
Published on August 2, 2024 6:39 PM GMT
Read the associated paper "Safetywashing: Do AI Safety Benchmarks
Actually Measure Safety Progress?": https://arxiv.org/abs/2407.21792
Focus on safety problems that aren’t solved with scale.
Benchmarks are crucial in ML to operationalize the properties we want models to have (knowledge, reasoning, ethics, calibration, truthfulness, etc.). They act as a criterion to judge the quality of models and drive implicit competition between researchers. “For better or worse, benchmarks shape a field.”
We performed the largest empirical meta-analysis to date of AI safety benchmarks on dozens of open language models. Around half of the benchmarks we examined had high correlation with upstream general capabilities.
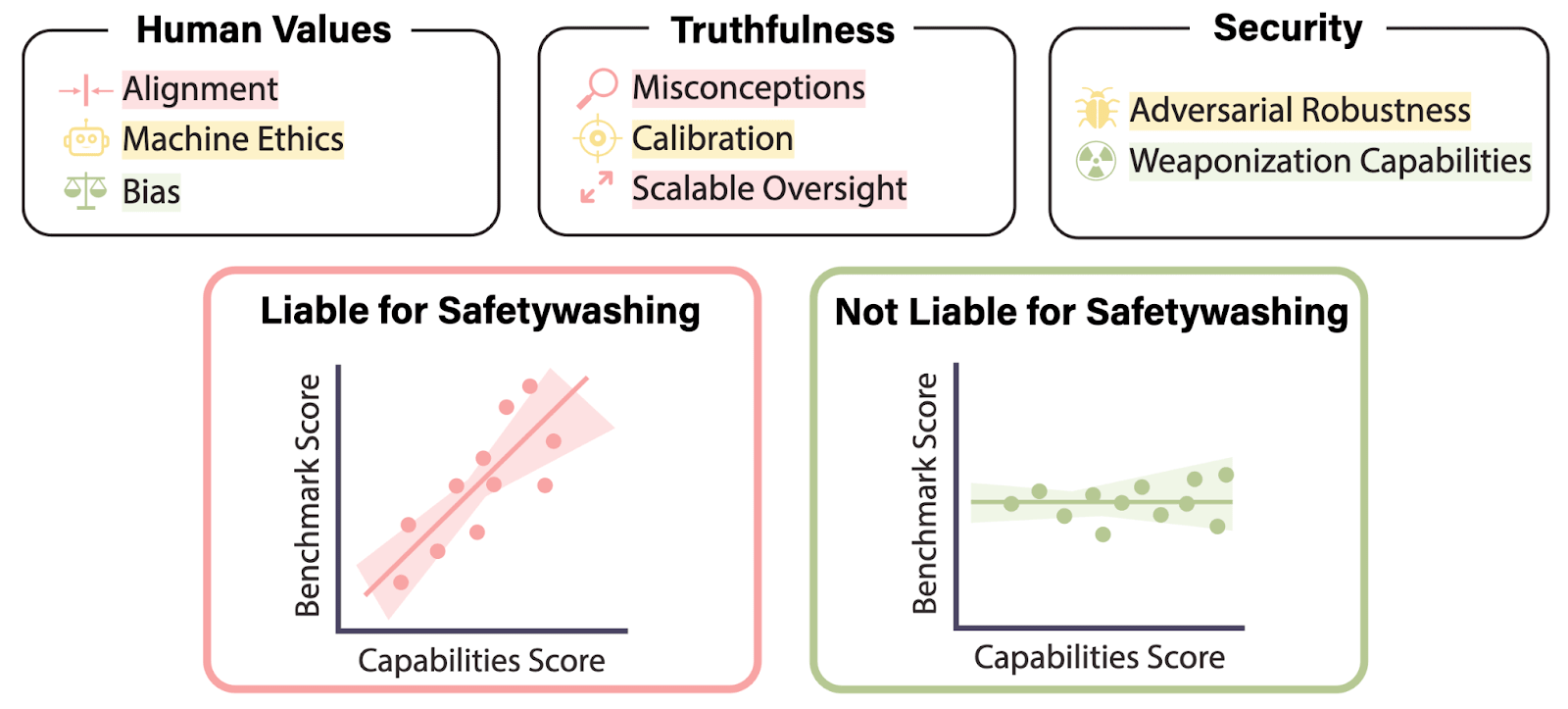
Some safety properties improve with scale, while others do not. For the models we tested, benchmarks on human preference alignment, scalable oversight (e.g., QuALITY), truthfulness (TruthfulQA MC1 and TruthfulQA Gen), and static adversarial robustness were highly correlated with upstream general capabilities. Bias, dynamic adversarial robustness, and calibration when not measured with Brier scores had relatively low correlations. Sycophancy and weaponization restriction (WMDP) had significant negative correlations with general capabilities.
