


Relational databases are integral to many digital systems, providing structured data storage across various sectors, such as e-commerce, healthcare, and social media. Their table-based structure simplifies maintenance and data access via powerful query languages like SQL, making them crucial for data management. These databases underpin significant portions of the digital economy, efficiently organizing and retrieving data necessary for operations in diverse fields. However, the richness of relational information in these databases is often underutilized due to the complexity of handling multiple interconnected tables.
A major challenge in utilizing relational databases is extracting predictive signals embedded in the intricate relationships between tables. Traditional methods often flatten relational data into simpler formats, typically a single table. While simplifying data structure, this process leads to a substantial loss of predictive information and necessitates the creation of complex data extraction pipelines. These pipelines are prone to errors, increase software complexity, and require significant manual effort. Consequently, there is a pressing need for methods to exploit data’s relational nature without oversimplification fully.
Existing methods for managing relational data largely rely on manual feature engineering. In this approach, data scientists painstakingly transform raw data into formats suitable for ML models. This process is labor-intensive and often results in inconsistencies and errors. Manual feature engineering also limits the scalability of predictive models, as each new task or dataset requires substantial rework. Despite being the current gold standard, this method is inefficient and cannot fully leverage the predictive power inherent in relational databases.
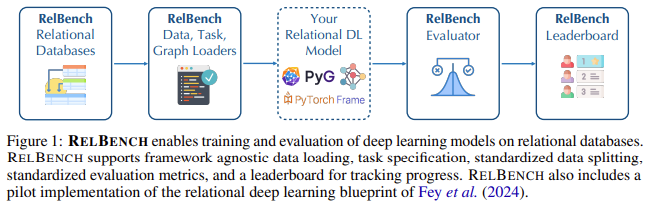
Researchers from Stanford University, Kumo.AI, and the Max Planck Institute for Informatics introduced RelBench, a groundbreaking benchmark to facilitate deep learning on relational databases. This initiative aims to standardize the evaluation of deep learning models across diverse domains and scales. RelBench provides a comprehensive infrastructure for developing and testing relational deep learning (RDL) methods, enabling researchers to compare their models against consistent benchmarks.
RelBench leverages a novel approach by converting relational databases into graph representations, enabling the use of Graph Neural Networks (GNNs) for predictive tasks. This conversion involves creating a heterogeneous temporal graph where nodes represent entities and edges denote relationships. Initial node features are extracted using deep tabular models designed to handle diverse column types such as numerical, categorical, and text data. The GNN then iteratively updates these node embeddings based on their neighbors, facilitating the extraction of complex relational patterns.
Researchers compared their RDL approach to traditional manual feature engineering methods across various predictive tasks. The results were compelling: RDL models consistently outperformed or matched the accuracy of manually engineered models while drastically reducing the required human effort and lines of code by over 90%. For instance, in entity classification tasks, RDL achieved AUROC scores of 70.45% and 82.39% for user churn and item churn, respectively, significantly surpassing the traditional LightGBM classifier.
In entity regression tasks, RDL models demonstrated superior performance. For example, the Mean Absolute Error (MAE) for user lifetime value predictions was reduced by over 14%, showcasing the precision and efficiency of RDL models. In recommendation tasks, RDL models achieved remarkable improvements, with Mean Average Precision (MAP) scores increasing by over 300% in some cases. These results underscore the potential to automate and enhance predictive tasks on relational databases, opening new avenues for research and application.

In conclusion, the introduction of RelBench provides a standardized benchmark and comprehensive infrastructure, enabling researchers to powerfully exploit relational databases’ predictive power. This benchmark improves prediction accuracy and significantly reduces the manual effort required, making it a transformative tool for the field. With RelBench, researchers have developed more efficient and scalable deep learning solutions for complex multi-tabular datasets.
Check out the Paper, GitHub, and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post Researchers at Stanford Present RelBench: An Open Benchmark for Deep Learning on Relational Databases appeared first on MarkTechPost.
