


Large language models (LLMs) have seen rapid advancements, making significant strides in algorithmic problem-solving tasks. These models are being integrated into algorithms to serve as general-purpose solvers, enhancing their performance and efficiency. This integration combines traditional algorithmic approaches with the advanced capabilities of LLMs, paving the way for innovative solutions to complex problems.
The primary issue addressed in the paper is the need for formal analysis and structured design principles for LLM-based algorithms. Despite their empirical success, the development of these algorithms has largely relied on heuristics and trial-and-error methods. This approach is inefficient and lacks a theoretical foundation, making it difficult to optimize and accurately predict the performance of LLM-based algorithms.
Existing methods for integrating LLMs into algorithms typically involve using LLM calls and prompt engineering. Advanced examples include LLM-powered agent systems and compound AI systems that leverage LLMs alongside traditional algorithms to perform complex tasks. However, these methods need a formal analytical framework, which is crucial for understanding their behavior and improving their design.
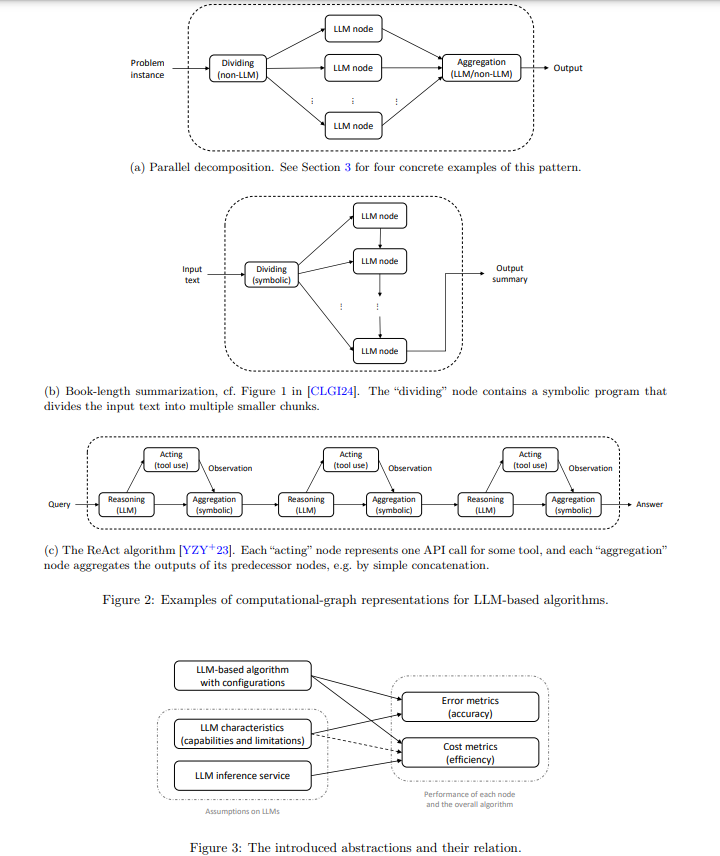
Researchers at Alibaba Group have introduced a formal framework for designing and analyzing LLM-based algorithms. This framework employs computational graphs to represent algorithms, identifying key abstractions and principles such as task decomposition. The structured approach provides theoretical insights into the accuracy and efficiency of LLM-based algorithms, addressing the black-box nature of LLMs and offering a systematic way to understand their behavior.
The proposed framework details how algorithms can be decomposed into sub-tasks, each handled by an LLM or non-LLM node. This computational graph approach allows for formal analysis, helping to predict performance, optimize hyperparameters, and guide new algorithm designs. Researchers introduced four concrete examples to validate the framework: counting, sorting, retrieval, and retrieval-augmented generation (RAG). These examples demonstrate the framework’s capability to explain empirical phenomena, guide parameter choices, and inspire future work in LLM-based algorithm design.
In-depth methodology explores the design and analysis of LLM-based algorithms using computational graphs. Each algorithm is represented as a graph with nodes representing LLM calls or traditional algorithmic steps. Task decomposition is a key principle, breaking down complex tasks into manageable sub-tasks that LLMs or non-LLM programs can efficiently handle. This approach ensures that each sub-task is optimized for accuracy and efficiency, facilitating a comprehensive analysis of the overall algorithm’s performance. The researchers also introduced abstractions to quantify error and cost metrics, enabling a detailed analysis of each algorithm’s performance. These abstractions help understand the trade-offs between different design choices and optimize the algorithm for specific tasks.
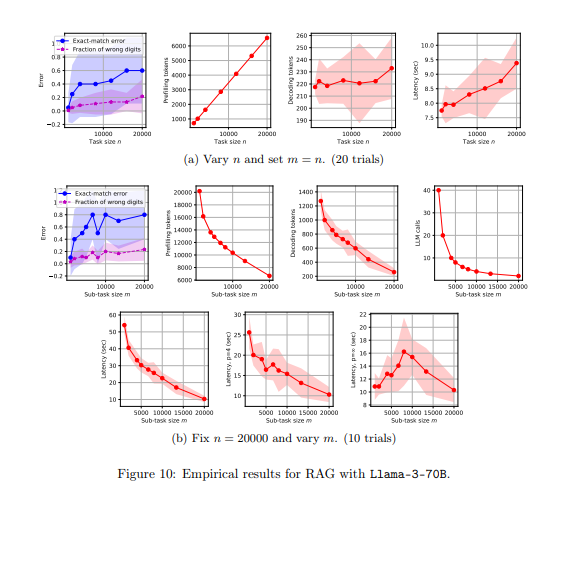
The proposed framework by the researchers demonstrated substantial performance improvements in various tasks. In the counting task, the algorithm achieved an error rate of less than 0.5% when counting digits in strings of up to 1,000 characters. In the sorting task, the algorithm efficiently sorted lists of up to 200 elements with a mean latency of 0.2 seconds and a length-mismatch error below 2%. For the retrieval task, the algorithm retrieved relevant information from text corpora of up to 10,000 tokens with an accuracy rate of 95%. The retrieval-augmented generation task showed that the framework could effectively combine retrieval and generation processes, maintaining a generation accuracy of 93% while reducing the overall latency by 30%. These results underscore the framework’s ability to enhance the accuracy and efficiency of LLM-based algorithms in various applications.
In conclusion, the researchers address the critical need for formal design and analysis principles in developing LLM-based algorithms. By introducing a structured framework and validating it through various examples, the research team from Alibaba Group provides valuable tools for advancing the field. The proposed methodology offers theoretical insights and practical guidelines for optimizing LLM-based algorithms. This work significantly contributes to the understanding and improving LLM-based algorithms, paving the way for more efficient and accurate solutions to complex problems in various fields.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post This AI Paper from Alibaba Introduces a Formal Machine Learning Framework for Studying the Design and Analysis of LLM-based Algorithms appeared first on MarkTechPost.
