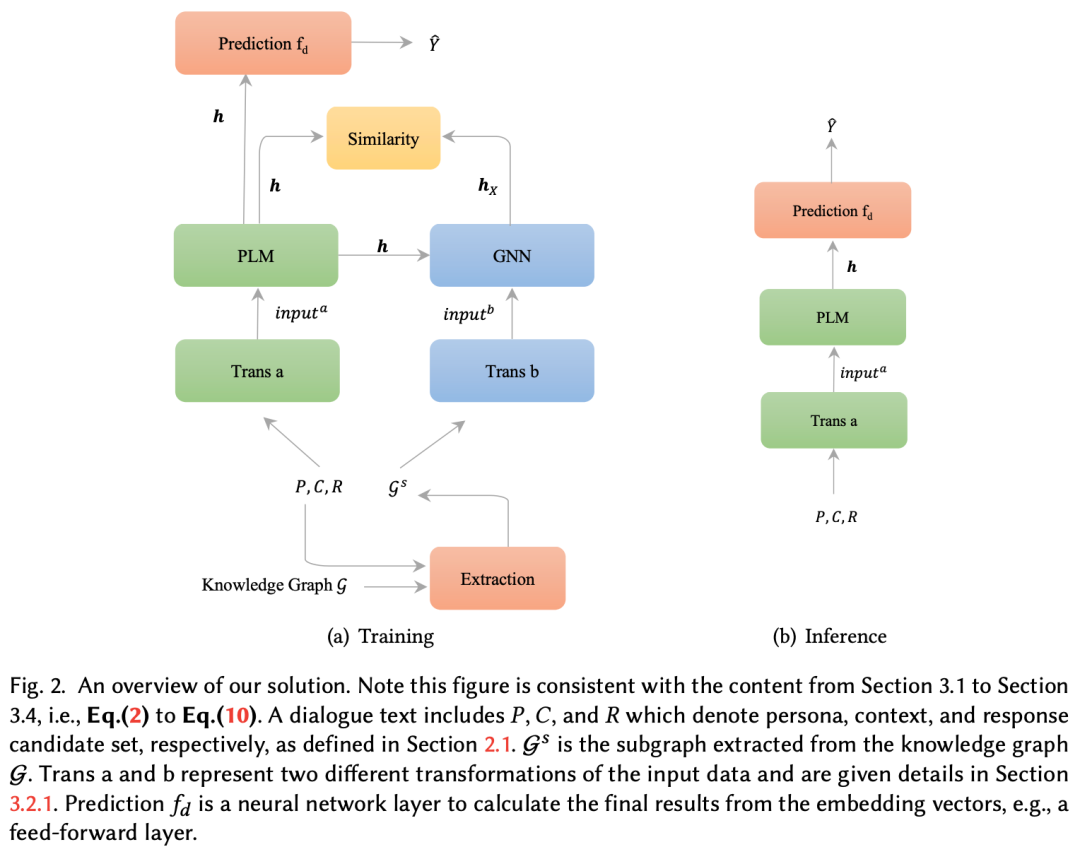
清华团队提出 SinLG:PLMs+GNN,优化多轮响应选择
多轮响应选择是对话系统中的一个普遍研究问题,但以往的研究忽视了外部常识知识的重要性。来自清华大学、格里菲斯大学和昆士兰大学的研究团队,结合预训练语言模型(PLMs)与图神经网络(GNN)设计了一种连体网络 SinLG,其利用 PLMs 捕捉上下文和候选响应中的关联词,并利用 GNN 从外部知识图谱中推理出有用的常识。在两个 PERSONA-CHAT 数据集变体上进行的大量实验证明,这一解决方案不仅能提高 PLM 的性能,还能实现高效推理。
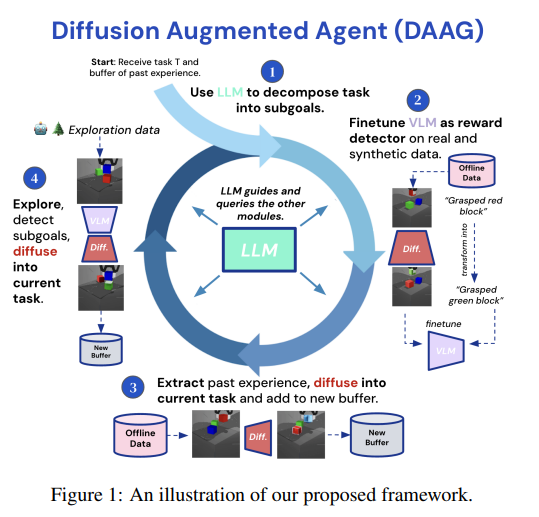
Google DeepMind 提出扩散增强智能体 DAAG
Google DeepMind 团队提出了扩散增强智能体(DAAG),其利用大语言模型(LLM)、视觉语言模型(VLM)和扩散模型来提高样本效率,并在强化学习中为具身智能体提供迁移学习。研究表明,DAAG 提高了奖励检测器的学习能力、过去经验的迁移能力和新任务的获取能力——这些都是开发高效终身学习型机器人的关键能力。
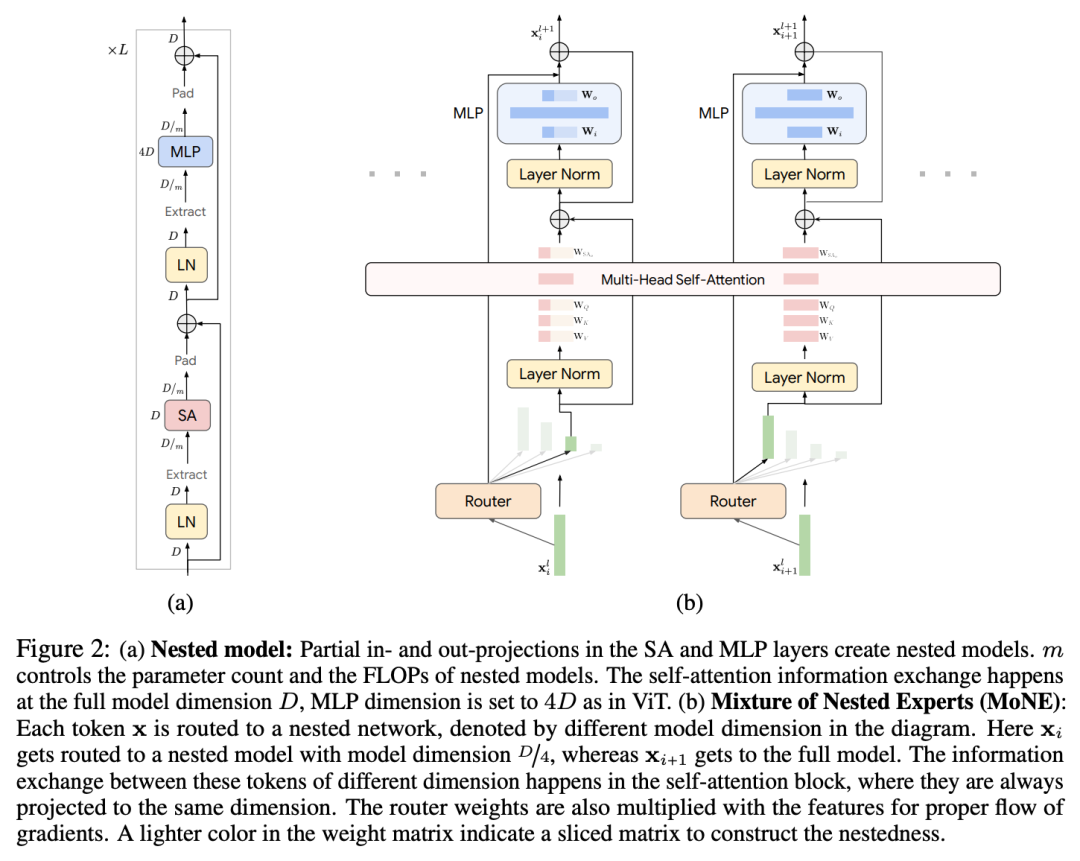
Google DeepMind 提出混合嵌套专家 MoNE
在这项工作中,Google DeepMind 团队提出了混合嵌套专家(MoNE),其采用嵌套式专家结构。在计算预算允许的情况下,MoNE 可以按照优先顺序动态选择 token,因此多余的 token 会通过更便宜的嵌套专家来处理。利用这一框架,他们实现了与基线模型相当的性能,同时将推理时间计算量减少了两倍多。
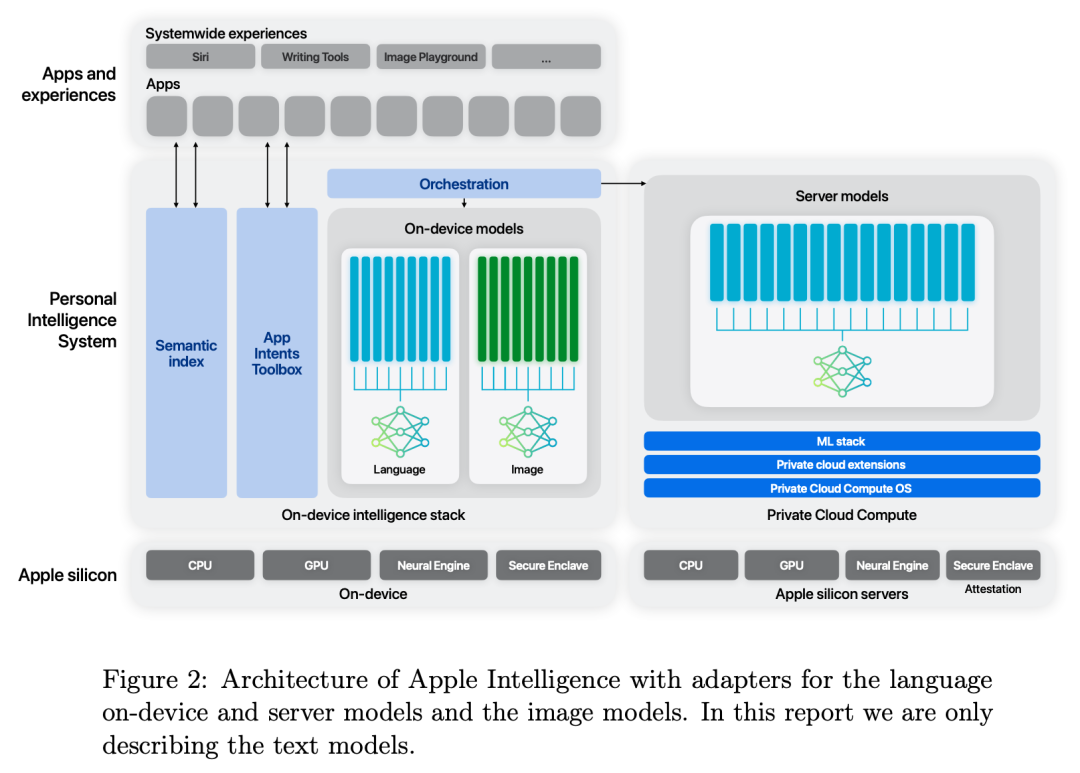
苹果发布 Apple Intelligence 技术报告