Often, intuitive arguments from alignment theory are used to guide and prioritize deep learning research priorities. We find these arguments to be poorly predictive of these correlations and are ultimately counterproductive. In fact, in areas like adversarial robustness, some benchmarks basically measured upstream capabilities while others did not. We argue instead that empirical measurement is necessary to determine which safety properties will be naturally achieved by more capable systems, and which safety problems will remain persistent.[1] Abstract arguments from genuinely smart people may be highly “thoughtful,” but these arguments generally do not track deep learning phenomena, as deep learning is too often counterintuitive.
We provide several recommendations to the research community in light of our analysis:
- Measure capabilities correlations when proposing new safety evaluations.When creating safety benchmarks, aim to measure phenomena which are less correlated with capabilities. For example, if truthfulness entangles Q/A accuracy, honesty, and calibration – then just make a decorrelated benchmark that measures honesty or calibration.In anticipation of capabilities progress, work on safety problems that are disentangled with capabilities and thus will likely persist in future models (e.g., GPT-5). The ideal is to find training techniques that cause as many safety properties as possible to be entangled with capabilities.
Ultimately, safety researchers should prioritize differential safety progress, and should attempt to develop a science of benchmarking that can effectively identify the most important research problems to improve safety relative to the default capabilities trajectory.
We’re not claiming that safety properties and upstream general capabilities are orthogonal. Some are, some aren’t. Safety properties are not a monolith. Weaponization risks increase as upstream general capabilities increase. Jailbreaking robustness isn’t strongly correlated with upstream general capabilities. However, if we can isolate less-correlated safety properties in AI systems which are distinct from greater intelligence, these are the research problems safety researchers should most aggressively pursue and allocate resources toward. The other model properties can be left to capabilities researchers. This amounts to a “Bitter Lesson” argument for working on safety issues which are relatively uncorrelated (or negatively correlated) with capabilities: safety issues which are highly correlated with capabilities will shrink in importance as capabilities inevitably improve.
We should be deeply dissatisfied with the current intellectual dysfunction in how we conceptualize the relationship between safety and capabilities. It’s important to get this right because there may be a small compute budget for safety during an intelligence explosion/automated AI R&D, and it’s important not to blow that budget on goals that are roughly equivalent to maximizing intelligence. We need a systematic, scientific way of identifying the research areas which will differentially contribute to safety, which we attempt to do in this paper. Researchers possibly need to converge on the right guidelines quickly. Without clear intellectual standards, random social accidents (e.g., what a random popular person supports, what a random grantmaker is “excited about,” etc.) will determine priorities.
Clarifications:
Alignment theory.
When we mention “alignment theory,” we specifically mean the subset of abstract top-down intuitive arguments meant to specifically guide and prioritize deep learning research while making claims about empirical phenomena. We’re not talking about broader philosophical concepts and speculation, which can be useful for horizon-scanning. Early conceptual work on alignment successfully netted the useful notion of corrigibility, for example. Rather, we argue it is counterproductive to use abstract top-down verbal arguments with multiple deductive steps to make claims about deep learning phenomena and their relation to safety, such as “we don’t need to worry about adversarial robustness being difficult because ⟨intuitive arguments⟩.”
Diagnostic vs hill-climbing benchmarks.
Benchmarks created by the safety community can have several purposes. We acknowledge the importance of “diagnostic” benchmarks which measure whether certain capabilities thresholds have been reached; such benchmarks are not the focus of our analysis. Instead, we focus on benchmarks which researchers attempt to optimize, so-called “hill-climbing” benchmarks.
For more information about our method, detailed results, and what we believe amounts to a great introduction to AI Safety benchmarking, read the full paper here: https://arxiv.org/abs/2407.21792
- ^
This does not mean that empirical capabilities correlations will stay the same as capabilities improve. Truthfulness (e.g. TruthfulQA MC1), for example, appeared to be less correlated with scale for weaker models, but is more so now. A reasonable prediction is that we will observe the same for sycophancy. Similarly, high correlations for benchmarks that attempt to operationalize a safety property of concern might simply fail to robustly capture the property and how it might diverge from capabilities. Nonetheless, we claim that capabilities correlations should be the starting point when trying to determine which safety properties will be achieved by more capable systems.
Discuss
