


Zyphra’s release of Zamba2-2.7B marks a pivotal moment in developing small language models, demonstrating a significant advancement in efficiency and performance. The model is trained on a substantial enough dataset of approximately 3 trillion tokens derived from Zyphra’s proprietary datasets, which allows it to match the performance of larger models like Zamba1-7B and other leading 7B models. This feat is achieved while notably reducing the resource requirements for inference, making it a highly efficient solution for on-device applications.
The model achieves a twofold improvement in time-to-first-token, a critical metric for applications requiring real-time interaction. This improvement means that Zamba2-2.7B can generate initial responses twice as fast as its competitors. This is crucial for applications such as virtual assistants, chatbots, and other responsive AI systems where quick response times are essential.
In addition to its speed, Zamba2-2.7B is designed to use memory more efficiently. It reduces memory overhead by 27%, making it a suitable option for deployment on devices with limited memory resources. This smarter memory usage ensures the model can operate effectively even in environments with constrained computational resources, broadening its applicability across various devices and platforms.
Another key advantage of Zamba2-2.7B is its lower generation latency. The model delivers 1.29 times lower latency compared to Phi3-3.8B, which enhances the smoothness and continuity of interactions. Lower latency is particularly important in applications that require seamless and uninterrupted communication, such as customer service bots and interactive educational tools. Maintaining high performance with reduced latency positions Zamba2-2.7B as a leading choice for developers looking to enhance user experience in their AI-driven applications.
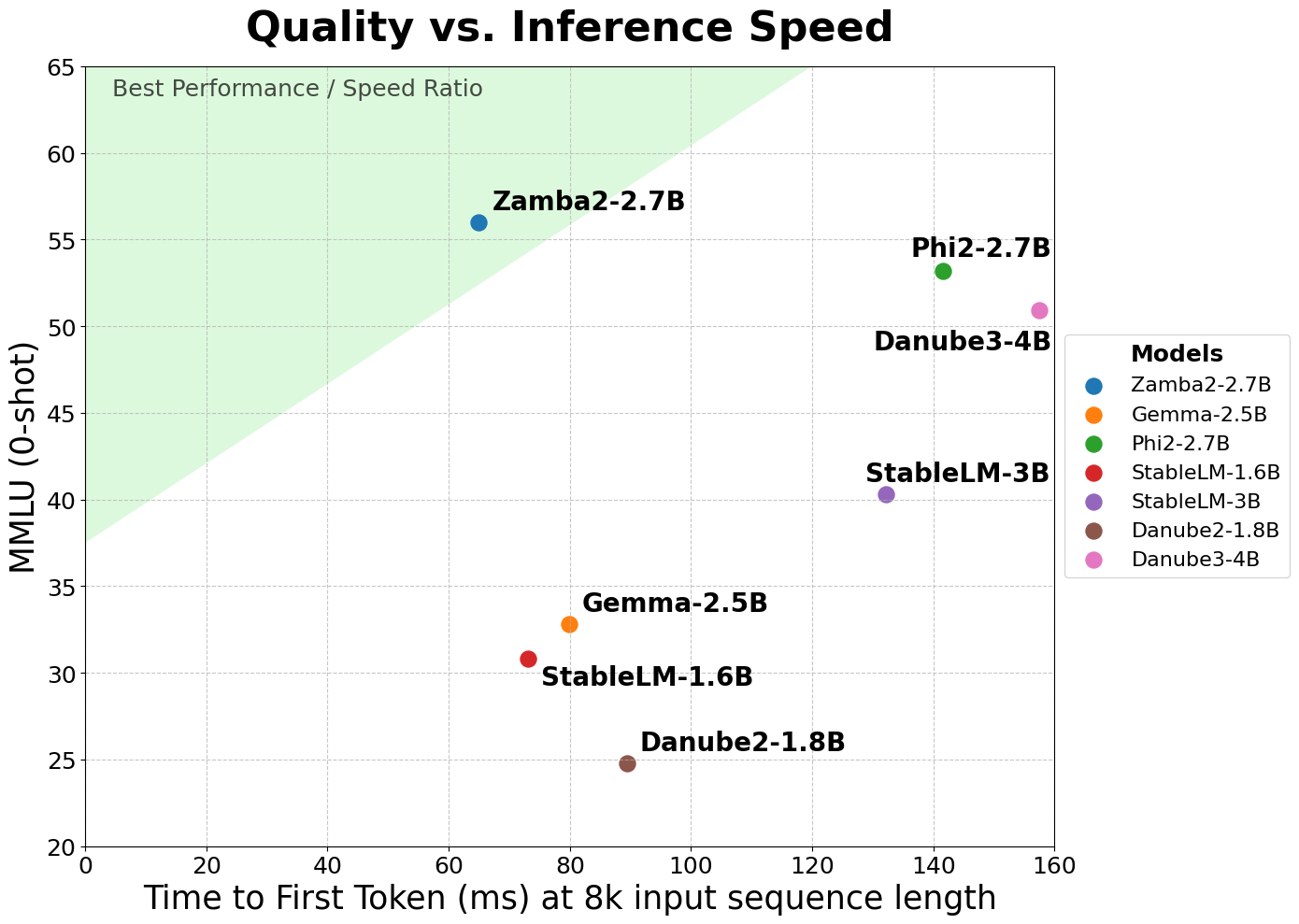
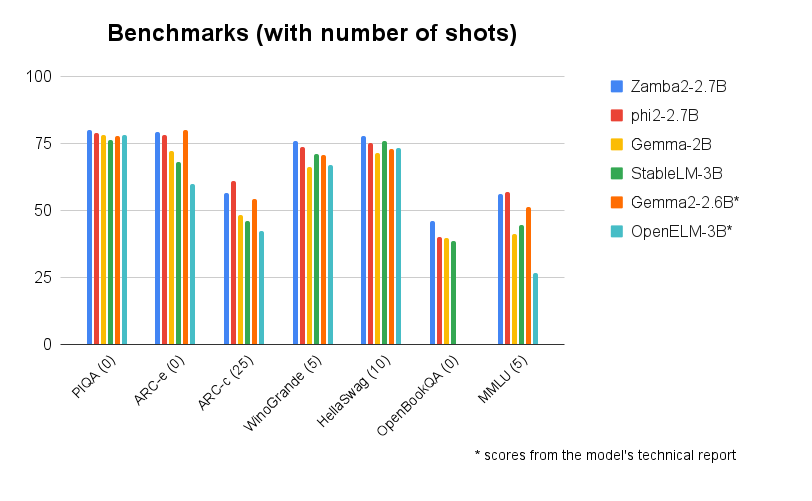
Benchmark comparisons underscore the superior performance of Zamba2-2.7B. When benchmarked against other models of similar scale, including Gemma2-2.7B, StableLM-3B, and Phi2-2.7B, Zamba2-2.7B consistently outperforms its peers. This superior performance is a testament to Zyphra’s innovative approach & dedication to advancing AI technology. The company’s commitment to what small language models can achieve is evident in the impressive capabilities of Zamba2-2.7B.