在技术报告中,苹果团队介绍了为支持 Apple Intelligence 功能而开发的基础语言模型,包括一个专为在端侧高效运行而设计的约 30 亿参数模型,以及一个专为私有云计算而设计的基于服务器的大语言模型(LLM)。这些模型旨在高效、准确、负责任地执行各种任务。该技术报告还介绍了模型架构、用于训练模型的数据、训练过程、如何优化模型推理以及评估结果。(点击查看详情)
苹果团队提出大规模多任务智能体理解新基准
在这项工作中,苹果团队提出了大规模多任务智能体理解(MMAU)基准,其具有全面的离线任务,无需复杂的环境设置。该基准评估了五个领域的模型,包括工具使用、有向无环图(DAG)QA、数据科学和机器学习编码、竞赛级编程和数学,并涵盖了五种基本能力:理解、推理、规划、解决问题和自我纠正。MMAU 不仅揭示了 LLM 智能体的能力和局限性,还增强了其性能的可解释性。

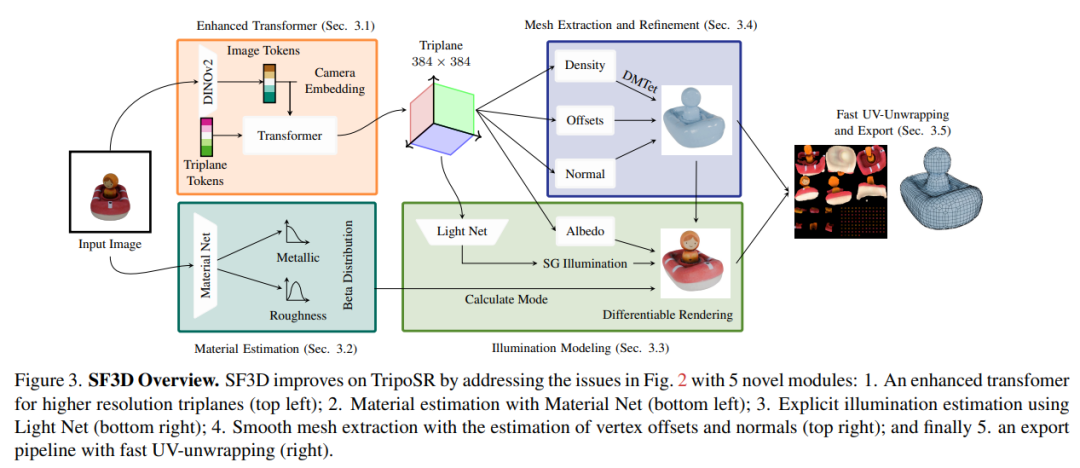
Stability AI 提出稳定、快速的 3D 网格重建方法 SF3D
在这项工作中,Stability AI 团队提出了 SF3D,其可以在 0.5 秒内从单张图像快速、高质量地重建纹理物体网格。与大多数现有方法不同,SF3D 经过明确的网格生成训练,采用了快速 UV 解包技术,能够快速生成纹理,而不是依赖顶点颜色。这一方法还能学习预测材料参数和法线贴图,从而提高重建 3D 网格的视觉质量。此外,SF3D 还集成了一个消除低频光照效应的步骤,确保重建的网格能在新的光照条件下轻松使用。实验证明,SF3D 的性能优于现有技术。
MIT 提出 LLM 校准方法 Thermometer
来自麻省理工学院(MIT)和 MIT-IBM Watson AI Lab 的研究团队提出了一种大语言模型(LLM)校准方法——Thermometer,其原理是在 LLM 之上构建一个较小的辅助模型来对其进行校准。据悉,这一方法所需的计算能力更少,但同时又能保持模型的准确性,并使其能够在未曾遇到过的任务中做出更好的校准响应。
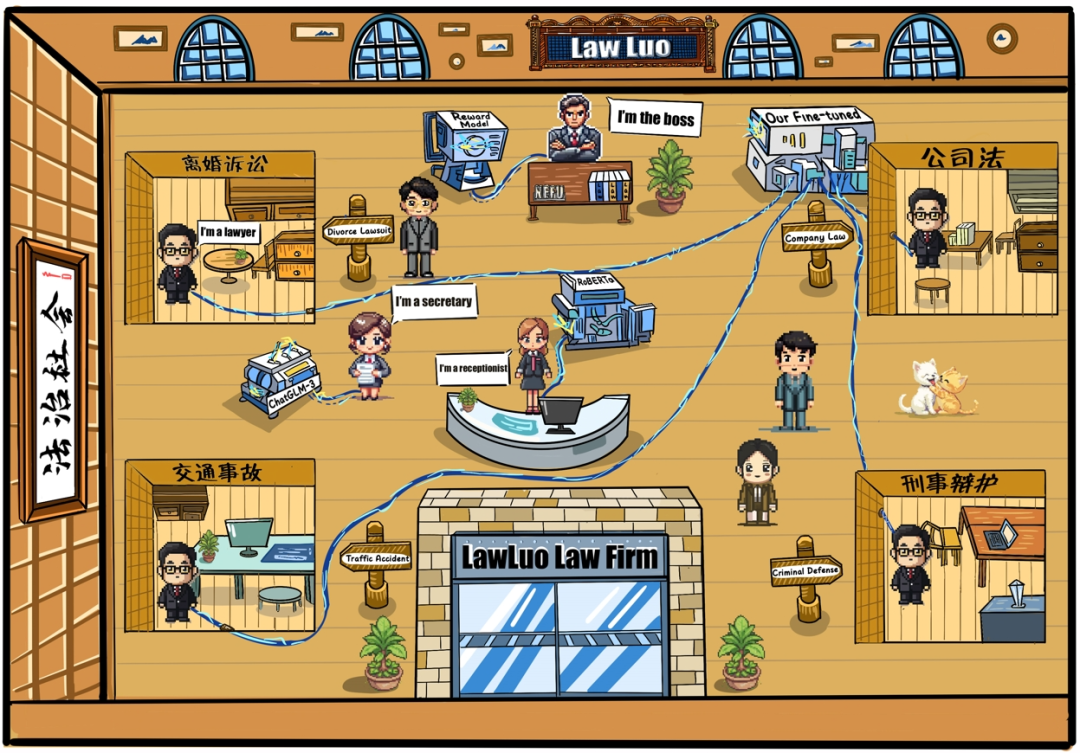
