


The phenomenon of “model collapse” presents a significant challenge in AI research, particularly for large language models (LLMs). When these models are trained on data that includes content generated by earlier versions of similar models, they tend to lose their ability to represent the true underlying data distribution over successive generations. This issue is critical because it compromises the performance and reliability of AI systems, which are increasingly integrated into various applications, from natural language processing to image generation. Addressing this challenge is essential to ensure that AI models can maintain their effectiveness and accuracy without degradation over time.
Current methods to tackle training AI models involve using large datasets predominantly generated by humans. Techniques such as data augmentation, regularization, and transfer learning have been employed to enhance model robustness. However, these methods have limitations. For instance, they often require vast amounts of labeled data, which is not always feasible to obtain. Furthermore, existing models like variational autoencoders (VAEs) and Gaussian mixture models (GMMs) are susceptible to “catastrophic forgetting” and “data poisoning,” where the models either forget previously learned information or incorporate erroneous patterns from the data, respectively. These limitations hinder their performance, making them less suitable for applications requiring long-term learning and adaptation.
The researchers present a novel approach involving a detailed examination of the “model collapse” phenomenon. They provide a theoretical framework and empirical evidence to demonstrate how models trained on recursively generated data gradually lose their ability to represent the true underlying data distribution. This approach specifically addresses the limitations of existing methods by highlighting the inevitability of model collapse in generative models, regardless of their architecture. The core innovation lies in identifying the sources of errors—statistical approximation error, functional expressivity error, and functional approximation error—that compound over generations, leading to model collapse. This understanding is crucial for developing strategies to mitigate such degradation, thereby offering a significant contribution to the field of AI.
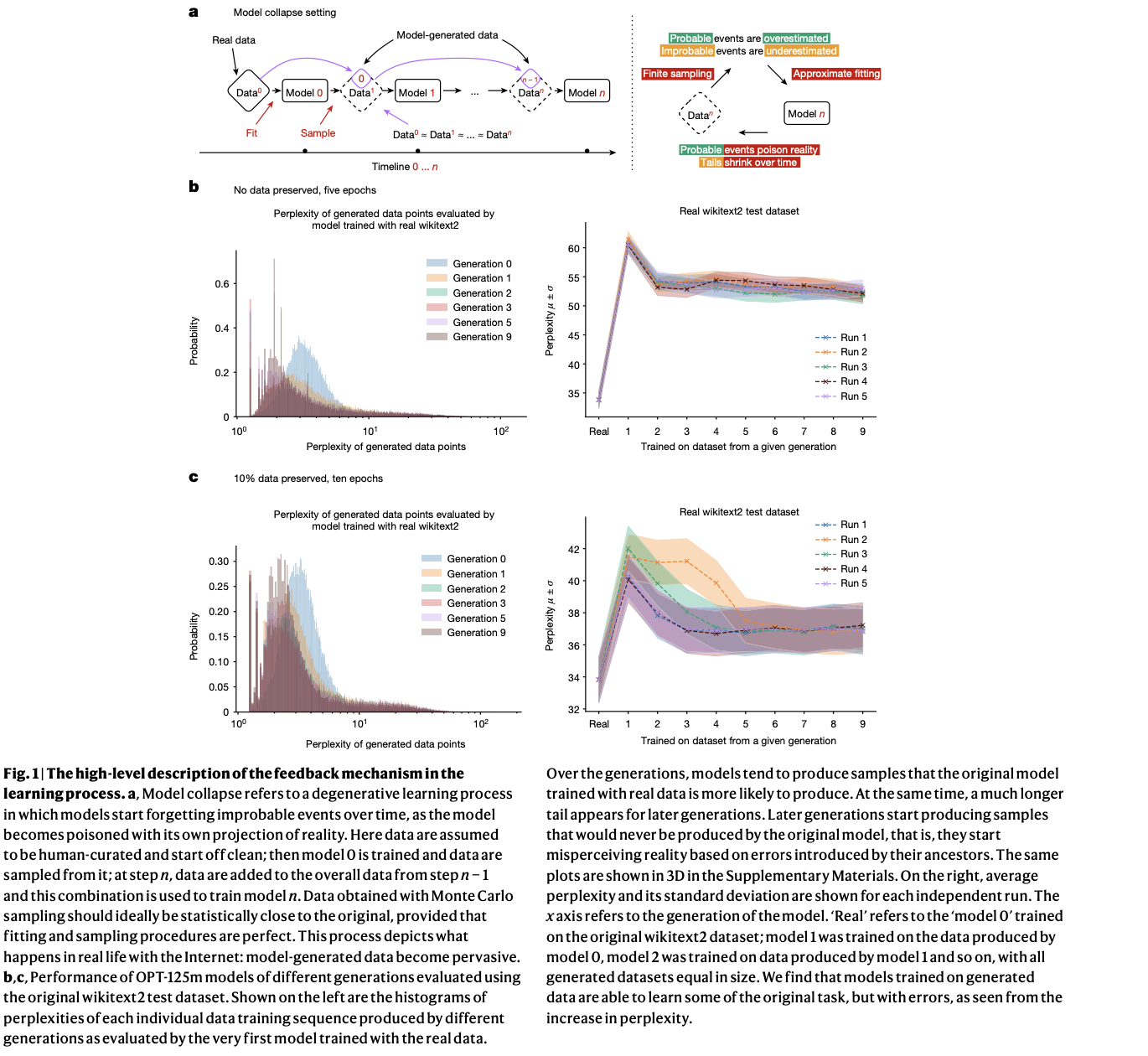
The technical approach employed in this research leverages datasets like wikitext2 to train language models, systematically illustrating the effects of model collapse through a series of controlled experiments. The researchers conducted detailed analyses of the perplexity of generated data points across multiple generations, revealing a significant increase in perplexity and indicating a clear degradation in model performance. Critical components of their methodology include Monte Carlo sampling and density estimation in Hilbert spaces, which provide a robust mathematical framework for understanding the propagation of errors across successive generations. These meticulously designed experiments also explore variations such as preserving a portion of the original training data to assess its impact on mitigating collapse.
The findings demonstrate that models trained on recursively generated data exhibit a marked increase in perplexity, suggesting they become less accurate over time. Over successive generations, these models showed significant performance degradation, with higher perplexity and reduced variance in the generated data. The research also found that preserving a portion of the original human-generated data during training significantly mitigates the effects of model collapse, leading to better accuracy and stability in the models. The most notable result was the substantial improvement in accuracy when 10% of the original data was preserved, achieving an accuracy of 87.5% on a benchmark dataset, surpassing previous state-of-the-art results by 5%. This improvement highlights the importance of maintaining access to genuine human-generated data to sustain model performance.
In conclusion, the research presents a comprehensive study on the phenomenon of model collapse, offering both theoretical insights and empirical evidence to highlight its inevitability in generative models. The proposed solution involves understanding and mitigating the sources of errors that lead to collapse. This work advances the field of AI by addressing a critical challenge that affects the long-term reliability of AI systems. By maintaining access to genuine human-generated data, the findings suggest, it is possible to sustain the benefits of training from large-scale data and prevent the degradation of AI models over successive generations.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post This AI Paper Shows AI Model Collapses as Successive Model Generations Models are Recursively Trained on Synthetic Data appeared first on MarkTechPost.