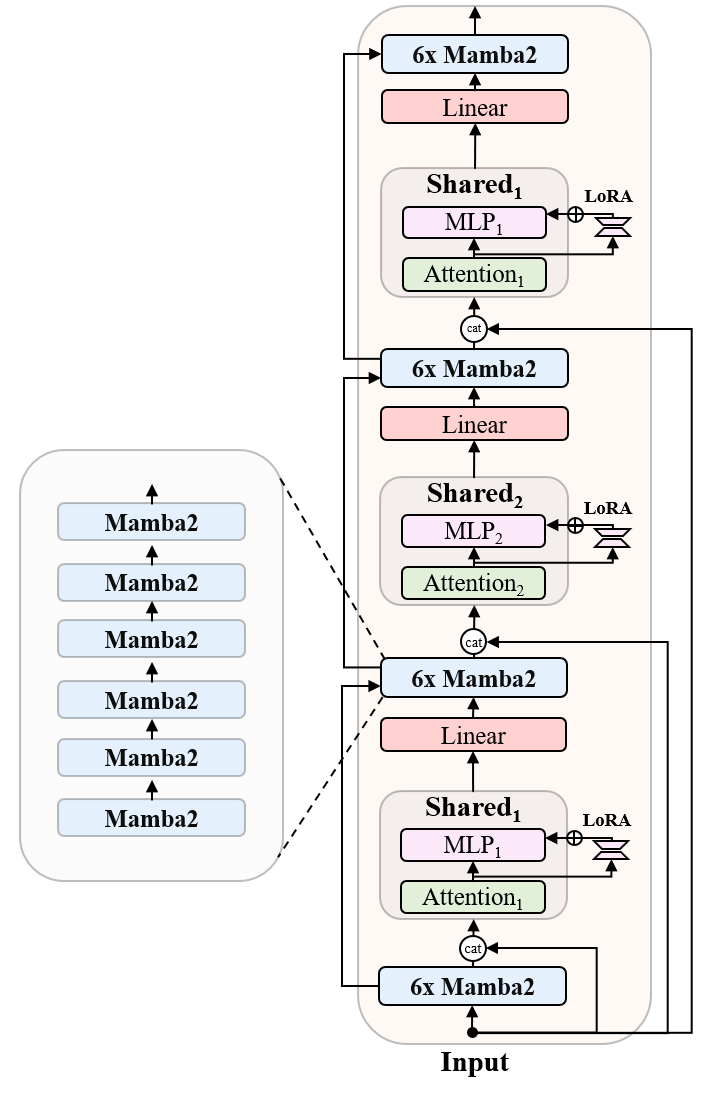
The model utilizes an improved interleaved shared attention scheme with LoRA projectors on shared MLP blocks. This advanced architecture allows the model to handle complex tasks more efficiently, ensuring high-quality outputs with minimal delays. The upgrade from Mamba1 blocks to Mamba2 blocks further enhances the model’s performance, providing a solid foundation for its advanced capabilities. These innovations contribute to the model’s ability to deliver faster, smarter, and more efficient AI solutions.
Zyphra’s release of Zamba2-2.7B signifies a major milestone in the evolution of small language models. Combining high performance with reduced latency and efficient memory usage, Zamba2-2.7B sets a new standard for on-device AI applications. The model meets and exceeds the expectations for small language models, offering a robust solution for developers and businesses looking to integrate sophisticated AI capabilities into their products.
In conclusion, Zyphra’s launch of Zamba2-2.7B marks a new era in AI technology where efficiency and performance are seamlessly integrated. This model’s ability to deliver faster, smarter, and more efficient AI solutions makes it a valuable asset for a wide range of on-device applications, paving the way for more advanced and responsive AI-driven experiences.
Check out the Details and Model. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post Zamba2-2.7B Released: A State-of-the-Art Small Language Model Achieving Twice the Speed and 27% Reduced Memory Overhead appeared first on MarkTechPost.