AI智能体,开了一家律师事务所
来自东北林业大学、马来西亚拉曼大学和石家庄铁道大学的研究团队,通过使用高质量法律问答数据集 KINLED 和多轮法律咨询数据集 MURLED 微调 ChatGLM-3-6b,提出了一个基于 LLM 多智能体协作的法律问答框架——LawLuo。在这一框架内,接待员、律师、秘书以及老板四个智能体共同完成一次用户的法律咨询。实验结果表明,LawLuo 在类似律师的语言、法律建议的有用性和法律知识的准确性三个维度上的表现优于包括 GPT-4 在内的基线 LLM。
点击“阅读原文”,获取更多大模型论文
02 企业动态
扎克伯格:Llama 4 可能需要比 Llama 3.1 多 10 倍的计算能力
日前,Meta 联合创始人兼 CEO 马克·扎克伯格在第二季度财报电话会议上透露,训练 Llama 4 所需的计算能力将是 Llama 3 的近 10 倍。这意味着,未来的 AI 模型需要更加庞大的计算资源。扎克伯格提到,考虑到新推理项目启动时间较长,他倾向于提前建设计算能力,避免临时抱佛脚。
Black Forest Labs 发布文生图模型 FLUX.1
由 Stable Diffusion 论文共同一作 Robin Rombach 创办的初创公司 Black Forest Labs 发布了文生图模型 FLUX.1,其超过了 Midjourney v6.0、DALL·E 3 (HD) 等主流模型,确立了新标准。目前,Black Forest Labs 已获得 3100 万美元的种子资金,该公司旨在开发用于图像和视频的生成深度学习模型,同时优先考虑广泛的可访问性和透明度。
微软将 OpenAI 列入 AI 及搜索竞争对手名单
日前,微软在提交给美国证券交易委员会(SEC)10-K 表格中,将 OpenAI 列为竞争对手。名单中还包括亚马逊、谷歌和Meta等公司。在文件中,微软将 OpenAI 确定为 AI 产品以及搜索和新闻广告的竞争对手。上周,OpenAI发布了一个名为 SearchGPT 的搜索引擎原型。
