


The prospects and scope for automation in digital lives are expanding with the advances in instruction following, coding, and tool-use abilities of large language models (LLMs). Most day-to-day digital tasks involve complex activities across various applications, with reasoning and decision-making based on intermediate results. However, the responsive development of such autonomous agents needs rigorous, reproducible, and strong evaluation using realistic tasks that account for the complexities and dynamics of real digital environments. The current benchmarks for tool-based solutions cannot solve this challenge as they use a linear sequence of API calls without rich or interactive coding, and their evaluations through reference solutions are not suitable for complex tasks with varied solutions.
The current benchmarks discussed in this paper are Tool-Usage Benchmarks (TUB) and Interactive Code Generation Benchmarks (ICGB). TUB either does not provide agents with executable tools or uses existing public APIs, with some offering implementations of simple ones. Current evaluation methods depend on LLMs or human judgment, which are unsuitable for tasks with multiple valid solutions. ICGB evaluates the ability of agents to generate executable code, such as HumanEval targeting short code snippets and SWEBench focusing on patch file generation. Intercode proposes solving coding tasks interactively by observing code execution outputs, while MINT allows agents to use a Python interpreter for reasoning and decision-making.
Researchers from Stony Brook University, Allen Institute for AI, and Saarland University have proposed the AppWorld Engine, a high-quality execution environment comprising 60K lines of code. This environment includes 9 day-to-day apps operable through 457 APIs and simulates realistic digital activities for approximately 100 fictitious users. An AppWorld Benchmark, a collection of 750 diverse and complex tasks for autonomous agents, is developed that requires rich and interactive code generation. It enables robust programmatic evaluation with state-based unit tests, allowing for different task completion methods and checking for unexpected changes.
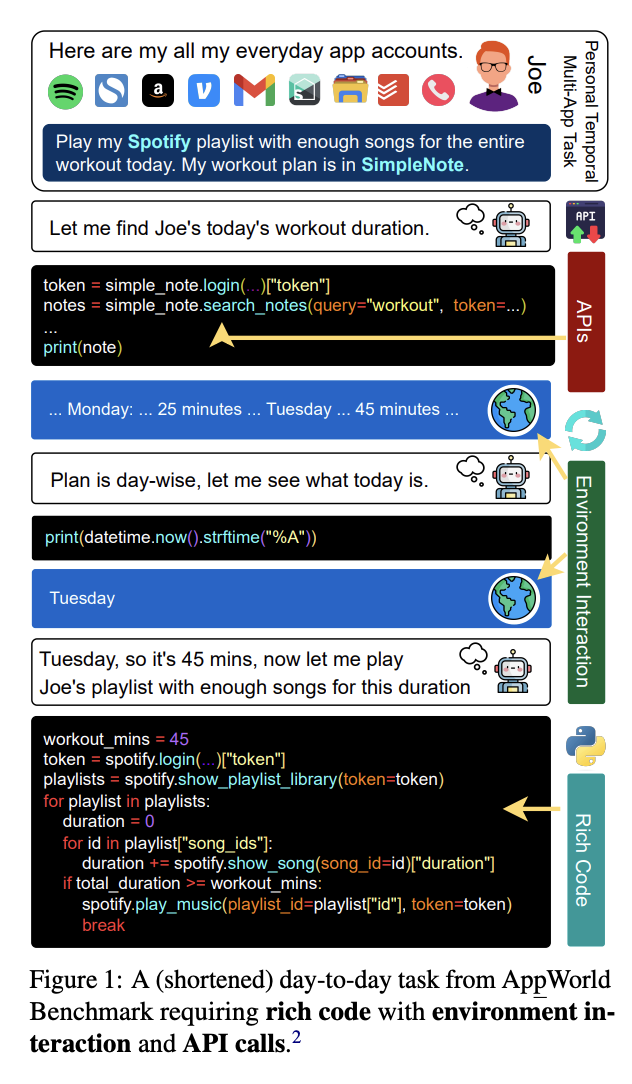
The AppWorld Engine implements 9 applications across various domains, including emails (Gmail), money transfer (Venmo), shopping (Amazon), and local file systems. It features 457 APIs that closely resemble real app functionalities, averaging 50 APIs per app, and contains 1470 arguments. These APIs perform actions through read/write operations on a database, e.g. a send email API creates new entries in the email and email thread tables for both sender and recipient(s). Moreover, two supporting apps, ApiDocs and Supervisor, are implemented. ApiDocs provides APIs for interactive documentation, while Supervisor APIs provide information about the task assigner, such as addresses, payment cards, and account passwords.
The results show that all methods produce low task (TGC) and scenario (SGC) completion scores in both Test-N and Test-C. The strongest model, ReAct + GPT4O, achieves a TGC of 48.8 on Test-N, which decreases to 30.2 on Test-C. The 30-50% reduction from task to scenario scores shows that models do not consistently complete all task variants within the same scenario. The second-best model, GPT4Trb, falls significantly behind GPT4O, with open models performing even worse. GPT4Trb achieves a TGC of 32.7 and 17.5, while the best open LLM, FullCodeRefl + LLaMA3, gets a TGC of 24.4 on Test-N and 7.0 on Test-C. CodeAct and ToolLLaMA failed on all tasks due to their specialized narrow-domain training.

In summary, researchers have introduced the AppWorld Engine, a robust execution environment consisting of 60K lines of code. The AppWorld framework provides a consistent execution environment and a benchmark for interactive API-based tasks. Its programmatic evaluation suite and realistic challenges ensure thorough assessment. Benchmarking state-of-the-art models highlights the difficulty of AppWorld and the challenges that LLMs encounter in automating tasks. The system’s modularity and extensibility create opportunities for user interface control, coordination among multiple agents, and the examination of privacy and safety issues in digital assistants.
Check out the Paper, GitHub, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post AppWorld: An AI Framework for Consistent Execution Environment and Benchmark for Interactive Coding for API-Based Tasks appeared first on MarkTechPost.