Google 革新 Chrome 历史搜索功能
Google 宣布了一项旨在提升用户体验的重大更新,即将于未来几周内在美国的桌面版 Chrome 浏览器上推出。此次更新的核心亮点在于,用户将能够以自然语言的形式向浏览器的历史记录提出问题,从而更便捷地找回所需信息。这一功能基于 Google 自家的大语言模型 Gemini,它为 AI 系统提供支持,使得浏览器历史搜索变得如同对话般自然。
OpenAI 向部分用户开放 GPT-4o 语音模式
日前,OpenAI 宣布即日起开始向部分 ChatGPT Plus 用户推出 GPT-4o 的语音模式。据介绍,高级语音模式能提供更自然的实时对话,允许用户随时打断,并能感知和响应用户的情绪。OpenAI 在今年 5 月推出 GPT-4o 时展示了语音模式。语音模式将于今年秋季向所有 ChatGPT Plus 用户开放。
克利夫兰诊所任命首位首席人工智能官
近日,世界著名医疗机构克利夫兰诊所官方表示,Ben Shahshahani 将担任新设立的首席人工智能官一职。根据卫生系统的一份新闻稿,他将监督企业范围内 AI 战略的制定和执行,同时考虑安全和道德问题以及行业法规和数据安全。卫生与公众服务部也在寻找一位永久性的 AI 主管。该机构最近进行了重组,将对技术、数据和 AI 政策和战略的监督置于新更名的技术政策助理部长和国家卫生信息技术协调员办公室之下。
AI 搜索公司 Perplexity 推出出版商收入共享计划
近日,由前 OpenAI 核心团队创立的 AI 搜索引擎 Perplexity AI 宣布了一项重大举措,旨在缓解与出版商之间的版权争议并促进内容创作者的经济激励。在经历了被指内容抄袭的风波后,Perplexity 于 7 月 30 日正式推出出版商收入共享计划,承诺当出版商的内容被其 AI 生成的答案引用时,将分享一定比例的广告收入。此举被视为 Perplexity 对版权问题积极回应的重要一步,旨在重建与出版商之间的信任桥梁。
AI 音乐公司 Suno 和 Udio 回击音乐巨头的大规模诉讼
近日,AI 音乐公司 Suno 和 Udio 对主要唱片公司发起的大规模诉讼进行了回击,称他们可以自由地使用受版权保护的歌曲来训练他们的模型,并声称音乐行业滥用知识产权来压制竞争。这两家公司承认使用了专有材料来创造他们的 AI。Suno 表示,该公司已经“从开放的互联网上获取了几乎所有质量合理的音乐文件”,这“不是秘密”。但两家公司都表示,根据版权的合理使用原则,这种使用显然是合法的,该原则允许重新使用现有材料来创作新作品。
03 政策法规
欧盟《人工智能法案》正式生效
自 8 月 1 日起,欧盟《人工智能法案》正式生效。该法案是全球首部全面监管 AI 的法规,标志着欧盟在规范 AI 应用方面迈出重要一步。该法案规定,聊天机器人等 AI 系统必须明确告知用户他们在与机器互动,AI 技术提供商必须确保合成的音频、视频、文本和图像内容能够被检测为 AI 生成的内容。此外,该法案规定,禁止使用被认为对用户基本权利构成明显威胁的 AI 系统。对有违规行为的企业,欧盟最高将对其处以全球年营业额 7% 的罚款。
上海:支持 AI 技术赋能药物研发
日前,上海市发布关于支持生物医药产业全链条创新发展的若干意见,支持 AI 技术赋能药物研发。充分利用生成式 AI、深度学习等技术,聚焦新药靶点挖掘与验证、药物发现与设计、新型药物筛选、用药安全分析等环节,加快模型、算法、专业软件等攻关突破和共性平台建设,开展智能化场景应用示范。
深圳:鼓励打造全链路自研大模型技术体系
日前,深圳印发《深圳市加快打造人工智能先锋城市行动方案》。其中提出,加快核心技术全栈创新。加强基础研究和技术创新,重点围绕智能芯片、计算架构、模型测评、具身智能、类脑智能、智能传感器等关键领域前沿技术攻坚突破。探索推进芯片架构创新,持续优化大算力集群调度技术。鼓励开展深度学习框架、大模型架构及高效训练推理算法、大模型超级智能、超级对齐等技术创新,打造全链路自研大模型技术体系。持续学习借鉴国际主流算力生态,搭建国内外生态连接桥,实现 AI 软硬件深度协同。推动工具链技术创新,提升应用开发、云端和边缘侧算法部署效率。鼓励构建多模态多维度的大模型评测基准。
04 专家观点
Nature 刊文:“学术剽窃”定义正被 AI 模糊,我们该如何应对?
近日,科学记者 Diana Kwon 在 Nature 杂志上刊文讨论了生成式 AI 工具在学术写作中的应用及其带来的挑战和影响。她指出,ChatGPT 等生成式 AI 工具在节省时间、提高清晰度并减少语言障碍方面展现出了巨大的潜在价值,但同时也可能涉及剽窃和侵犯版权的问题。她还提到,AI 的使用在学术写作中已经爆炸性增长,尤其是在生物医学领域。然而,检测 AI 生成的文本存在困难,因为它们可以通过轻微编辑变得几乎无法检测。同时,AI 工具的合法与非法使用界限可能会进一步模糊,因为越来越多的应用程序和工具正在集成 AI 功能。(点击查看详情)
多名院士专家:中国发展 AI 不能靠“堆芯片”
近日,在由中国智能计算产业联盟与全国信标委算力标准工作组共同主办的 2024 中国算力发展专家研讨会上,多名院士专家就中国的 AI 发展给出了自己的观点。陈润生院士认为,未来智能计算还是应该参考“人类智能”,也就是模拟人脑的运行机制,一味地增加芯片,依靠增加系统的复杂度来解决大模型的存储问题是不完全可取的。
专家表示:AI 可能会让你的工作变得更糟
近日,历史学家 A.J. Schumann 和 IPS 不平等研究员 Omar Ocampo 刊文称,尽管有关 AI 将全面取代人类工作的恐慌广泛存在,但实际上 AI 的发展并未达到科技行业所宣称的高度。相反,AI 在工作场所的应用主要体现在增强监控,而非完全替代工作。他们认为,AI 不太可能完全取代大多数工作岗位,但它可能降低劳动力的价值并恶化工作条件。因此,我们需确保技术进步使工作变得更好,并通过教育、倡导和组织行动,确保新技术的实施惠及所有人,而不仅仅是少数特权者。
|点击关注我 ? 记得标星|
